 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPPL: Adaptive Planner Parameter Learning
May 17, 2021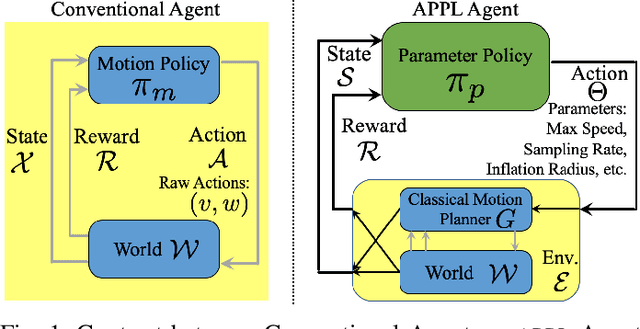

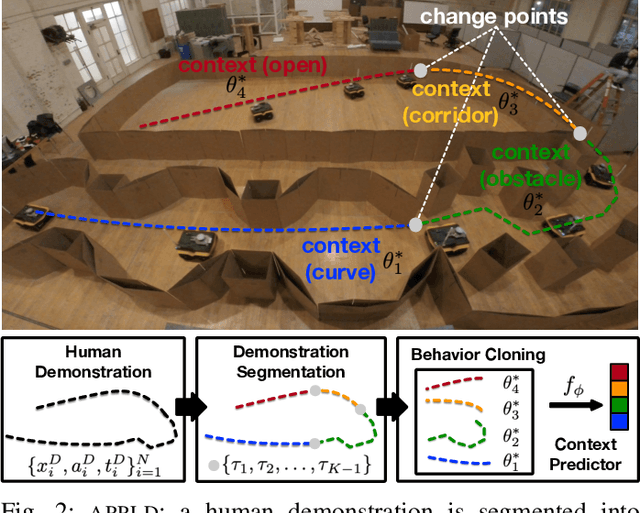
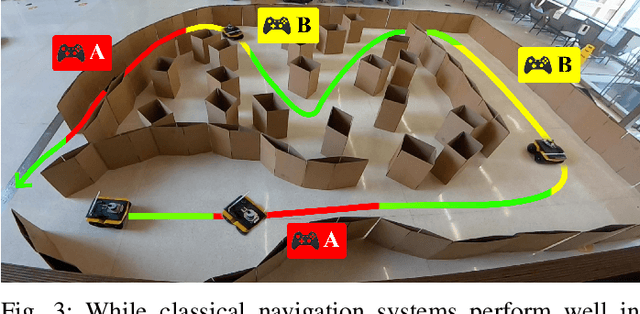
While current autonomous navigation systems allow robots to successfully drive themselves from one point to another in specific environments, they typically require extensive manual parameter re-tuning by human robotics experts in order to function in new environments. Furthermore, even for just one complex environment, a single set of fine-tuned parameters may not work well in different regions of that environment. These problems prohibit reliable mobile robot deployment by non-expert users. As a remedy, we propose Adaptive Planner Parameter Learning (APPL), a machine learning framework that can leverage non-expert human interaction via several modalities -- including teleoperated demonstrations, corrective interventions, and evaluative feedback -- and also unsupervised reinforcement learning to learn a parameter policy that can dynamically adjust the parameters of classical navigation systems in response to changes in the environment. APPL inherits safety and explainability from classical navigation systems while also enjoying the benefits of machine learning, i.e., the ability to adapt and improve from experience. We present a suite of individual APPL methods and also a unifying cycle-of-learning scheme that combines all the proposed methods in a framework that can improve navigation performance through continual, iterative human interaction and simulation training.
APPLR: Adaptive Planner Parameter Learning from Reinforcement
Nov 01, 2020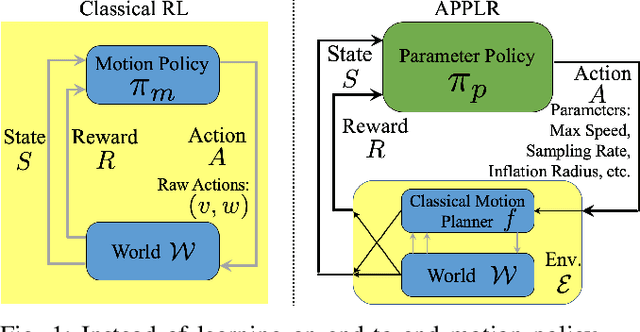

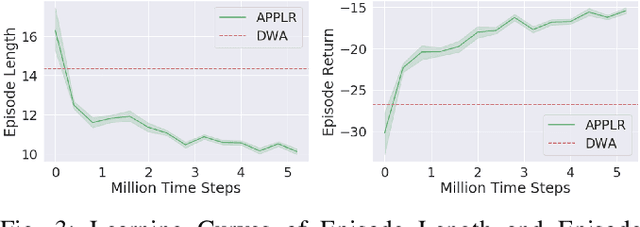
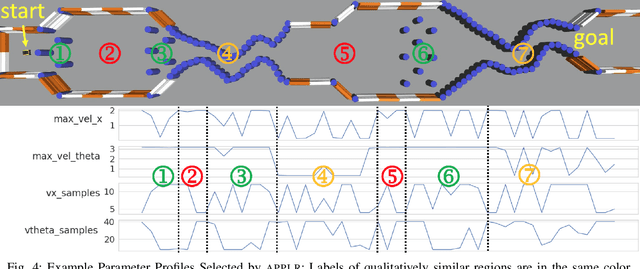
Classical navigation systems typically operate using a fixed set of hand-picked parameters (e.g. maximum speed, sampling rate, inflation radius, etc.) and require heavy expert re-tuning in order to work in new environments. To mitigate this requirement, it has been proposed to learn parameters for different contexts in a new environment using human demonstrations collected via teleoperation. However, learning from human demonstration limits deployment to the training environment, and limits overall performance to that of a potentially-suboptimal demonstrator. In this paper, we introduce APPLR, Adaptive Planner Parameter Learning from Reinforcement, which allows existing navigation systems to adapt to new scenarios by using a parameter selection scheme discovered via reinforcement learning (RL) in a wide variety of simulation environments. We evaluate APPLR on a robot in both simulated and physical experiments, and show that it can outperform both a fixed set of hand-tuned parameters and also a dynamic parameter tuning scheme learned from human demonstration.