Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Stability over Noisy Sources
Paper and Code
Aug 05, 2015
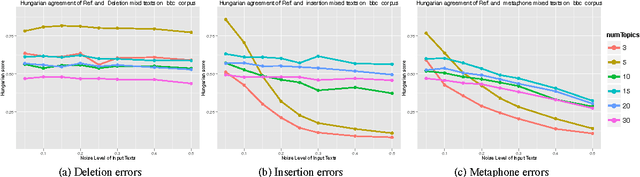

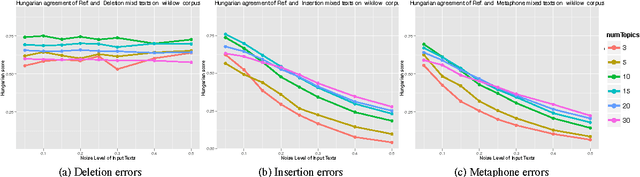
Topic modelling techniques such as LDA have recently been applied to speech transcripts and OCR output. These corpora may contain noisy or erroneous texts which may undermine topic stability. Therefore, it is important to know how well a topic modelling algorithm will perform when applied to noisy data. In this paper we show that different types of textual noise will have diverse effects on the stability of different topic models. From these observations, we propose guidelines for text corpus generation, with a focus on automatic speech transcription. We also suggest topic model selection methods for noisy corpora.
View paper on