 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder with Learned Latent Structure
Jun 18, 2020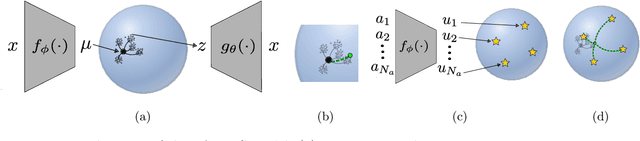


The manifold hypothesis states that high-dimensional data can be modeled as lying on or near a low-dimensional, nonlinear manifold. Variational Autoencoders (VAEs) approximate this manifold by learning mappings from low-dimensional latent vectors to high-dimensional data while encouraging a global structure in the latent space through the use of a specified prior distribution. When this prior does not match the structure of the true data manifold, it can lead to a less accurate model of the data. To resolve this mismatch, we introduce the Variational Autoencoder with Learned Latent Structure (VAELLS) which incorporates a learnable manifold model into the latent space of a VAE. This enables us to learn the nonlinear manifold structure from the data and use that structure to define a prior in the latent space. The integration of a latent manifold model not only ensures that our prior is well-matched to the data, but also allows us to define generative transformation paths in the latent space and describe class manifolds by transformations stemming from examples of each class. We validate our model on examples with known latent structure and also demonstrate its capabilities on a real-world dataset.
Active embedding search via noisy paired comparisons
May 24, 2019
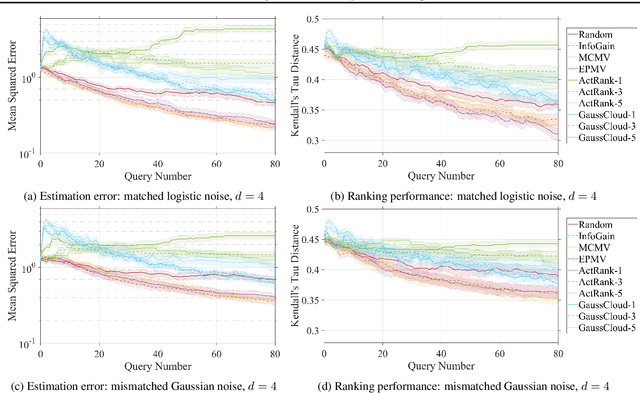
Suppose that we wish to estimate a user's preference vector $w$ from paired comparisons of the form "does user $w$ prefer item $p$ or item $q$?," where both the user and items are embedded in a low-dimensional Euclidean space with distances that reflect user and item similarities. Such observations arise in numerous settings, including psychometrics and psychology experiments, search tasks, advertising, and recommender systems. In such tasks, queries can be extremely costly and subject to varying levels of response noise; thus, we aim to actively choose pairs that are most informative given the results of previous comparisons. We provide new theoretical insights into the benefits and challenges of greedy information maximization in this setting, and develop two novel strategies that maximize lower bounds on information gain and are simpler to analyze and compute respectively. We use simulated responses from a real-world dataset to validate our strategies through their similar performance to greedy information maximization, and their superior preference estimation over state-of-the-art selection methods as well as random queries.