 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence and Cost Reduction in Public Higher Education: A Scoping Review of Emerging Evidence
Apr 06, 2026Public higher education systems face increasing financial pressures from expanding student populations, rising operational costs, and persistent demands for equitable access. Artificial Intelligence (AI), including generative tools such as ChatGPT, learning analytics, intelligent tutoring systems, and predictive models, has been proposed as a means of enhancing efficiency and reducing costs. This study conducts a scoping review of the literature on AI applications in public higher education, based on systematic searches in Scopus and IEEE Xplore that identified 241 records, of which 21 empirical studies met predefined eligibility criteria and were thematically analyzed. The findings show that AI enables cost savings by automating administrative tasks, optimizing resource allocation, supporting personalized learning at scale, and applying predictive analytics to improve student retention and institutional planning. At the same time, concerns emerge regarding implementation costs, unequal access across institutions, and risks of widening digital divides. Overall, the thematic analysis highlights both the promises and limitations of AI-driven cost reduction in higher education, offering insights for policymakers, university administrators, and educators on the economic implications of AI adoption, while also pointing to gaps that warrant further empirical research.
Trustworthy AI: Securing Sensitive Data in Large Language Models
Sep 26, 2024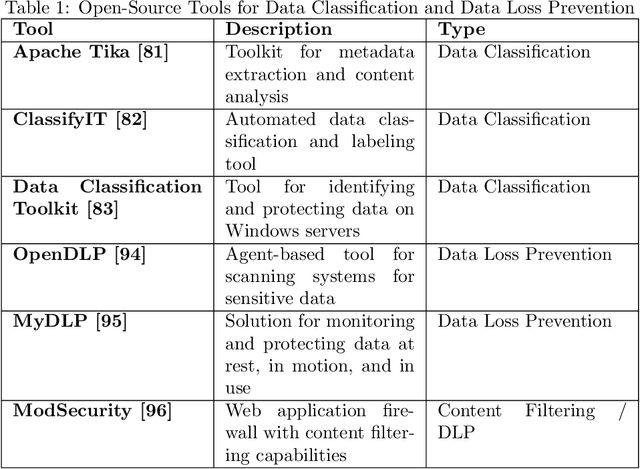


Large Language Models (LLMs) have transformed natural language processing (NLP) by enabling robust text generation and understanding. However, their deployment in sensitive domains like healthcare, finance, and legal services raises critical concerns about privacy and data security. This paper proposes a comprehensive framework for embedding trust mechanisms into LLMs to dynamically control the disclosure of sensitive information. The framework integrates three core components: User Trust Profiling, Information Sensitivity Detection, and Adaptive Output Control. By leveraging techniques such as Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), Named Entity Recognition (NER), contextual analysis, and privacy-preserving methods like differential privacy, the system ensures that sensitive information is disclosed appropriately based on the user's trust level. By focusing on balancing data utility and privacy, the proposed solution offers a novel approach to securely deploying LLMs in high-risk environments. Future work will focus on testing this framework across various domains to evaluate its effectiveness in managing sensitive data while maintaining system efficiency.
On Using Linear Diophantine Equations to Tune the extent of Look Ahead while Hiding Decision Tree Rules
Oct 18, 2017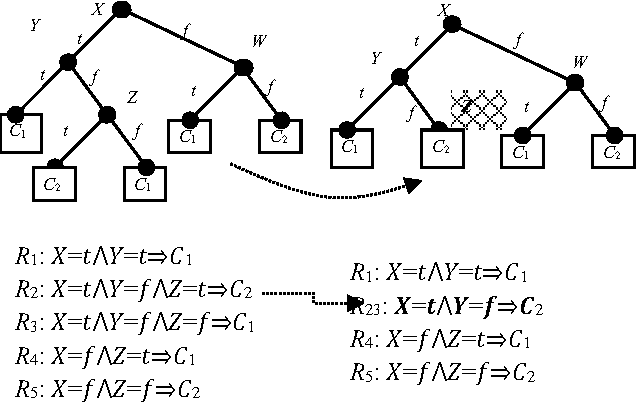
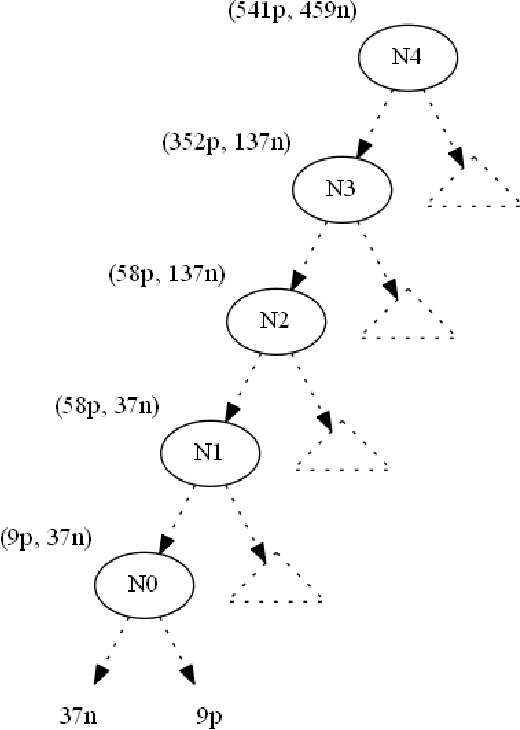

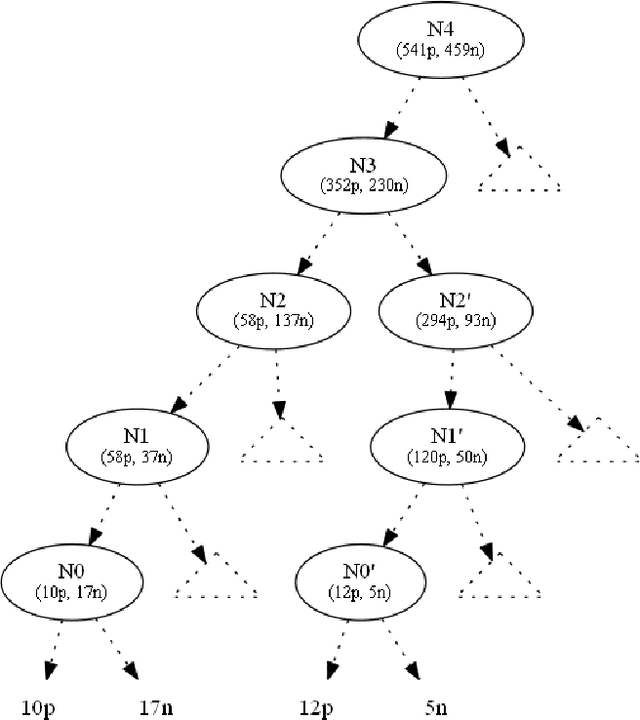
This paper focuses on preserving the privacy of sensitive pat-terns when inducing decision trees. We adopt a record aug-mentation approach for hiding sensitive classification rules in binary datasets. Such a hiding methodology is preferred over other heuristic solutions like output perturbation or crypto-graphic techniques - which restrict the usability of the data - since the raw data itself is readily available for public use. In this paper, we propose a look ahead approach using linear Diophantine equations in order to add the appropriate number of instances while minimally disturbing the initial entropy of the nodes.
Data set operations to hide decision tree rules
Jun 18, 2017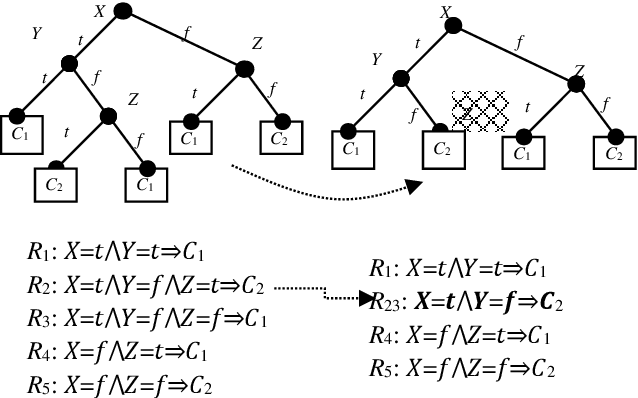
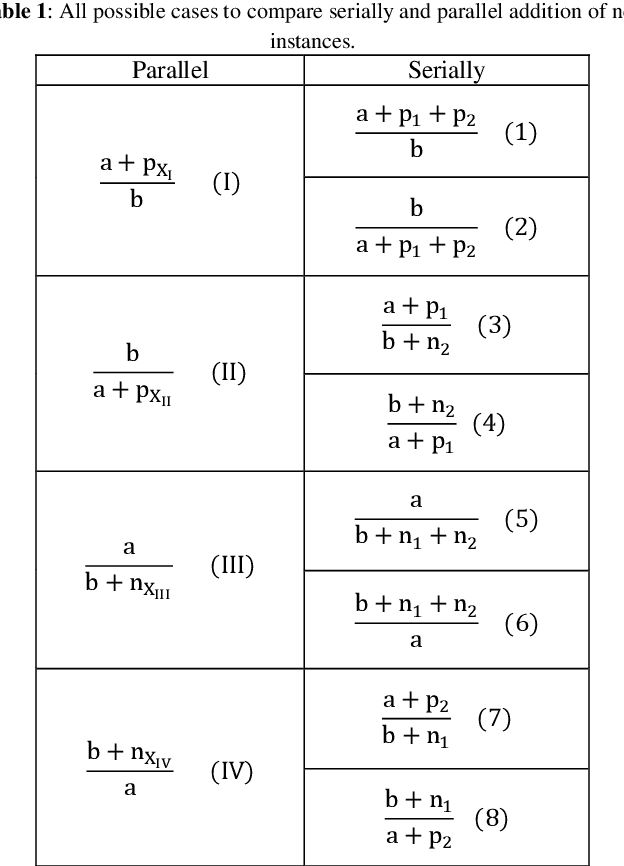
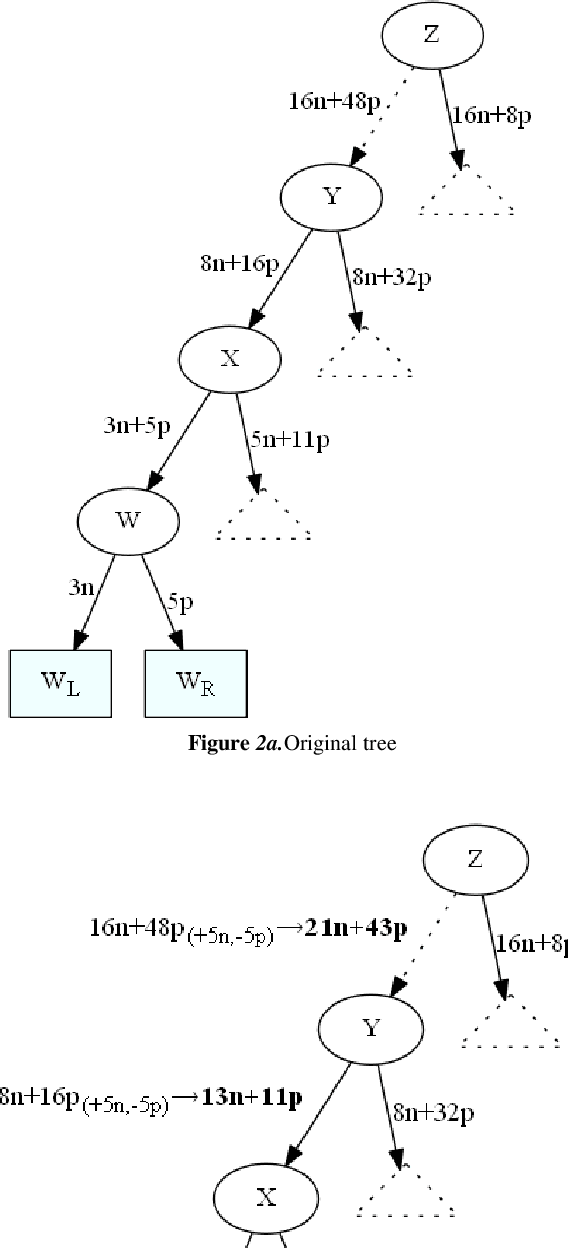

This paper focuses on preserving the privacy of sensitive patterns when inducing decision trees. We adopt a record augmentation approach for hiding sensitive classification rules in binary datasets. Such a hiding methodology is preferred over other heuristic solutions like output perturbation or cryptographic techniques - which restrict the usability of the data - since the raw data itself is readily available for public use. We show some key lemmas which are related to the hiding process and we also demonstrate the methodology with an example and an indicative experiment using a prototype hiding tool.