 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Integration on Graphs: where to sample and how to weigh
Mar 19, 2018
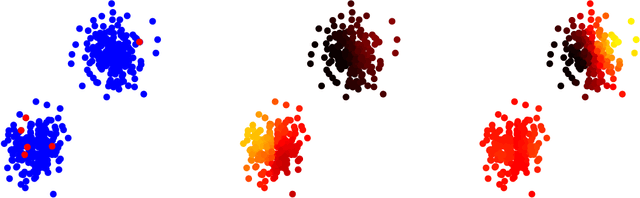
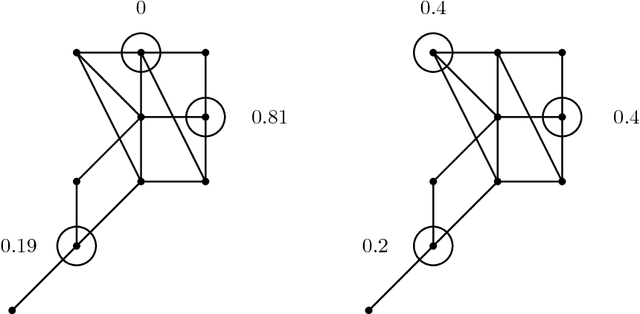
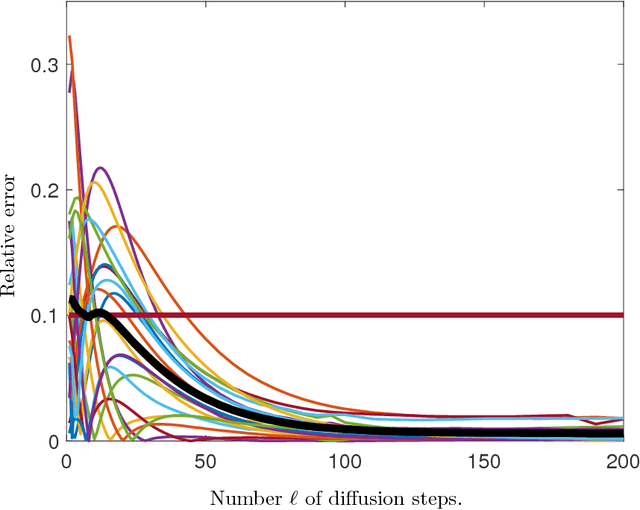
Let $G=(V,E,w)$ be a finite, connected graph with weighted edges. We are interested in the problem of finding a subset $W \subset V$ of vertices and weights $a_w$ such that $$ \frac{1}{|V|}\sum_{v \in V}^{}{f(v)} \sim \sum_{w \in W}{a_w f(w)}$$ for functions $f:V \rightarrow \mathbb{R}$ that are `smooth' with respect to the geometry of the graph. The main application are problems where $f$ is known to somehow depend on the underlying graph but is expensive to evaluate on even a single vertex. We prove an inequality showing that the integration problem can be rewritten as a geometric problem (`the optimal packing of heat balls'). We discuss how one would construct approximate solutions of the heat ball packing problem; numerical examples demonstrate the efficiency of the method.
Efficient Algorithms for t-distributed Stochastic Neighborhood Embedding
Dec 25, 2017
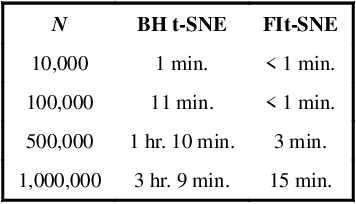
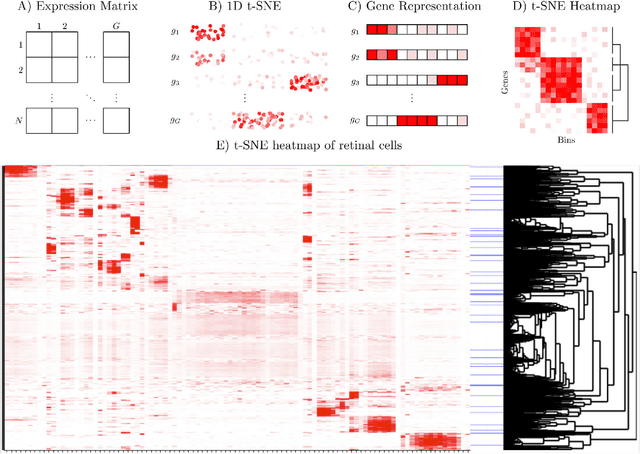

t-distributed Stochastic Neighborhood Embedding (t-SNE) is a method for dimensionality reduction and visualization that has become widely popular in recent years. Efficient implementations of t-SNE are available, but they scale poorly to datasets with hundreds of thousands to millions of high dimensional data-points. We present Fast Fourier Transform-accelerated Interpolation-based t-SNE (FIt-SNE), which dramatically accelerates the computation of t-SNE. The most time-consuming step of t-SNE is a convolution that we accelerate by interpolating onto an equispaced grid and subsequently using the fast Fourier transform to perform the convolution. We also optimize the computation of input similarities in high dimensions using multi-threaded approximate nearest neighbors. We further present a modification to t-SNE called "late exaggeration," which allows for easier identification of clusters in t-SNE embeddings. Finally, for datasets that cannot be loaded into the memory, we present out-of-core randomized principal component analysis (oocPCA), so that the top principal components of a dataset can be computed without ever fully loading the matrix, hence allowing for t-SNE of large datasets to be computed on resource-limited machines.
Randomized Near Neighbor Graphs, Giant Components, and Applications in Data Science
Nov 13, 2017



If we pick $n$ random points uniformly in $[0,1]^d$ and connect each point to its $k-$nearest neighbors, then it is well known that there exists a giant connected component with high probability. We prove that in $[0,1]^d$ it suffices to connect every point to $ c_{d,1} \log{\log{n}}$ points chosen randomly among its $ c_{d,2} \log{n}-$nearest neighbors to ensure a giant component of size $n - o(n)$ with high probability. This construction yields a much sparser random graph with $\sim n \log\log{n}$ instead of $\sim n \log{n}$ edges that has comparable connectivity properties. This result has nontrivial implications for problems in data science where an affinity matrix is constructed: instead of picking the $k-$nearest neighbors, one can often pick $k' \ll k$ random points out of the $k-$nearest neighbors without sacrificing efficiency. This can massively simplify and accelerate computation, we illustrate this with several numerical examples.
Clustering with t-SNE, provably
Jun 08, 2017



t-distributed Stochastic Neighborhood Embedding (t-SNE), a clustering and visualization method proposed by van der Maaten & Hinton in 2008, has rapidly become a standard tool in a number of natural sciences. Despite its overwhelming success, there is a distinct lack of mathematical foundations and the inner workings of the algorithm are not well understood. The purpose of this paper is to prove that t-SNE is able to recover well-separated clusters; more precisely, we prove that t-SNE in the `early exaggeration' phase, an optimization technique proposed by van der Maaten & Hinton (2008) and van der Maaten (2014), can be rigorously analyzed. As a byproduct, the proof suggests novel ways for setting the exaggeration parameter $\alpha$ and step size $h$. Numerical examples illustrate the effectiveness of these rules: in particular, the quality of embedding of topological structures (e.g. the swiss roll) improves. We also discuss a connection to spectral clustering methods.