 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeqa-FLoRA: Data-free query-adaptive Fusion of LoRAs for LLMs
Dec 12, 2025


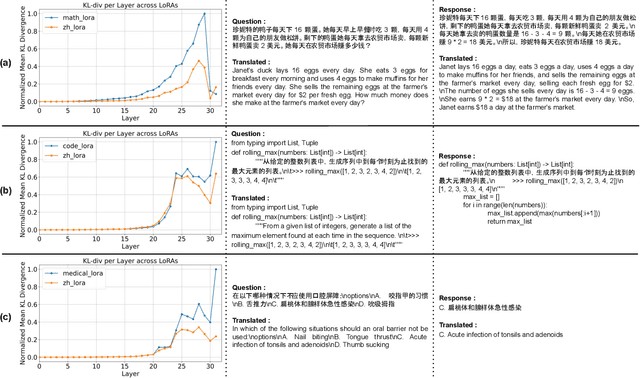
The deployment of large language models for specialized tasks often requires domain-specific parameter-efficient finetuning through Low-Rank Adaptation (LoRA) modules. However, effectively fusing these adapters to handle complex, multi-domain composite queries remains a critical challenge. Existing LoRA fusion approaches either use static weights, which assign equal relevance to each participating LoRA, or require data-intensive supervised training for every possible LoRA combination to obtain respective optimal fusion weights. We propose qa-FLoRA, a novel query-adaptive data-and-training-free method for LoRA fusion that dynamically computes layer-level fusion weights by measuring distributional divergence between the base model and respective adapters. Our approach eliminates the need for composite training data or domain-representative samples, making it readily applicable to existing adapter collections. Extensive experiments across nine multilingual composite tasks spanning mathematics, coding, and medical domains, show that qa-FLoRA outperforms static fusion by ~5% with LLaMA-2 and ~6% with LLaMA-3, and the training-free baselines by ~7% with LLaMA-2 and ~10% with LLaMA-3, while significantly closing the gap with supervised baselines. Further, layer-level analysis of our fusion weights reveals interpretable fusion patterns, demonstrating the effectiveness of our approach for robust multi-domain adaptation.
Action Quality Assessment using Siamese Network-Based Deep Metric Learning
Feb 27, 2020
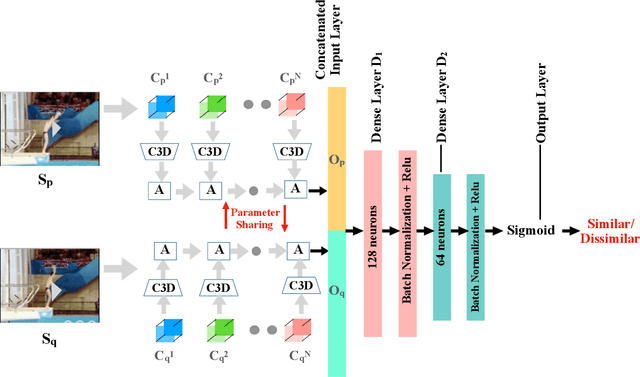

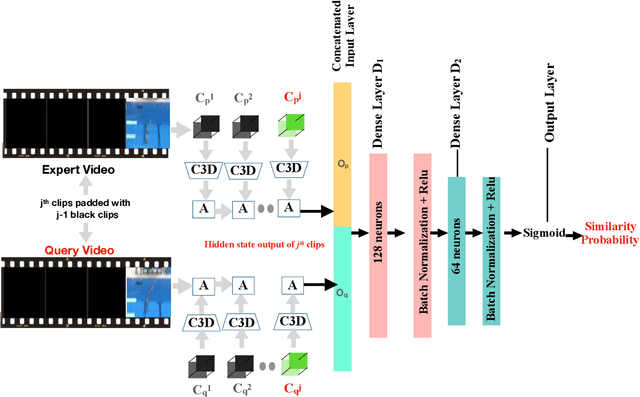
Automated vision-based score estimation models can be used as an alternate opinion to avoid judgment bias. In the past works the score estimation models were learned by regressing the video representations to the ground truth score provided by the judges. However such regression-based solutions lack interpretability in terms of giving reasons for the awarded score. One solution to make the scores more explicable is to compare the given action video with a reference video. This would capture the temporal variations w.r.t. the reference video and map those variations to the final score. In this work, we propose a new action scoring system as a two-phase system: (1) A Deep Metric Learning Module that learns similarity between any two action videos based on their ground truth scores given by the judges; (2) A Score Estimation Module that uses the first module to find the resemblance of a video to a reference video in order to give the assessment score. The proposed scoring model has been tested for Olympics Diving and Gymnastic vaults and the model outperforms the existing state-of-the-art scoring models.