 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Synergy: Unlocking Policy Insights and Learning Pathways Through Advanced Skill Mapping
Mar 13, 2025This research introduces a comprehensive system based on state-of-the-art natural language processing, semantic embedding, and efficient search techniques for retrieving similarities and thus generating actionable insights from raw textual information. The system automatically extracts and aggregates normalized competencies from multiple documents (such as policy files and curricula vitae) and creates strong relationships between recognized competencies, occupation profiles, and related learning courses. To validate its performance, we conducted a multi-tier evaluation that included both explicit and implicit skill references in synthetic and real-world documents. The results showed near-human-level accuracy, with F1 scores exceeding 0.95 for explicit skill detection and above 0.93 for implicit mentions. The system thereby establishes a sound foundation for supporting in-depth collaboration across the AE4RIA network. The methodology involves a multi-stage pipeline based on extensive preprocessing and data cleaning, semantic embedding and segmentation via SentenceTransformer, and skill extraction using a FAISS-based search method. The extracted skills are associated with occupation frameworks (as formulated in the ESCO ontology) and with learning paths offered through the Sustainable Development Goals Academy. Moreover, interactive visualization software, implemented with Dash and Plotly, presents graphs and tables for real-time exploration and informed decision-making by those involved in policymaking, training and learning supply, career transitions, and recruitment. Overall, this system, backed by rigorous validation, offers promising prospects for improved policymaking, human resource development, and lifelong learning by providing structured and actionable insights from raw, complex textual information.
Trustworthy AI: Securing Sensitive Data in Large Language Models
Sep 26, 2024


Large Language Models (LLMs) have transformed natural language processing (NLP) by enabling robust text generation and understanding. However, their deployment in sensitive domains like healthcare, finance, and legal services raises critical concerns about privacy and data security. This paper proposes a comprehensive framework for embedding trust mechanisms into LLMs to dynamically control the disclosure of sensitive information. The framework integrates three core components: User Trust Profiling, Information Sensitivity Detection, and Adaptive Output Control. By leveraging techniques such as Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), Named Entity Recognition (NER), contextual analysis, and privacy-preserving methods like differential privacy, the system ensures that sensitive information is disclosed appropriately based on the user's trust level. By focusing on balancing data utility and privacy, the proposed solution offers a novel approach to securely deploying LLMs in high-risk environments. Future work will focus on testing this framework across various domains to evaluate its effectiveness in managing sensitive data while maintaining system efficiency.
Using machine learning techniques to predict hospital admission at the emergency department
Jun 28, 2021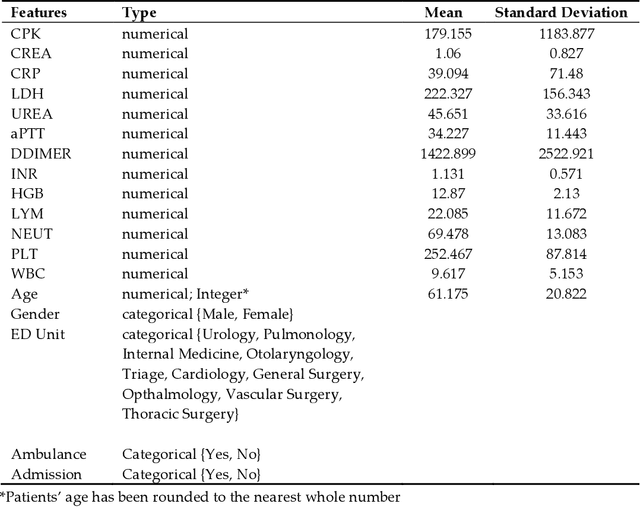
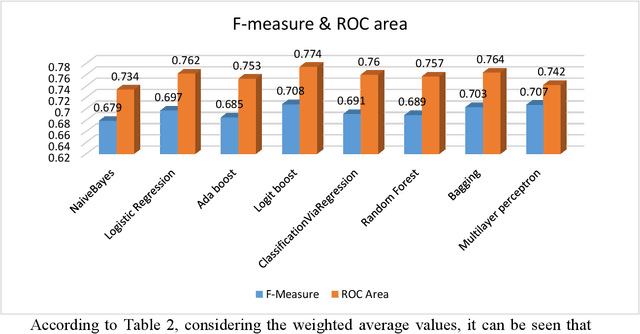
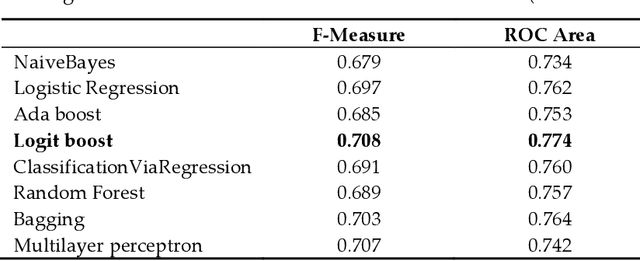
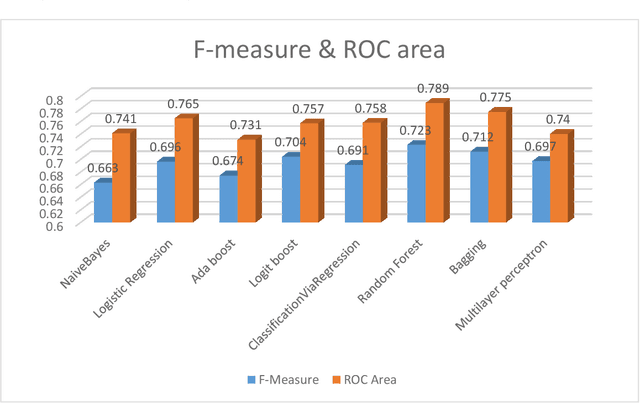
Introduction: One of the most important tasks in the Emergency Department (ED) is to promptly identify the patients who will benefit from hospital admission. Machine Learning (ML) techniques show promise as diagnostic aids in healthcare. Material and methods: We investigated the following features seeking to investigate their performance in predicting hospital admission: serum levels of Urea, Creatinine, Lactate Dehydrogenase, Creatine Kinase, C-Reactive Protein, Complete Blood Count with differential, Activated Partial Thromboplastin Time, D Dimer, International Normalized Ratio, age, gender, triage disposition to ED unit and ambulance utilization. A total of 3,204 ED visits were analyzed. Results: The proposed algorithms generated models which demonstrated acceptable performance in predicting hospital admission of ED patients. The range of F-measure and ROC Area values of all eight evaluated algorithms were [0.679-0.708] and [0.734-0.774], respectively. Discussion: The main advantages of this tool include easy access, availability, yes/no result, and low cost. The clinical implications of our approach might facilitate a shift from traditional clinical decision-making to a more sophisticated model. Conclusion: Developing robust prognostic models with the utilization of common biomarkers is a project that might shape the future of emergency medicine. Our findings warrant confirmation with implementation in pragmatic ED trials.
Pulmonary embolism identification in computerized tomography pulmonary angiography scans with deep learning technologies in COVID-19 patients
May 28, 2021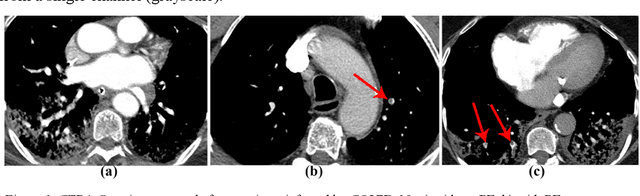
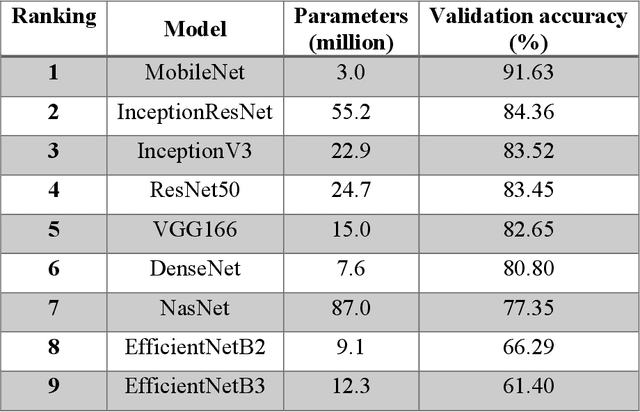
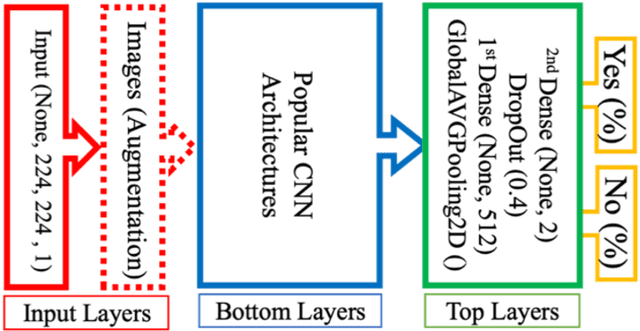
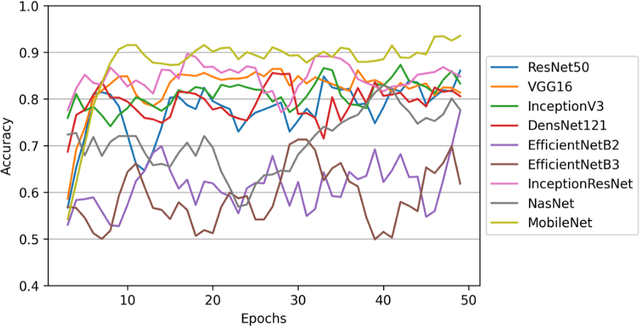
The main objective of this work is to utilize state-of-the-art deep learning approaches for the identification of pulmonary embolism in CTPA-Scans for COVID-19 patients, provide an initial assessment of their performance and, ultimately, provide a fast-track prototype solution (system). We adopted and assessed some of the most popular convolutional neural network architectures through transfer learning approaches, to strive to combine good model accuracy with fast training. Additionally, we exploited one of the most popular one-stage object detection models for the localization (through object detection) of the pulmonary embolism regions-of-interests. The models of both approaches are trained on an original CTPA-Scan dataset, where we annotated of 673 CTPA-Scan images with 1,465 bounding boxes in total, highlighting pulmonary embolism regions-of-interests. We provide a brief assessment of some state-of-the-art image classification models by achieving validation accuracies of 91% in pulmonary embolism classification. Additionally, we achieved a precision of about 68% on average in the object detection model for the pulmonary embolism localization under 50% IoU threshold. For both approaches, we provide the entire training pipelines for future studies (step by step processes through source code). In this study, we present some of the most accurate and fast deep learning models for pulmonary embolism identification in CTPA-Scans images, through classification and localization (object detection) approaches for patients infected by COVID-19. We provide a fast-track solution (system) for the research community of the area, which combines both classification and object detection models for improving the precision of identifying pulmonary embolisms.
On Using Linear Diophantine Equations to Tune the extent of Look Ahead while Hiding Decision Tree Rules
Oct 18, 2017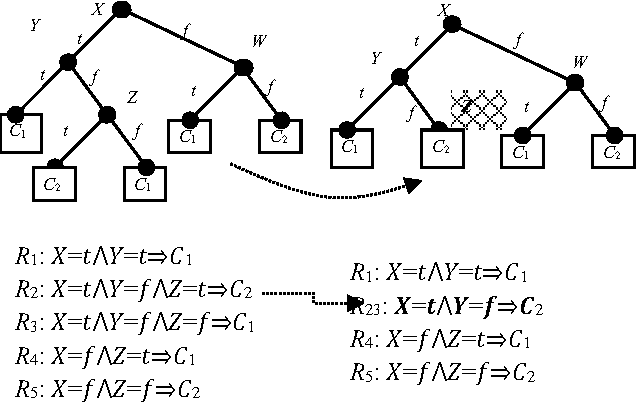
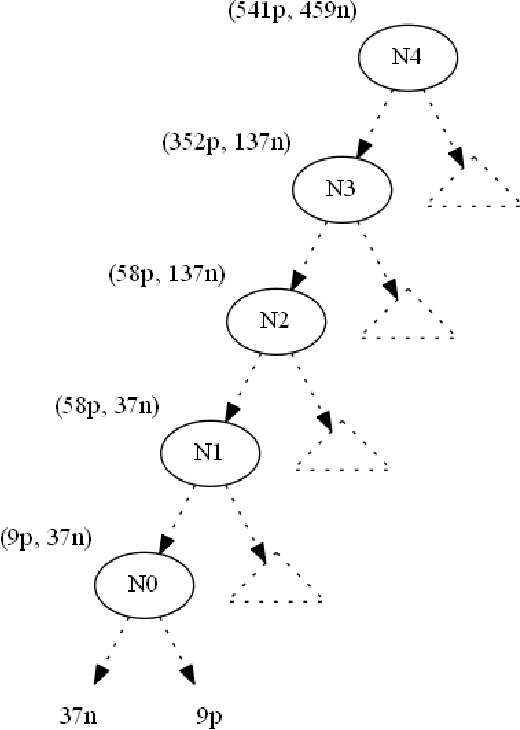

This paper focuses on preserving the privacy of sensitive pat-terns when inducing decision trees. We adopt a record aug-mentation approach for hiding sensitive classification rules in binary datasets. Such a hiding methodology is preferred over other heuristic solutions like output perturbation or crypto-graphic techniques - which restrict the usability of the data - since the raw data itself is readily available for public use. In this paper, we propose a look ahead approach using linear Diophantine equations in order to add the appropriate number of instances while minimally disturbing the initial entropy of the nodes.
Data set operations to hide decision tree rules
Jun 18, 2017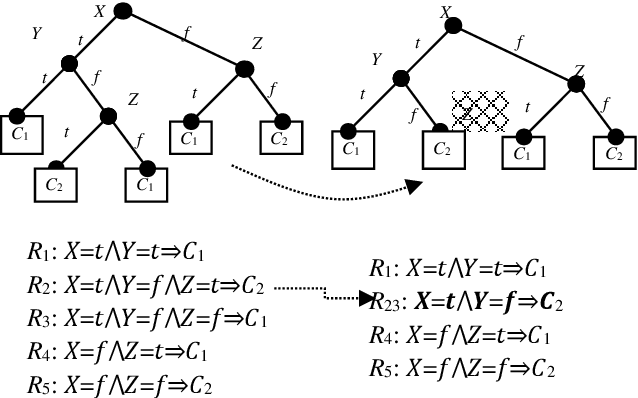
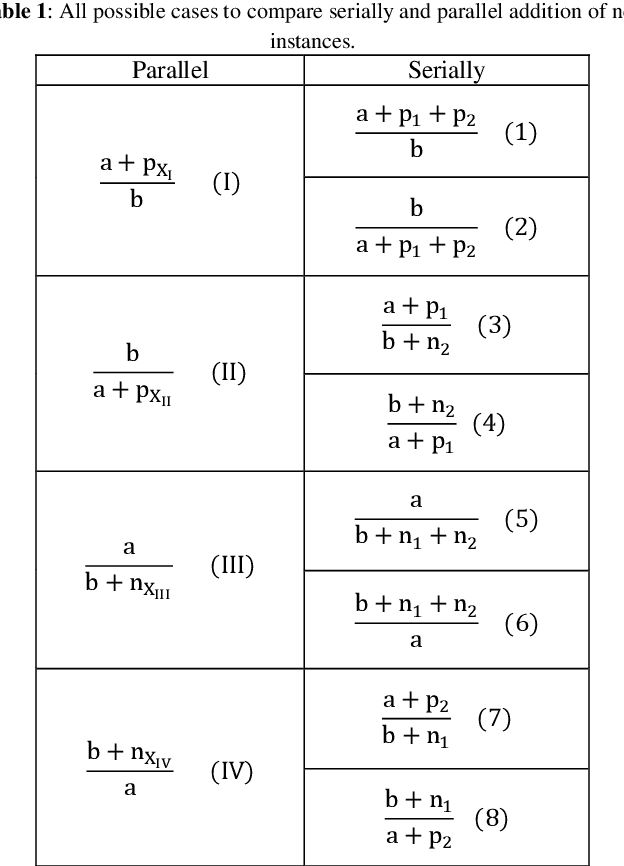
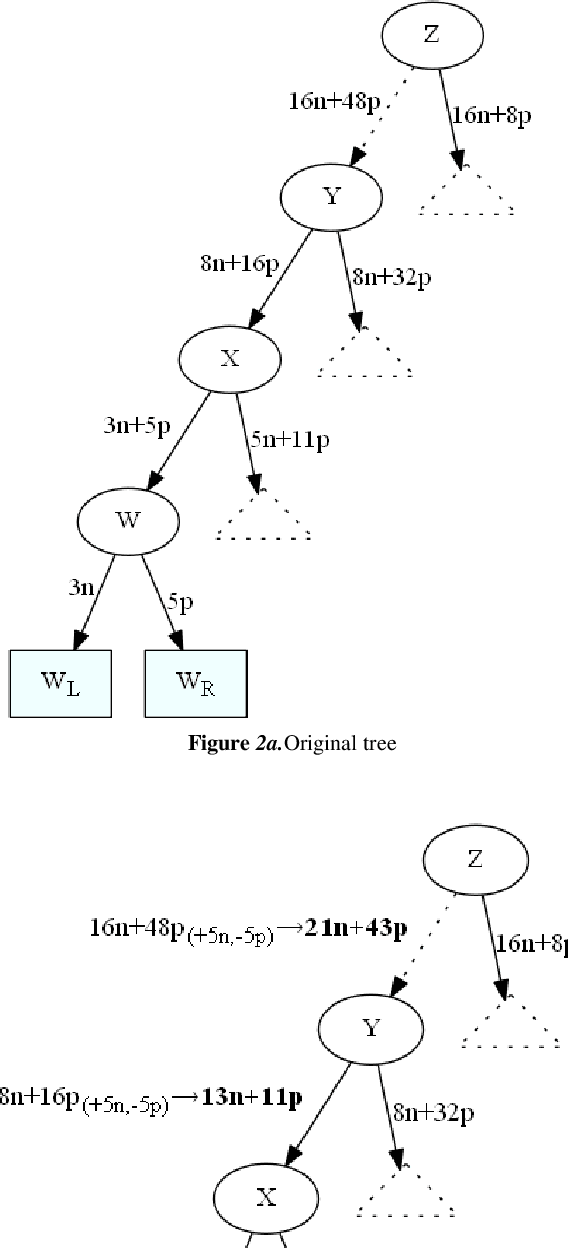

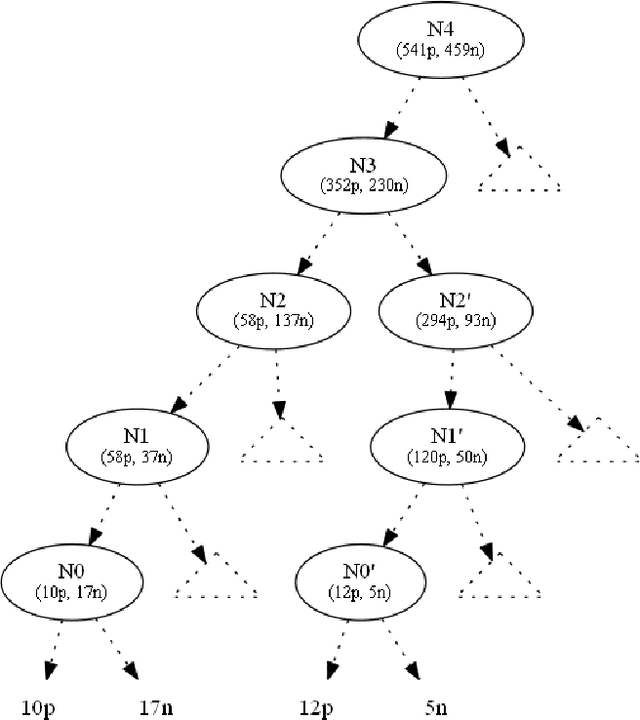
This paper focuses on preserving the privacy of sensitive patterns when inducing decision trees. We adopt a record augmentation approach for hiding sensitive classification rules in binary datasets. Such a hiding methodology is preferred over other heuristic solutions like output perturbation or cryptographic techniques - which restrict the usability of the data - since the raw data itself is readily available for public use. We show some key lemmas which are related to the hiding process and we also demonstrate the methodology with an example and an indicative experiment using a prototype hiding tool.