 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePERTINENCE: Input-based Opportunistic Neural Network Dynamic Execution
Jul 02, 2025Deep neural networks (DNNs) have become ubiquitous thanks to their remarkable ability to model complex patterns across various domains such as computer vision, speech recognition, robotics, etc. While large DNN models are often more accurate than simpler, lightweight models, they are also resource- and energy-hungry. Hence, it is imperative to design methods to reduce reliance on such large models without significant degradation in output accuracy. The high computational cost of these models is often necessary only for a reduced set of challenging inputs, while lighter models can handle most simple ones. Thus, carefully combining properties of existing DNN models in a dynamic, input-based way opens opportunities to improve efficiency without impacting accuracy. In this work, we introduce PERTINENCE, a novel online method designed to analyze the complexity of input features and dynamically select the most suitable model from a pre-trained set to process a given input effectively. To achieve this, we employ a genetic algorithm to explore the training space of an ML-based input dispatcher, enabling convergence towards the Pareto front in the solution space that balances overall accuracy and computational efficiency. We showcase our approach on state-of-the-art Convolutional Neural Networks (CNNs) trained on the CIFAR-10 and CIFAR-100, as well as Vision Transformers (ViTs) trained on TinyImageNet dataset. We report results showing PERTINENCE's ability to provide alternative solutions to existing state-of-the-art models in terms of trade-offs between accuracy and number of operations. By opportunistically selecting among models trained for the same task, PERTINENCE achieves better or comparable accuracy with up to 36% fewer operations.
High-Throughput CNN Inference on Embedded ARM big.LITTLE Multi-Core Processors
Mar 14, 2019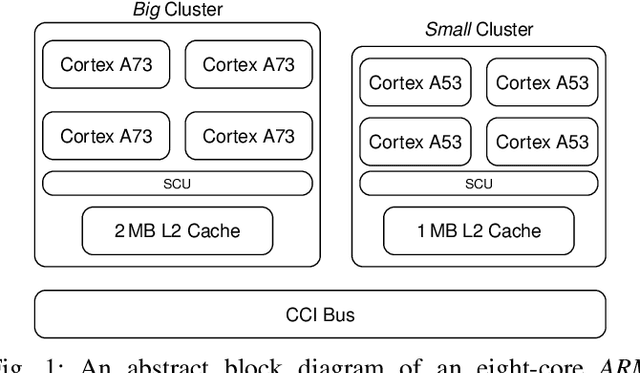

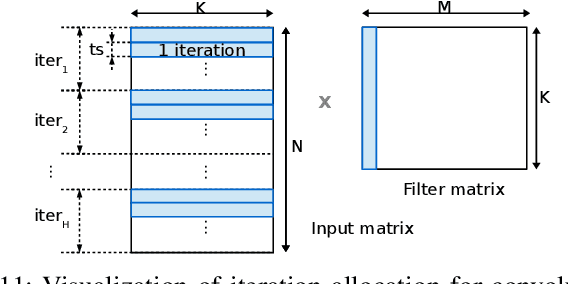
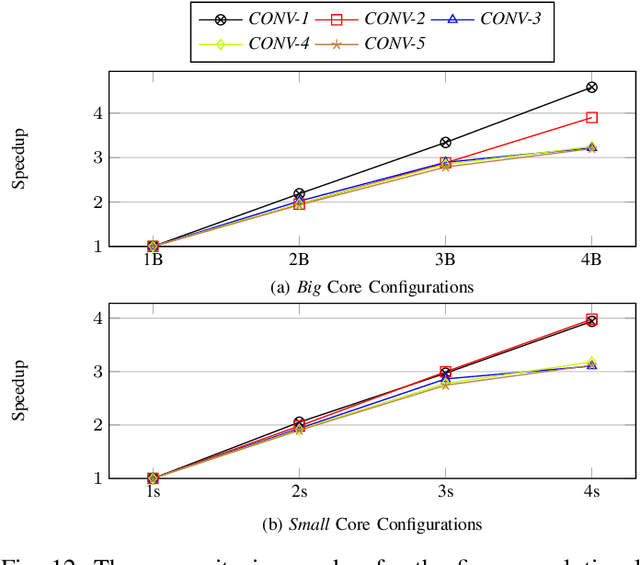
IoT Edge intelligence requires Convolutional Neural Network (CNN) inference to take place in the edge device itself. ARM big.LITTLE architecture is at the heart of common commercial edge devices. It comprises of single-ISA heterogeneous multi-cores grouped in homogeneous clusters that enables performance and power trade-offs. However, high communication overhead involved in parallelization of computation from a convolution kernel across clusters is detrimental to throughput. We present an alternative framework called Pipe-it that employs a pipelined design to split the convolutional layers across clusters while limiting the parallelization of their respective kernels to the assigned clusters. We develop a performance prediction model that, from convolutional layer descriptors, predicts the execution time of each layer individually on all different core types and number of cores. Pipe-it then exploits the predictions to create a balanced pipeline using an efficient design space exploration algorithm. Pipe-it on average results in 39% higher throughput than the highest antecedent throughput.