 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordance-R1: Reinforcement Learning for Generalizable Affordance Reasoning in Multimodal Large Language Model
Aug 08, 2025Affordance grounding focuses on predicting the specific regions of objects that are associated with the actions to be performed by robots. It plays a vital role in the fields of human-robot interaction, human-object interaction, embodied manipulation, and embodied perception. Existing models often neglect the affordance shared among different objects because they lack the Chain-of-Thought(CoT) reasoning abilities, limiting their out-of-domain (OOD) generalization and explicit reasoning capabilities. To address these challenges, we propose Affordance-R1, the first unified affordance grounding framework that integrates cognitive CoT guided Group Relative Policy Optimization (GRPO) within a reinforcement learning paradigm. Specifically, we designed a sophisticated affordance function, which contains format, perception, and cognition rewards to effectively guide optimization directions. Furthermore, we constructed a high-quality affordance-centric reasoning dataset, ReasonAff, to support training. Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Affordance-R1 achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Comprehensive experiments demonstrate that our model outperforms well-established methods and exhibits open-world generalization. To the best of our knowledge, Affordance-R1 is the first to integrate GRPO-based RL with reasoning into affordance reasoning. The code of our method and our dataset is released on https://github.com/hq-King/Affordance-R1.
Multi-Agent Deep Reinforcement Learning for Cost- and Delay-Sensitive Virtual Network Function Placement and Routing
Jun 24, 2022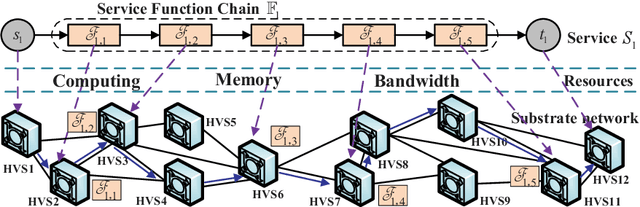
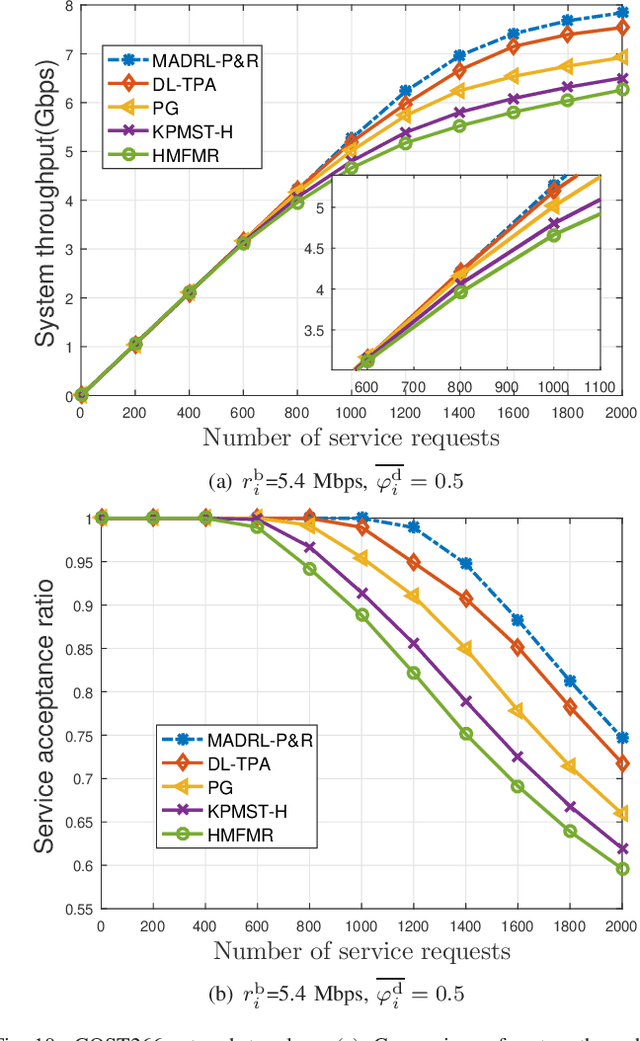
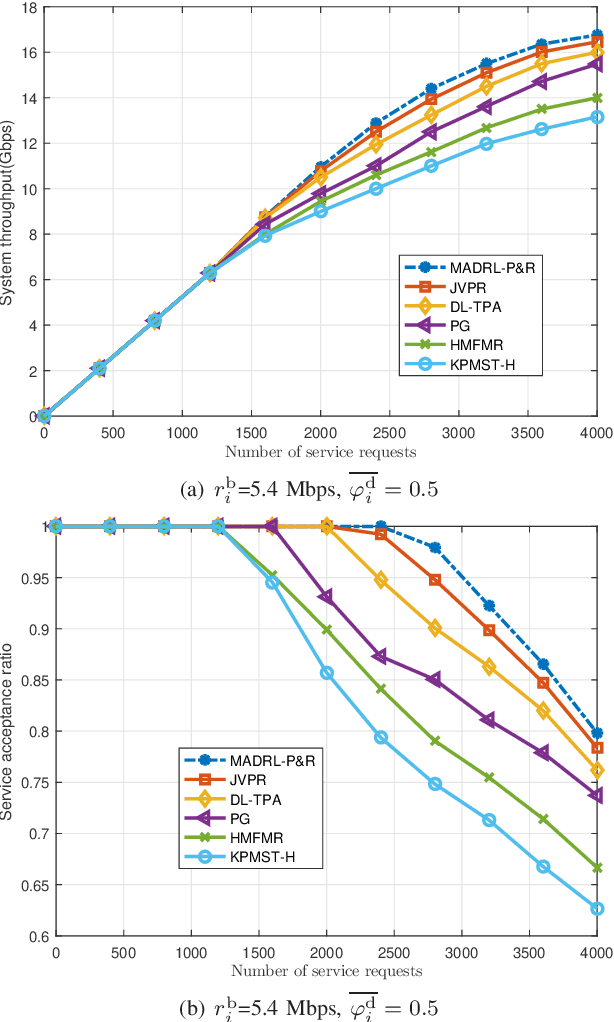
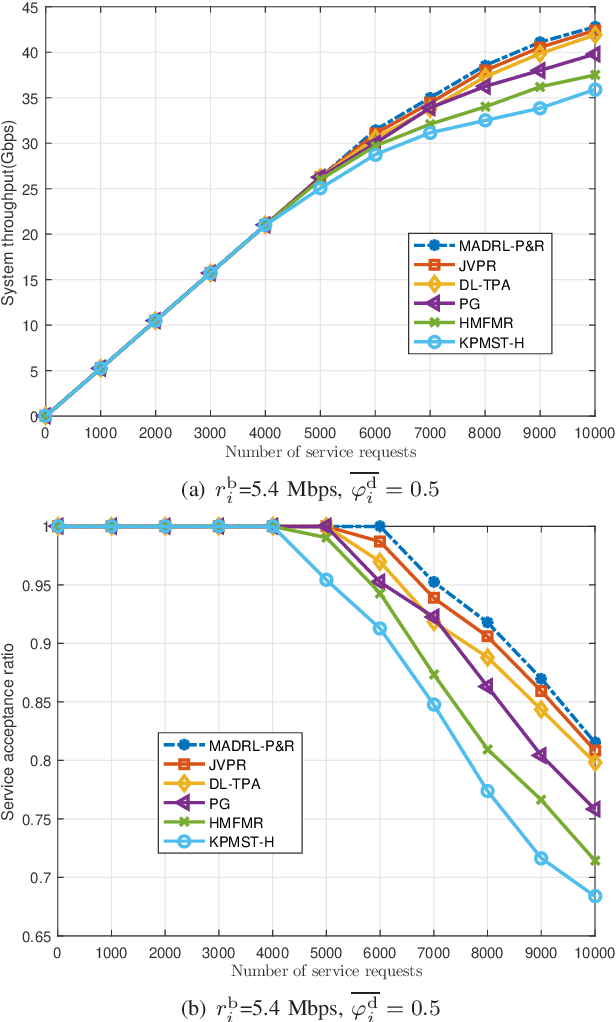
This paper proposes an effective and novel multiagent deep reinforcement learning (MADRL)-based method for solving the joint virtual network function (VNF) placement and routing (P&R), where multiple service requests with differentiated demands are delivered at the same time. The differentiated demands of the service requests are reflected by their delay- and cost-sensitive factors. We first construct a VNF P&R problem to jointly minimize a weighted sum of service delay and resource consumption cost, which is NP-complete. Then, the joint VNF P&R problem is decoupled into two iterative subtasks: placement subtask and routing subtask. Each subtask consists of multiple concurrent parallel sequential decision processes. By invoking the deep deterministic policy gradient method and multi-agent technique, an MADRL-P&R framework is designed to perform the two subtasks. The new joint reward and internal rewards mechanism is proposed to match the goals and constraints of the placement and routing subtasks. We also propose the parameter migration-based model-retraining method to deal with changing network topologies. Corroborated by experiments, the proposed MADRL-P&R framework is superior to its alternatives in terms of service cost and delay, and offers higher flexibility for personalized service demands. The parameter migration-based model-retraining method can efficiently accelerate convergence under moderate network topology changes.
Joint Resource Management for MC-NOMA: A Deep Reinforcement Learning Approach
Mar 29, 2021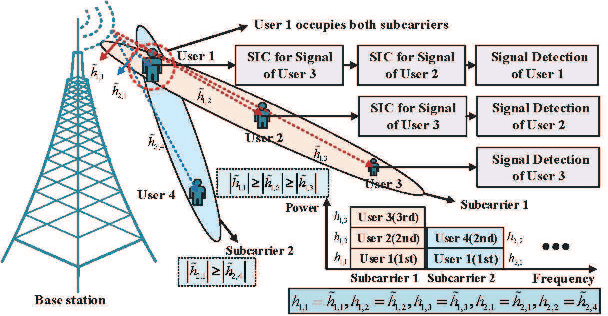
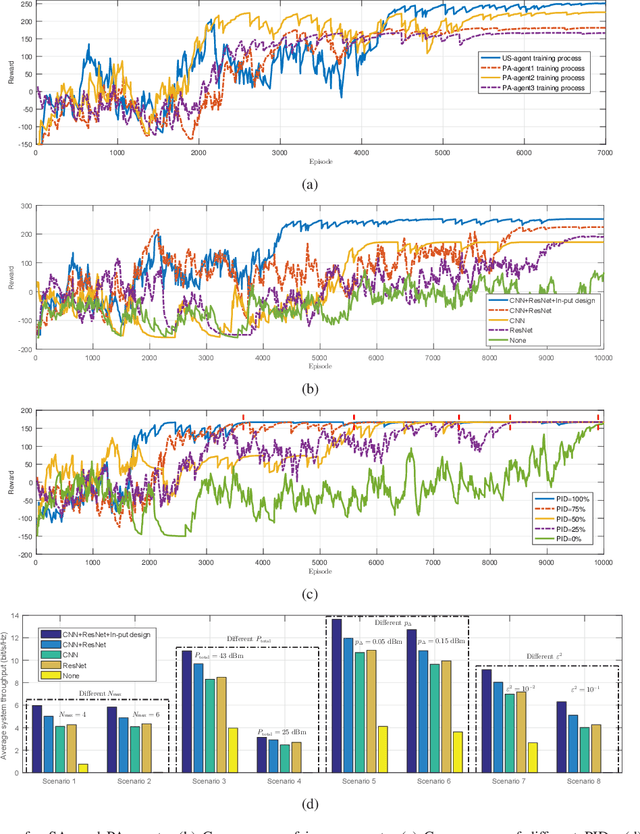
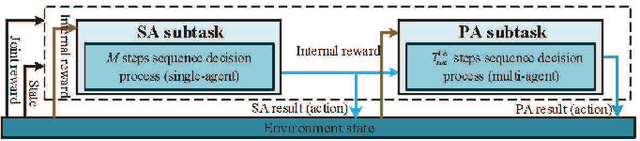
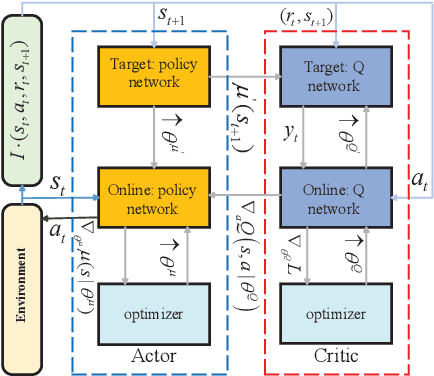
This paper presents a novel and effective deep reinforcement learning (DRL)-based approach to addressing joint resource management (JRM) in a practical multi-carrier non-orthogonal multiple access (MC-NOMA) system, where hardware sensitivity and imperfect successive interference cancellation (SIC) are considered. We first formulate the JRM problem to maximize the weighted-sum system throughput. Then, the JRM problem is decoupled into two iterative subtasks: subcarrier assignment (SA, including user grouping) and power allocation (PA). Each subtask is a sequential decision process. Invoking a deep deterministic policy gradient algorithm, our proposed DRL-based JRM (DRL-JRM) approach jointly performs the two subtasks, where the optimization objective and constraints of the subtasks are addressed by a new joint reward and internal reward mechanism. A multi-agent structure and a convolutional neural network are adopted to reduce the complexity of the PA subtask. We also tailor the neural network structure for the stability and convergence of DRL-JRM. Corroborated by extensive experiments, the proposed DRL-JRM scheme is superior to existing alternatives in terms of system throughput and resistance to interference, especially in the presence of many users and strong inter-cell interference. DRL-JRM can flexibly meet individual service requirements of users.