Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData set operations to hide decision tree rules
Jun 18, 2017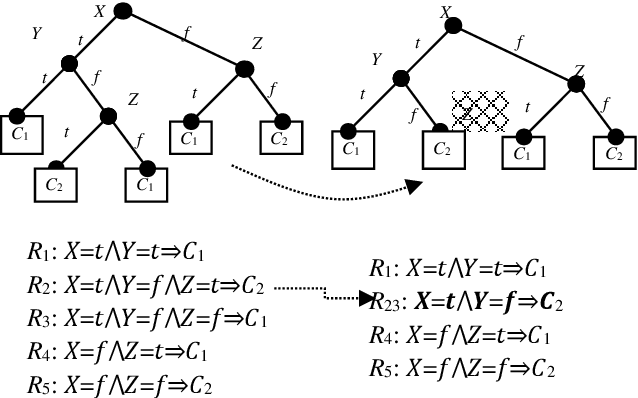
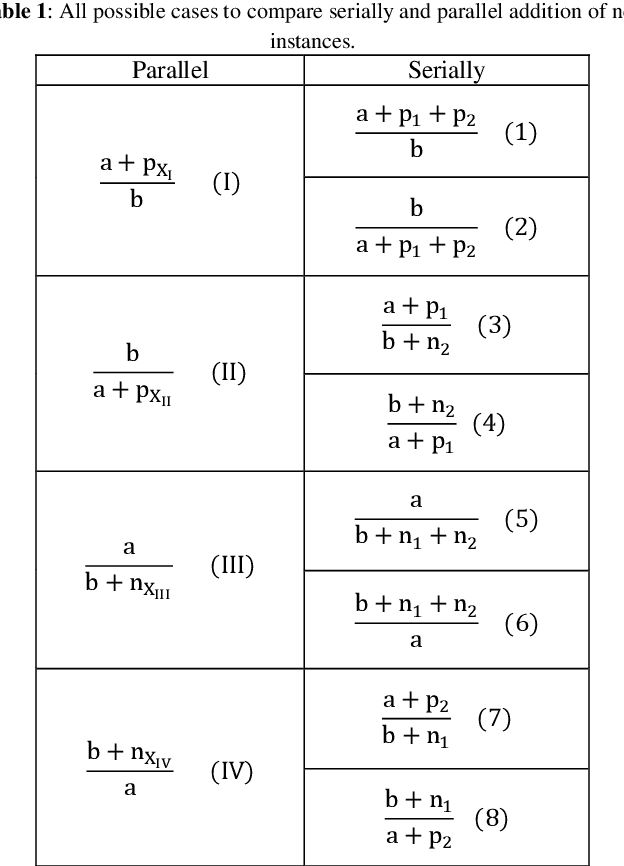
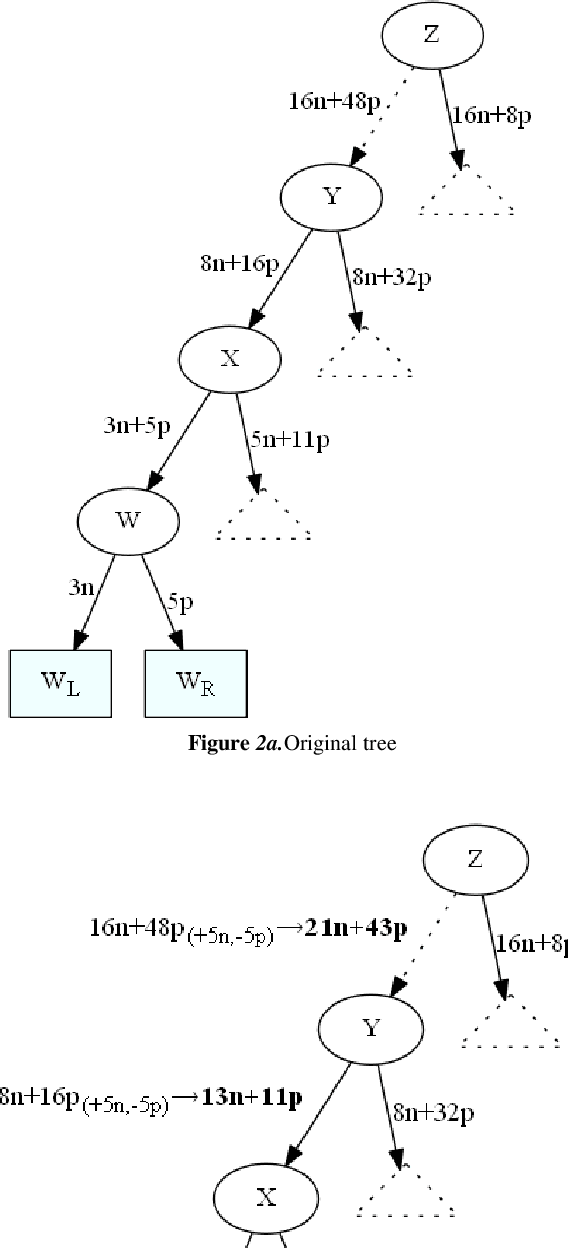

This paper focuses on preserving the privacy of sensitive patterns when inducing decision trees. We adopt a record augmentation approach for hiding sensitive classification rules in binary datasets. Such a hiding methodology is preferred over other heuristic solutions like output perturbation or cryptographic techniques - which restrict the usability of the data - since the raw data itself is readily available for public use. We show some key lemmas which are related to the hiding process and we also demonstrate the methodology with an example and an indicative experiment using a prototype hiding tool.
* 7 pages, 4 figures and 2 tables. ECAI 2016
Via