 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenDAS: Domain Adaptation for Open-Vocabulary Segmentation
May 30, 2024
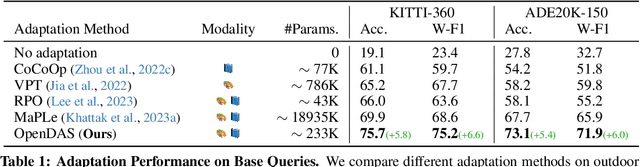
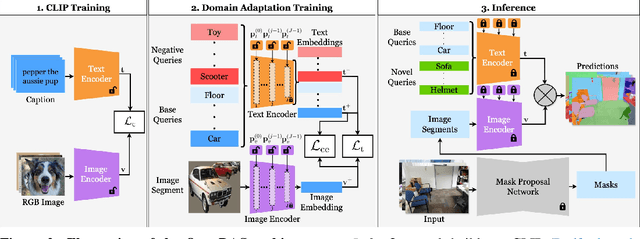

The advent of Vision Language Models (VLMs) transformed image understanding from closed-set classifications to dynamic image-language interactions, enabling open-vocabulary segmentation. Despite this flexibility, VLMs often fall behind closed-set classifiers in accuracy due to their reliance on ambiguous image captions and lack of domain-specific knowledge. We, therefore, introduce a new task domain adaptation for open-vocabulary segmentation, enhancing VLMs with domain-specific priors while preserving their open-vocabulary nature. Existing adaptation methods, when applied to segmentation tasks, improve performance on training queries but can reduce VLM performance on zero-shot text inputs. To address this shortcoming, we propose an approach that combines parameter-efficient prompt tuning with a triplet-loss-based training strategy. This strategy is designed to enhance open-vocabulary generalization while adapting to the visual domain. Our results outperform other parameter-efficient adaptation strategies in open-vocabulary segment classification tasks across indoor and outdoor datasets. Notably, our approach is the only one that consistently surpasses the original VLM on zero-shot queries. Our adapted VLMs can be plug-and-play integrated into existing open-vocabulary segmentation pipelines, improving OV-Seg by +6.0% mIoU on ADE20K, and OpenMask3D by +4.1% AP on ScanNet++ Offices without any changes to the methods.