 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Stability over Noisy Sources
Aug 05, 2015
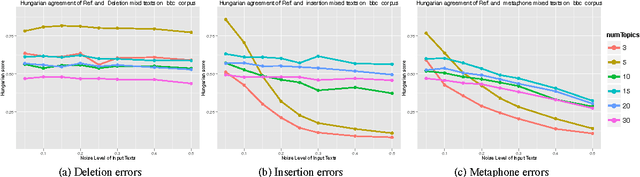

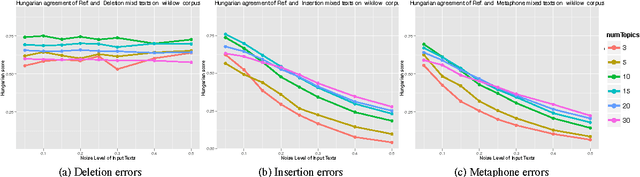
Topic modelling techniques such as LDA have recently been applied to speech transcripts and OCR output. These corpora may contain noisy or erroneous texts which may undermine topic stability. Therefore, it is important to know how well a topic modelling algorithm will perform when applied to noisy data. In this paper we show that different types of textual noise will have diverse effects on the stability of different topic models. From these observations, we propose guidelines for text corpus generation, with a focus on automatic speech transcription. We also suggest topic model selection methods for noisy corpora.
Chasing the Ghosts of Ibsen: A computational stylistic analysis of drama in translation
Jan 05, 2015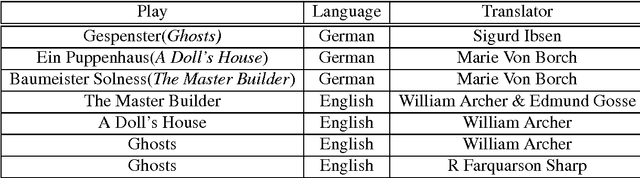
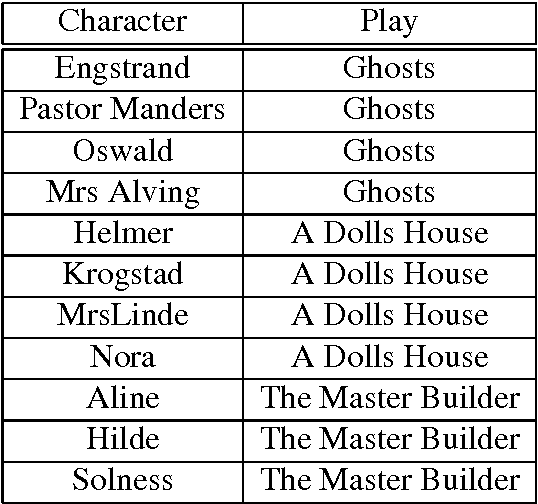
Research into the stylistic properties of translations is an issue which has received some attention in computational stylistics. Previous work by Rybicki (2006) on the distinguishing of character idiolects in the work of Polish author Henryk Sienkiewicz and two corresponding English translations using Burrow's Delta method concluded that idiolectal differences could be observed in the source texts and this variation was preserved to a large degree in both translations. This study also found that the two translations were also highly distinguishable from one another. Burrows (2002) examined English translations of Juvenal also using the Delta method, results of this work suggest that some translators are more adept at concealing their own style when translating the works of another author whereas other authors tend to imprint their own style to a greater extent on the work they translate. Our work examines the writing of a single author, Norwegian playwright Henrik Ibsen, and these writings translated into both German and English from Norwegian, in an attempt to investigate the preservation of characterization, defined here as the distinctiveness of textual contributions of characters.
* 6 pages