 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaintaining Stability and Plasticity for Predictive Churn Reduction
May 06, 2023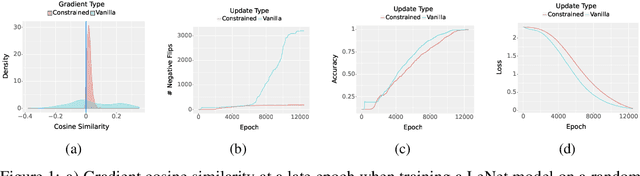
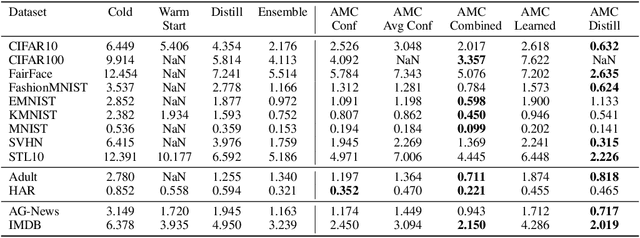
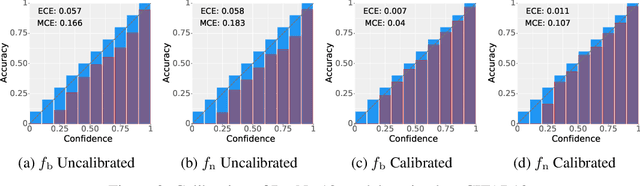

Deployed machine learning models should be updated to take advantage of a larger sample size to improve performance, as more data is gathered over time. Unfortunately, even when model updates improve aggregate metrics such as accuracy, they can lead to errors on samples that were correctly predicted by the previous model causing per-sample regression in performance known as predictive churn. Such prediction flips erode user trust thereby reducing the effectiveness of the human-AI team as a whole. We propose a solution called Accumulated Model Combination (AMC) based keeping the previous and current model version, and generating a meta-output using the prediction of the two models. AMC is a general technique and we propose several instances of it, each having their own advantages depending on the model and data properties. AMC requires minimal additional computation and changes to training procedures. We motivate the need for AMC by showing the difficulty of making a single model consistent with its own predictions throughout training thereby revealing an implicit stability-plasticity tradeoff when training a single model. We demonstrate the effectiveness of AMC on a variety of modalities including computer vision, text, and tabular datasets comparing against state-of-the-art churn reduction methods, and showing superior churn reduction ability compared to all existing methods while being more efficient than ensembles.
Evaluating Ensemble Robustness Against Adversarial Attacks
May 12, 2020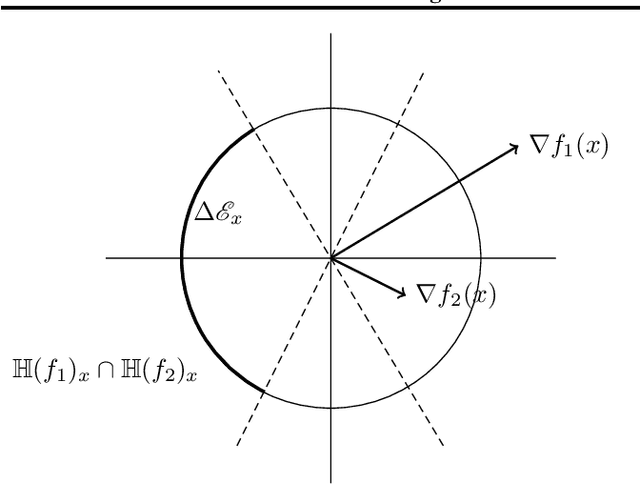


Adversarial examples, which are slightly perturbed inputs generated with the aim of fooling a neural network, are known to transfer between models; adversaries which are effective on one model will often fool another. This concept of transferability poses grave security concerns as it leads to the possibility of attacking models in a black box setting, during which the internal parameters of the target model are unknown. In this paper, we seek to analyze and minimize the transferability of adversaries between models within an ensemble. To this end, we introduce a gradient based measure of how effectively an ensemble's constituent models collaborate to reduce the space of adversarial examples targeting the ensemble itself. Furthermore, we demonstrate that this measure can be utilized during training as to increase an ensemble's robustness to adversarial examples.
Reducing Adversarial Example Transferability Using Gradient Regularization
Apr 16, 2019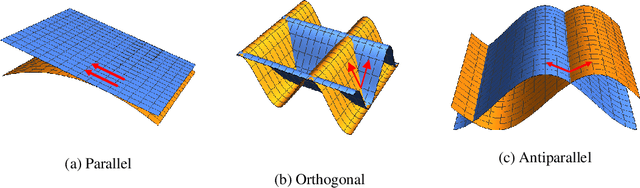



Deep learning algorithms have increasingly been shown to lack robustness to simple adversarial examples (AdvX). An equally troubling observation is that these adversarial examples transfer between different architectures trained on different datasets. We investigate the transferability of adversarial examples between models using the angle between the input-output Jacobians of different models. To demonstrate the relevance of this approach, we perform case studies that involve jointly training pairs of models. These case studies empirically justify the theoretical intuitions for why the angle between gradients is a fundamental quantity in AdvX transferability. Furthermore, we consider the asymmetry of AdvX transferability between two models of the same architecture and explain it in terms of differences in gradient norms between the models. Lastly, we provide a simple modification to existing training setups that reduces transferability of adversarial examples between pairs of models.
Understanding Neural Architecture Search Techniques
Mar 31, 2019



Automatic methods for generating state-of-the-art neural network architectures without human experts have generated significant attention recently. This is because of the potential to remove human experts from the design loop which can reduce costs and decrease time to model deployment. Neural architecture search (NAS) techniques have improved significantly in their computational efficiency since the original NAS was proposed. This reduction in computation is enabled via weight sharing such as in Efficient Neural Architecture Search (ENAS). However, recently a body of work confirms our discovery that ENAS does not do significantly better than random search with weight sharing, contradicting the initial claims of the authors. We provide an explanation for this phenomenon by investigating the interpretability of the ENAS controller's hidden state. We are interested in seeing if the controller embeddings are predictive of any properties of the final architecture - for example, graph properties like the number of connections, or validation performance. We find models sampled from identical controller hidden states have no correlation in various graph similarity metrics. This failure mode implies the RNN controller does not condition on past architecture choices. Importantly, we may need to condition on past choices if certain connection patterns prevent vanishing or exploding gradients. Lastly, we propose a solution to this failure mode by forcing the controller's hidden state to encode pasts decisions by training it with a memory buffer of previously sampled architectures. Doing this improves hidden state interpretability by increasing the correlation controller hidden states and graph similarity metrics.