 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIMBA: An Open-Source Framework for the Preservation and Valorization of Low-Resource Languages using Generative Models
Nov 20, 2024

Minority languages are vital to preserving cultural heritage, yet they face growing risks of extinction due to limited digital resources and the dominance of artificial intelligence models trained on high-resource languages. This white paper proposes a framework to generate linguistic tools for low-resource languages, focusing on data creation to support the development of language models that can aid in preservation efforts. Sardinian, an endangered language, serves as the case study to demonstrate the framework's effectiveness. By addressing the data scarcity that hinders intelligent applications for such languages, we contribute to promoting linguistic diversity and support ongoing efforts in language standardization and revitalization through modern technologies.
Impact of the COVID-19 outbreak on Italy's country reputation and stock market performance: a sentiment analysis approach
Mar 13, 2021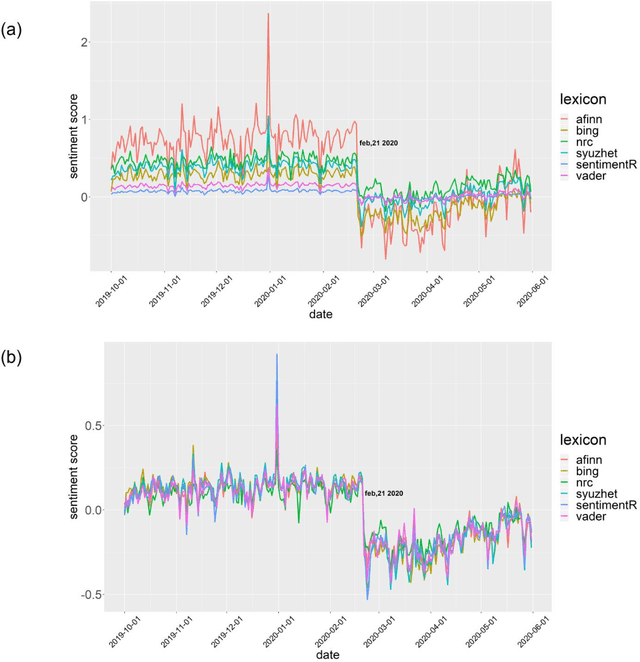
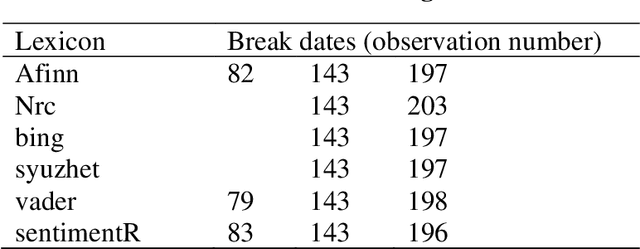
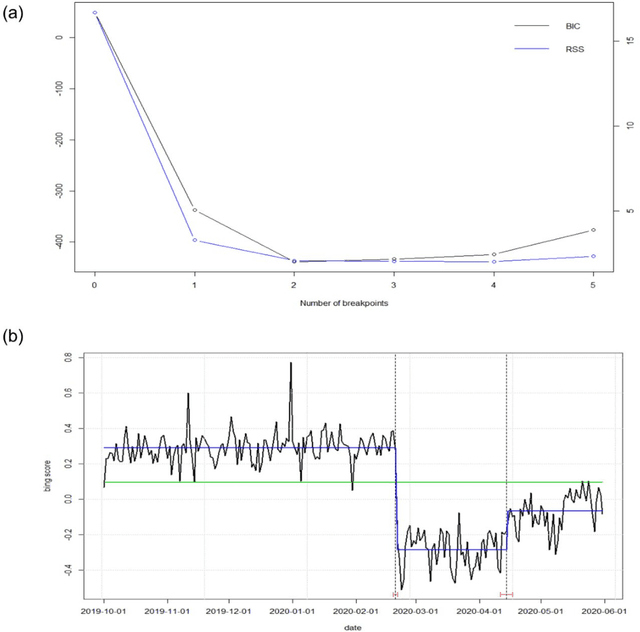
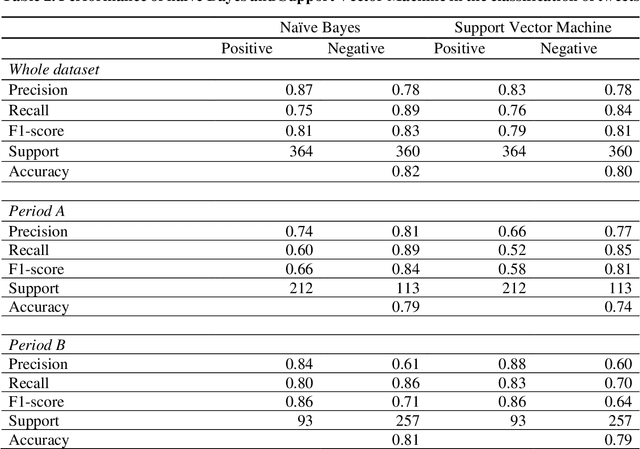
During the recent Coronavirus disease 2019 (COVID-19) outbreak, the microblogging service Twitter has been widely used to share opinions and reactions to events. Italy was one of the first European countries to be severely affected by the outbreak and to establish lockdown and stay-at-home orders, potentially leading to country reputation damage. We resort to sentiment analysis to investigate changes in opinions about Italy reported on Twitter before and after the COVID-19 outbreak. Using different lexicons-based methods, we find a breakpoint corresponding to the date of the first established case of COVID-19 in Italy that causes a relevant change in sentiment scores used as proxy of the country reputation. Next, we demonstrate that sentiment scores about Italy are strongly associated with the levels of the FTSE-MIB index, the Italian Stock Exchange main index, as they serve as early detection signals of changes in the values of FTSE-MIB. Finally, we make a content-based classification of tweets into positive and negative and use two machine learning classifiers to validate the assigned polarity of tweets posted before and after the outbreak.