 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-in-the-Loop Testing of AI Agents for Air Traffic Control with a Regulated Assessment Framework
Jan 07, 2026We present a rigorous, human-in-the-loop evaluation framework for assessing the performance of AI agents on the task of Air Traffic Control, grounded in a regulator-certified simulator-based curriculum used for training and testing real-world trainee controllers. By leveraging legally regulated assessments and involving expert human instructors in the evaluation process, our framework enables a more authentic and domain-accurate measurement of AI performance. This work addresses a critical gap in the existing literature: the frequent misalignment between academic representations of Air Traffic Control and the complexities of the actual operational environment. It also lays the foundations for effective future human-machine teaming paradigms by aligning machine performance with human assessment targets.
A Future Capabilities Agent for Tactical Air Traffic Control
Jan 07, 2026Escalating air traffic demand is driving the adoption of automation to support air traffic controllers, but existing approaches face a trade-off between safety assurance and interpretability. Optimisation-based methods such as reinforcement learning offer strong performance but are difficult to verify and explain, while rules-based systems are transparent yet rarely check safety under uncertainty. This paper outlines Agent Mallard, a forward-planning, rules-based agent for tactical control in systemised airspace that embeds a stochastic digital twin directly into its conflict-resolution loop. Mallard operates on predefined GPS-guided routes, reducing continuous 4D vectoring to discrete choices over lanes and levels, and constructs hierarchical plans from an expert-informed library of deconfliction strategies. A depth-limited backtracking search uses causal attribution, topological plan splicing, and monotonic axis constraints to seek a complete safe plan for all aircraft, validating each candidate manoeuvre against uncertain execution scenarios (e.g., wind variation, pilot response, communication loss) before commitment. Preliminary walkthroughs with UK controllers and initial tests in the BluebirdDT airspace digital twin indicate that Mallard's behaviour aligns with expert reasoning and resolves conflicts in simplified scenarios. The architecture is intended to combine model-based safety assessment, interpretable decision logic, and tractable computational performance in future structured en-route environments.
Online Action-Stacking Improves Reinforcement Learning Performance for Air Traffic Control
Jan 07, 2026We introduce online action-stacking, an inference-time wrapper for reinforcement learning policies that produces realistic air traffic control commands while allowing training on a much smaller discrete action space. Policies are trained with simple incremental heading or level adjustments, together with an action-damping penalty that reduces instruction frequency and leads agents to issue commands in short bursts. At inference, online action-stacking compiles these bursts of primitive actions into domain-appropriate compound clearances. Using Proximal Policy Optimisation and the BluebirdDT digital twin platform, we train agents to navigate aircraft along lateral routes, manage climb and descent to target flight levels, and perform two-aircraft collision avoidance under a minimum separation constraint. In our lateral navigation experiments, action stacking greatly reduces the number of issued instructions relative to a damped baseline and achieves comparable performance to a policy trained with a 37-dimensional action space, despite operating with only five actions. These results indicate that online action-stacking helps bridge a key gap between standard reinforcement learning formulations and operational ATC requirements, and provides a simple mechanism for scaling to more complex control scenarios.
Air Traffic Controller Task Demand via Graph Neural Networks: An Interpretable Approach to Airspace Complexity
Jul 17, 2025Real-time assessment of near-term Air Traffic Controller (ATCO) task demand is a critical challenge in an increasingly crowded airspace, as existing complexity metrics often fail to capture nuanced operational drivers beyond simple aircraft counts. This work introduces an interpretable Graph Neural Network (GNN) framework to address this gap. Our attention-based model predicts the number of upcoming clearances, the instructions issued to aircraft by ATCOs, from interactions within static traffic scenarios. Crucially, we derive an interpretable, per-aircraft task demand score by systematically ablating aircraft and measuring the impact on the model's predictions. Our framework significantly outperforms an ATCO-inspired heuristic and is a more reliable estimator of scenario complexity than established baselines. The resulting tool can attribute task demand to specific aircraft, offering a new way to analyse and understand the drivers of complexity for applications in controller training and airspace redesign.
Context-Aware Generative Models for Prediction of Aircraft Ground Tracks
Sep 26, 2023Trajectory prediction (TP) plays an important role in supporting the decision-making of Air Traffic Controllers (ATCOs). Traditional TP methods are deterministic and physics-based, with parameters that are calibrated using aircraft surveillance data harvested across the world. These models are, therefore, agnostic to the intentions of the pilots and ATCOs, which can have a significant effect on the observed trajectory, particularly in the lateral plane. This work proposes a generative method for lateral TP, using probabilistic machine learning to model the effect of the epistemic uncertainty arising from the unknown effect of pilot behaviour and ATCO intentions. The models are trained to be specific to a particular sector, allowing local procedures such as coordinated entry and exit points to be modelled. A dataset comprising a week's worth of aircraft surveillance data, passing through a busy sector of the United Kingdom's upper airspace, was used to train and test the models. Specifically, a piecewise linear model was used as a functional, low-dimensional representation of the ground tracks, with its control points determined by a generative model conditioned on partial context. It was found that, of the investigated models, a Bayesian Neural Network using the Laplace approximation was able to generate the most plausible trajectories in order to emulate the flow of traffic through the sector.
MBORE: Multi-objective Bayesian Optimisation by Density-Ratio Estimation
Mar 31, 2022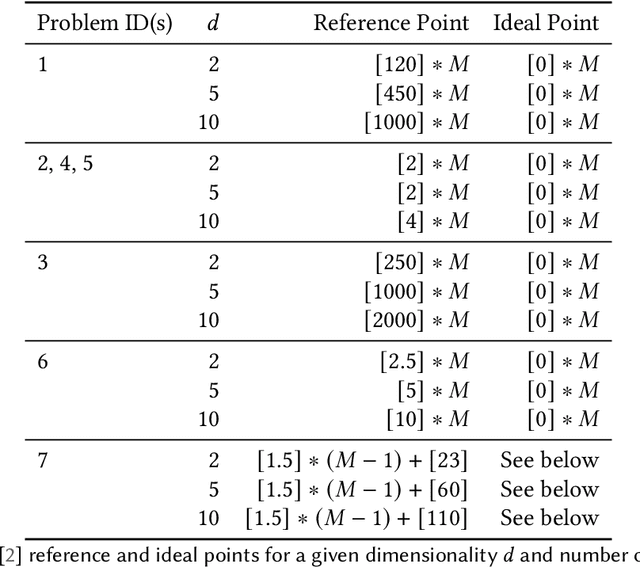
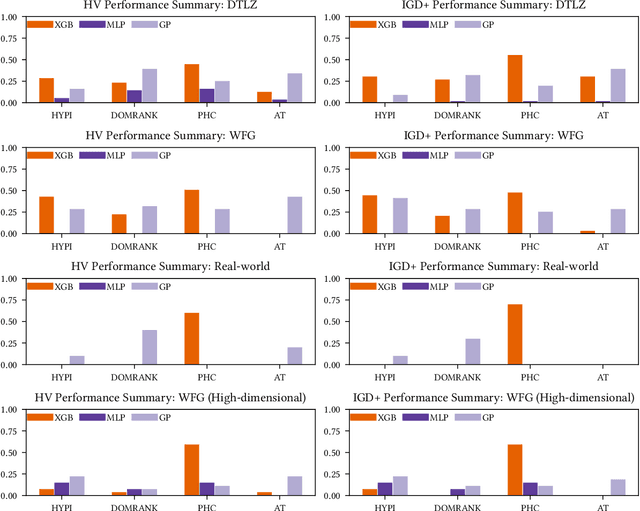

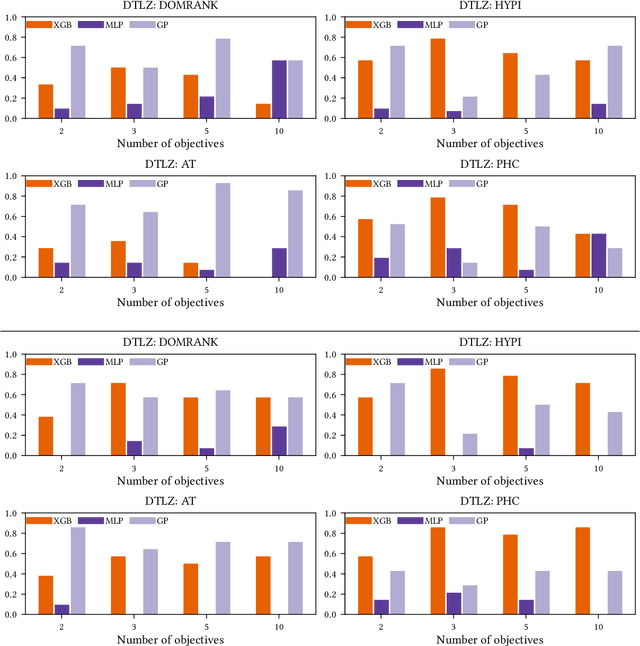
Optimisation problems often have multiple conflicting objectives that can be computationally and/or financially expensive. Mono-surrogate Bayesian optimisation (BO) is a popular model-based approach for optimising such black-box functions. It combines objective values via scalarisation and builds a Gaussian process (GP) surrogate of the scalarised values. The location which maximises a cheap-to-query acquisition function is chosen as the next location to expensively evaluate. While BO is an effective strategy, the use of GPs is limiting. Their performance decreases as the problem input dimensionality increases, and their computational complexity scales cubically with the amount of data. To address these limitations, we extend previous work on BO by density-ratio estimation (BORE) to the multi-objective setting. BORE links the computation of the probability of improvement acquisition function to that of probabilistic classification. This enables the use of state-of-the-art classifiers in a BO-like framework. In this work we present MBORE: multi-objective Bayesian optimisation by density-ratio estimation, and compare it to BO across a range of synthetic and real-world benchmarks. We find that MBORE performs as well as or better than BO on a wide variety of problems, and that it outperforms BO on high-dimensional and real-world problems.
How Bayesian Should Bayesian Optimisation Be?
May 03, 2021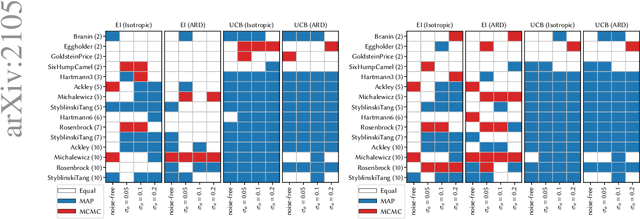



Bayesian optimisation (BO) uses probabilistic surrogate models - usually Gaussian processes (GPs) - for the optimisation of expensive black-box functions. At each BO iteration, the GP hyperparameters are fit to previously-evaluated data by maximising the marginal likelihood. However, this fails to account for uncertainty in the hyperparameters themselves, leading to overconfident model predictions. This uncertainty can be accounted for by taking the Bayesian approach of marginalising out the model hyperparameters. We investigate whether a fully-Bayesian treatment of the Gaussian process hyperparameters in BO (FBBO) leads to improved optimisation performance. Since an analytic approach is intractable, we compare FBBO using three approximate inference schemes to the maximum likelihood approach, using the Expected Improvement (EI) and Upper Confidence Bound (UCB) acquisition functions paired with ARD and isotropic Matern kernels, across 15 well-known benchmark problems for 4 observational noise settings. FBBO using EI with an ARD kernel leads to the best performance in the noise-free setting, with much less difference between combinations of BO components when the noise is increased. FBBO leads to over-exploration with UCB, but is not detrimental with EI. Therefore, we recommend that FBBO using EI with an ARD kernel as the default choice for BO.
Asynchronous ε-Greedy Bayesian Optimisation
Oct 16, 2020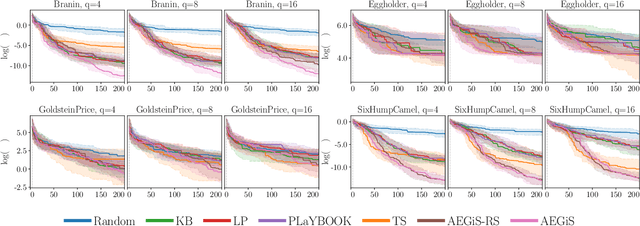
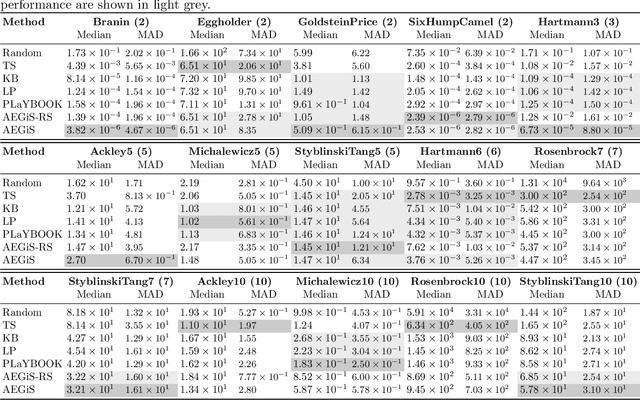
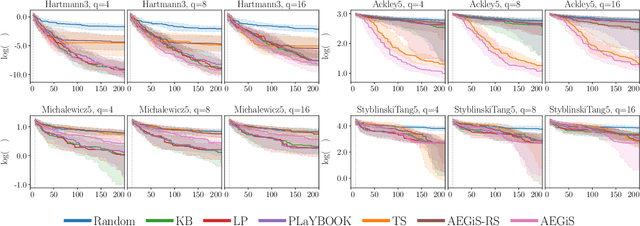
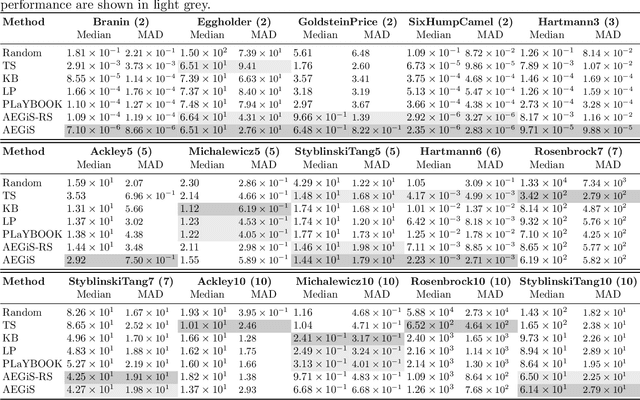
Bayesian Optimisation (BO) is a popular surrogate model-based approach for optimising expensive black-box functions. In order to reduce optimisation wallclock time, parallel evaluation of the black-box function has been proposed. Asynchronous BO allows for a new evaluation to be started as soon as another finishes, thus maximising utilisation of evaluation workers. We present AEGiS (Asynchronous $\epsilon$-Greedy Global Search), an asynchronous BO method that, with probability $2\epsilon$, performs either Thompson sampling or random selection from the approximate Pareto set trading-off between exploitation (surrogate mean prediction) and exploration (surrogate posterior variance). The remaining $1-2\epsilon$ of moves exploit the surrogate's mean prediction. Results on fifteen synthetic benchmark problems, three meta-surrogate hyperparameter tuning problems and two robot pushing problems show that AEGiS generally outperforms existing methods for asynchronous BO. When a single worker is available performance is no worse than BO using expected improvement. We also verify the importance of each of the three components in an ablation study, as well as comparing Pareto set selection to selection from the entire feasible problem domain, finding that the former is vastly superior.
What do you Mean? The Role of the Mean Function in Bayesian Optimisation
May 08, 2020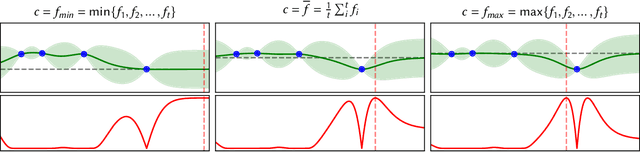

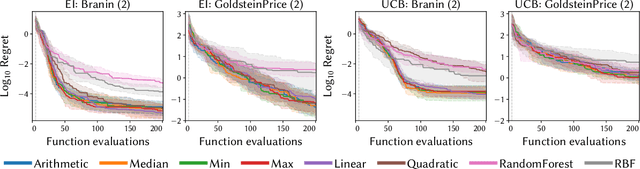
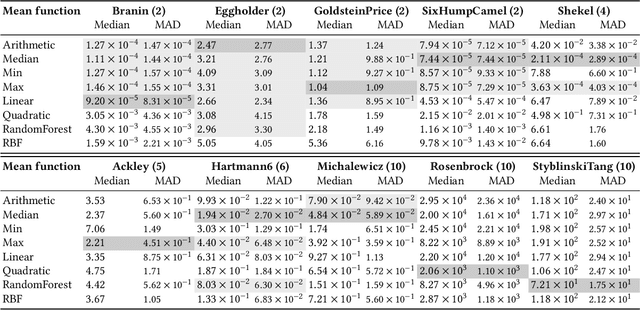
Bayesian optimisation is a popular approach for optimising expensive black-box functions. The next location to be evaluated is selected via maximising an acquisition function that balances exploitation and exploration. Gaussian processes, the surrogate models of choice in Bayesian optimisation, are often used with a constant prior mean function equal to the arithmetic mean of the observed function values. We show that the rate of convergence can depend sensitively on the choice of mean function. We empirically investigate 8 mean functions (constant functions equal to the arithmetic mean, minimum, median and maximum of the observed function evaluations, linear, quadratic polynomials, random forests and RBF networks), using 10 synthetic test problems and two real-world problems, and using the Expected Improvement and Upper Confidence Bound acquisition functions. We find that for design dimensions $\ge5$ using a constant mean function equal to the worst observed quality value is consistently the best choice on the synthetic problems considered. We argue that this worst-observed-quality function promotes exploitation leading to more rapid convergence. However, for the real-world tasks the more complex mean functions capable of modelling the fitness landscape may be effective, although there is no clearly optimum choice.
$ε$-shotgun: $ε$-greedy Batch Bayesian Optimisation
Feb 05, 2020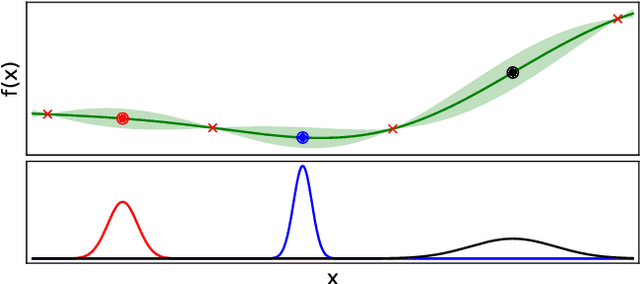

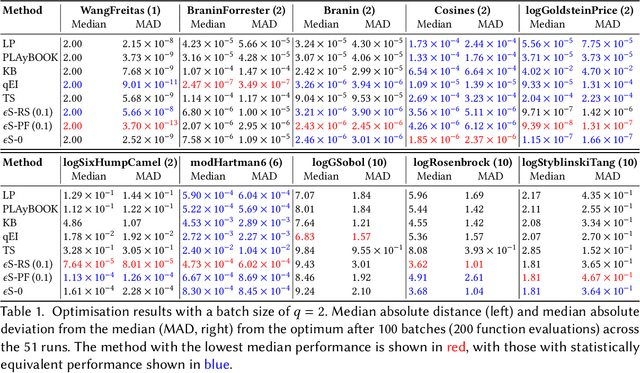
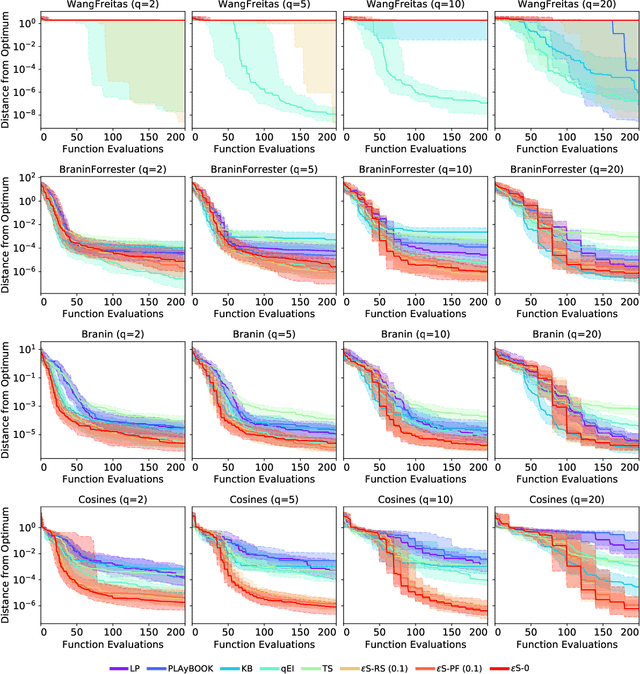
Bayesian optimisation is a popular, surrogate model-based approach for optimising expensive black-box functions. Given a surrogate model, the next location to expensively evaluate is chosen via maximisation of a cheap-to-query acquisition function. We present an $\epsilon$-greedy procedure for Bayesian optimisation in batch settings in which the black-box function can be evaluated multiple times in parallel. Our $\epsilon$-shotgun algorithm leverages the model's prediction, uncertainty, and the approximated rate of change of the landscape to determine the spread of batch solutions to be distributed around a putative location. The initial target location is selected either in an exploitative fashion on the mean prediction, or -- with probability $\epsilon$ -- from elsewhere in the design space. This results in locations that are more densely sampled in regions where the function is changing rapidly and in locations predicted to be good (i.e close to predicted optima), with more scattered samples in regions where the function is flatter and/or of poorer quality. We empirically evaluate the $\epsilon$-shotgun methods on a range of synthetic functions and two real-world problems, finding that they perform at least as well as state-of-the-art batch methods and in many cases exceed their performance.