 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs
Aug 24, 2025



We introduce MMCRICBENCH-3K, a benchmark for Visual Question Answering (VQA) on cricket scorecards, designed to evaluate large vision-language models (LVLMs) on complex numerical and cross-lingual reasoning over semi-structured tabular images. MMCRICBENCH-3K comprises 1,463 synthetically generated scorecard images from ODI, T20, and Test formats, accompanied by 1,500 English QA pairs. It includes two subsets: MMCRICBENCH-E-1.5K, featuring English scorecards, and MMCRICBENCH-H-1.5K, containing visually similar Hindi scorecards, with all questions and answers kept in English to enable controlled cross-script evaluation. The task demands reasoning over structured numerical data, multi-image context, and implicit domain knowledge. Empirical results show that even state-of-the-art LVLMs, such as GPT-4o and Qwen2.5VL, struggle on the English subset despite it being their primary training language and exhibit a further drop in performance on the Hindi subset. This reveals key limitations in structure-aware visual text understanding, numerical reasoning, and cross-lingual generalization. The dataset is publicly available via Hugging Face at https://huggingface.co/datasets/DIALab/MMCricBench, to promote LVLM research in this direction.
TransDocAnalyser: A Framework for Offline Semi-structured Handwritten Document Analysis in the Legal Domain
Jun 03, 2023State-of-the-art offline Optical Character Recognition (OCR) frameworks perform poorly on semi-structured handwritten domain-specific documents due to their inability to localize and label form fields with domain-specific semantics. Existing techniques for semi-structured document analysis have primarily used datasets comprising invoices, purchase orders, receipts, and identity-card documents for benchmarking. In this work, we build the first semi-structured document analysis dataset in the legal domain by collecting a large number of First Information Report (FIR) documents from several police stations in India. This dataset, which we call the FIR dataset, is more challenging than most existing document analysis datasets, since it combines a wide variety of handwritten text with printed text. We also propose an end-to-end framework for offline processing of handwritten semi-structured documents, and benchmark it on our novel FIR dataset. Our framework used Encoder-Decoder architecture for localizing and labelling the form fields and for recognizing the handwritten content. The encoder consists of Faster-RCNN and Vision Transformers. Further the Transformer-based decoder architecture is trained with a domain-specific tokenizer. We also propose a post-correction method to handle recognition errors pertaining to the domain-specific terms. Our proposed framework achieves state-of-the-art results on the FIR dataset outperforming several existing models
External Knowledge Augmented Text Visual Question Answering
Aug 22, 2021
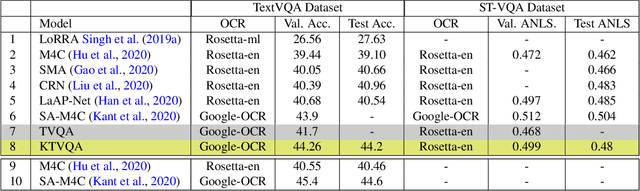
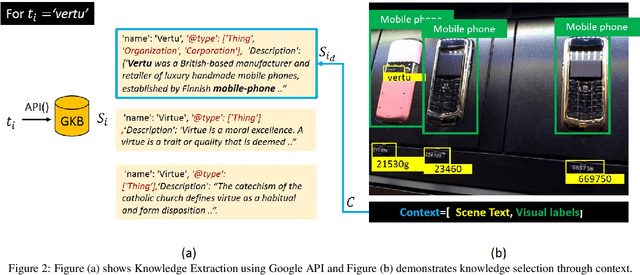
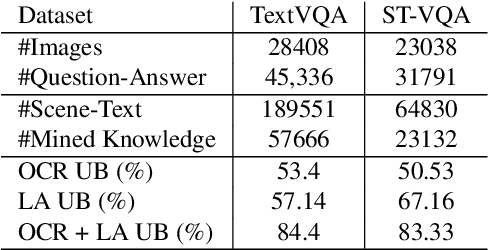
The open-ended question answering task of Text-VQA requires reading and reasoning about local, often previously unseen, scene-text content of an image to generate answers. In this work, we propose the generalized use of external knowledge to augment our understanding of the said scene-text. We design a framework to extract, filter, and encode knowledge atop a standard multimodal transformer for vision language understanding tasks. Through empirical evidence, we demonstrate how knowledge can highlight instance-only cues and thus help deal with training data bias, improve answer entity type correctness, and detect multiword named entities. We generate results comparable to the state-of-the-art on two publicly available datasets, under the constraints of similar upstream OCR systems and training data.
Action Quality Assessment using Siamese Network-Based Deep Metric Learning
Feb 27, 2020
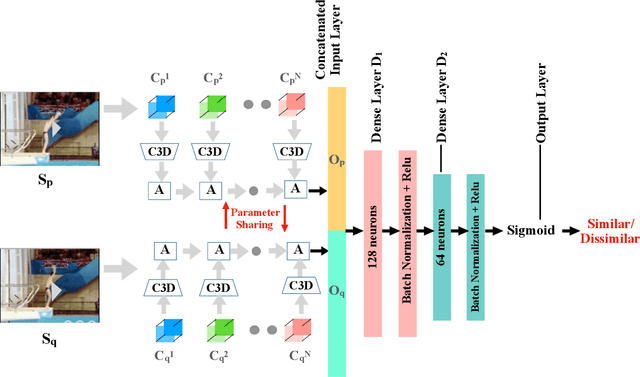

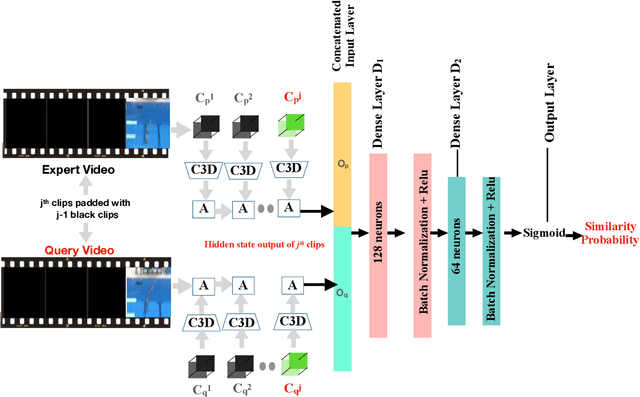
Automated vision-based score estimation models can be used as an alternate opinion to avoid judgment bias. In the past works the score estimation models were learned by regressing the video representations to the ground truth score provided by the judges. However such regression-based solutions lack interpretability in terms of giving reasons for the awarded score. One solution to make the scores more explicable is to compare the given action video with a reference video. This would capture the temporal variations w.r.t. the reference video and map those variations to the final score. In this work, we propose a new action scoring system as a two-phase system: (1) A Deep Metric Learning Module that learns similarity between any two action videos based on their ground truth scores given by the judges; (2) A Score Estimation Module that uses the first module to find the resemblance of a video to a reference video in order to give the assessment score. The proposed scoring model has been tested for Olympics Diving and Gymnastic vaults and the model outperforms the existing state-of-the-art scoring models.
An Interactive Medical Image Segmentation Framework Using Iterative Refinement
Jun 05, 2016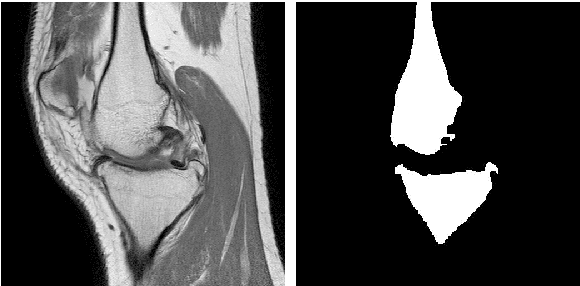
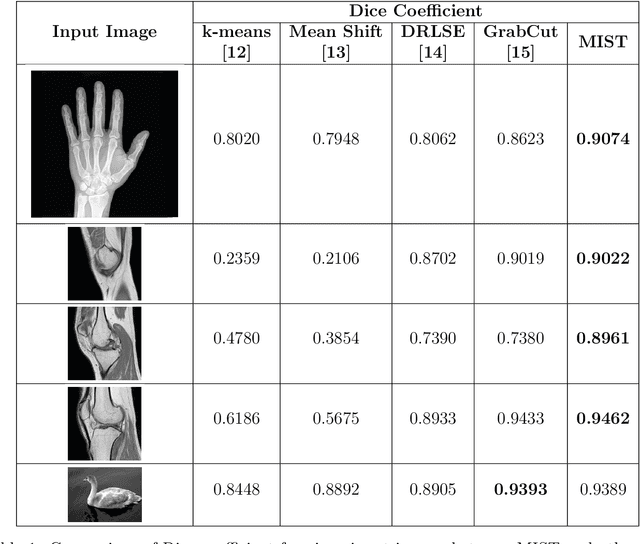
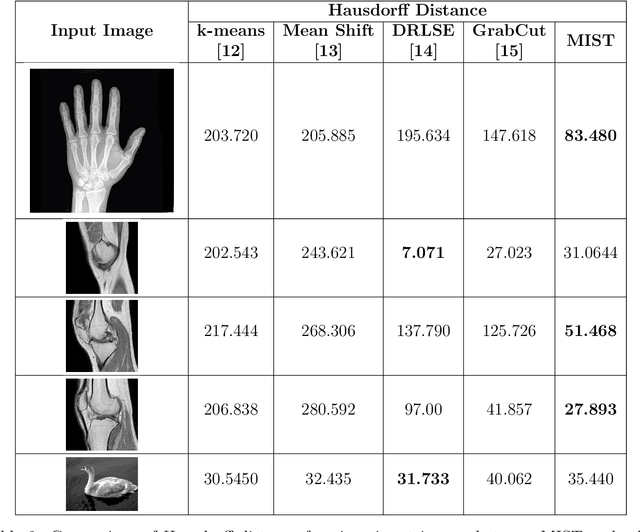
Image segmentation is often performed on medical images for identifying diseases in clinical evaluation. Hence it has become one of the major research areas. Conventional image segmentation techniques are unable to provide satisfactory segmentation results for medical images as they contain irregularities. They need to be pre-processed before segmentation. In order to obtain the most suitable method for medical image segmentation, we propose a two stage algorithm. The first stage automatically generates a binary marker image of the region of interest using mathematical morphology. This marker serves as the mask image for the second stage which uses GrabCut on the input image thus resulting in an efficient segmented result. The obtained result can be further refined by user interaction which can be done using the Graphical User Interface (GUI). Experimental results show that the proposed method is accurate and provides satisfactory segmentation results with minimum user interaction on medical as well as natural images.
Topographic Feature Extraction for Bengali and Hindi Character Images
Jul 14, 2011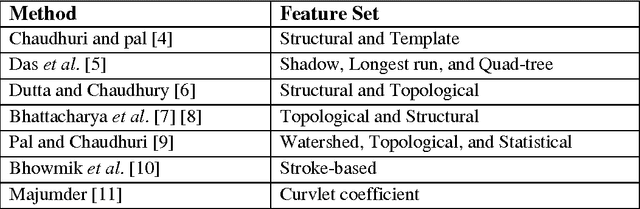

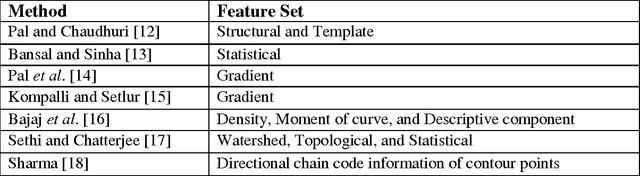
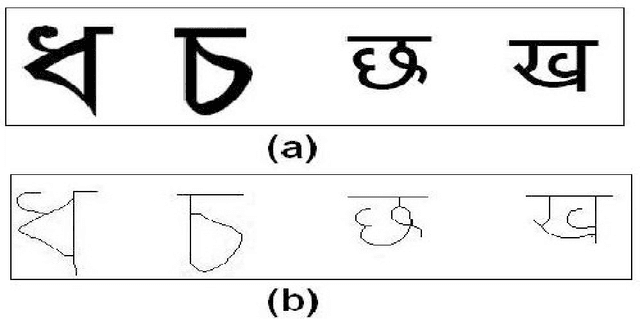
Feature selection and extraction plays an important role in different classification based problems such as face recognition, signature verification, optical character recognition (OCR) etc. The performance of OCR highly depends on the proper selection and extraction of feature set. In this paper, we present novel features based on the topography of a character as visible from different viewing directions on a 2D plane. By topography of a character we mean the structural features of the strokes and their spatial relations. In this work we develop topographic features of strokes visible with respect to views from different directions (e.g. North, South, East, and West). We consider three types of topographic features: closed region, convexity of strokes, and straight line strokes. These features are represented as a shape-based graph which acts as an invariant feature set for discriminating very similar type characters efficiently. We have tested the proposed method on printed and handwritten Bengali and Hindi character images. Initial results demonstrate the efficacy of our approach.
A Medial Axis Based Thinning Strategy for Character Images
Mar 03, 2011

Thinning of character images is a big challenge. Removal of strokes or deformities in thinning is a difficult problem. In this paper, we have proposed a medial axis based thinning strategy used for performing skeletonization of printed and handwritten character images. In this method, we have used shape characteristics of text to get skeleton of nearly same as the true character shape. This approach helps to preserve the local features and true shape of the character images. The proposed algorithm produces one pixel width thin skeleton. As a by-product of our thinning approach, the skeleton also gets segmented into strokes in vector form. Hence further stroke segmentation is not required. Experiment is done on printed English and Bengali characters and we obtain less spurious branches comparing with other thinning methods without any post processing.