 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Ensemble Robustness Against Adversarial Attacks
Paper and Code
May 12, 2020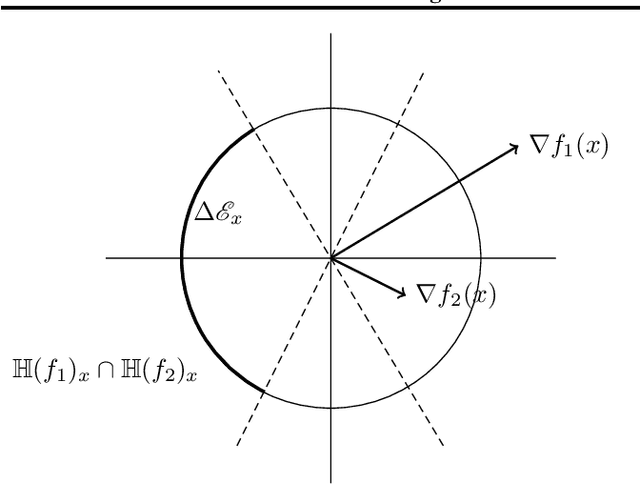


Adversarial examples, which are slightly perturbed inputs generated with the aim of fooling a neural network, are known to transfer between models; adversaries which are effective on one model will often fool another. This concept of transferability poses grave security concerns as it leads to the possibility of attacking models in a black box setting, during which the internal parameters of the target model are unknown. In this paper, we seek to analyze and minimize the transferability of adversaries between models within an ensemble. To this end, we introduce a gradient based measure of how effectively an ensemble's constituent models collaborate to reduce the space of adversarial examples targeting the ensemble itself. Furthermore, we demonstrate that this measure can be utilized during training as to increase an ensemble's robustness to adversarial examples.