 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Model Uncertainty via Optimal Design of Experiments applied to a Mechanical Press
Oct 18, 2019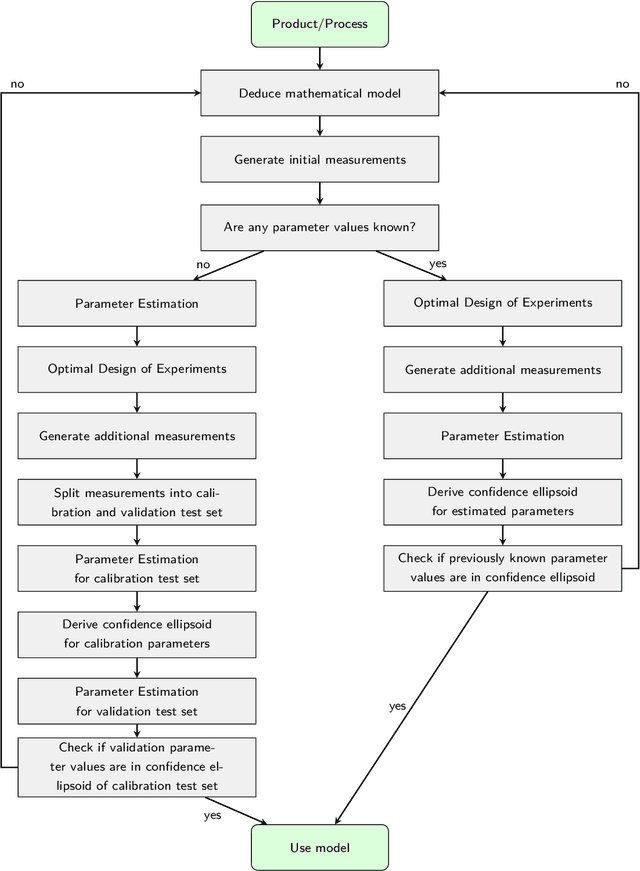
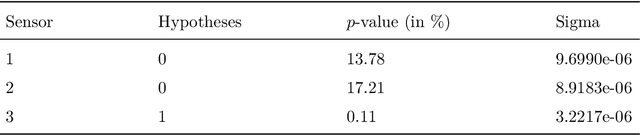
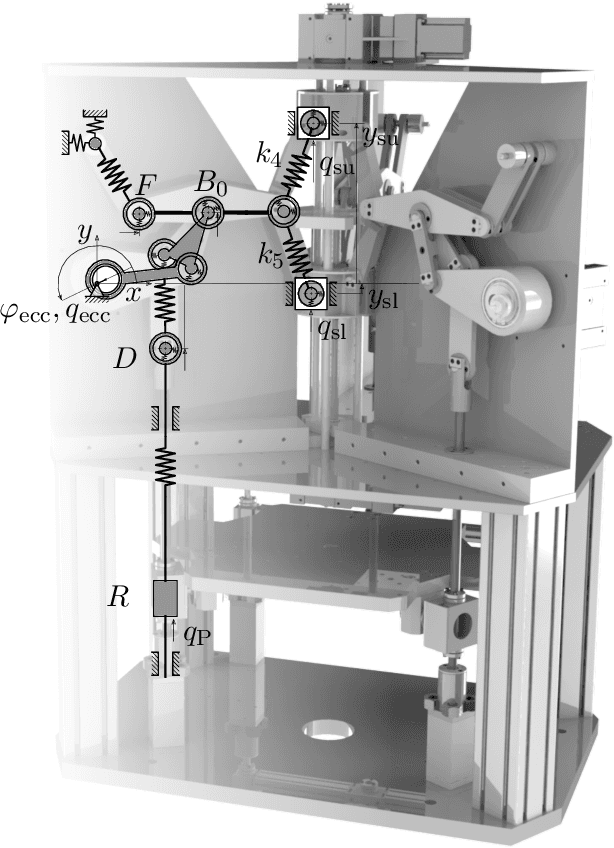

In engineering applications almost all processes are described with the aid of models. Especially forming machines heavily rely on mathematical models for control and condition monitoring. Inaccuracies during the modeling, manufacturing and assembly of these machines induce model uncertainty which impairs the controller's performance. In this paper we propose an approach to identify model uncertainty using parameter identification and optimal design of experiments. The experimental setup is characterized by optimal sensor positions such that specific model parameters can be determined with minimal variance. This allows for the computation of confidence regions, in which the real parameters or the parameter estimates from different test sets have to lie. We claim that inconsistencies in the estimated parameter values, considering their approximated confidence ellipsoids as well, cannot be explained by data or parameter uncertainty but are indicators of model uncertainty. The proposed method is demonstrated using a component of the 3D Servo Press, a multi-technology forming machine that combines spindles with eccentric servo drives.
The "something something" video database for learning and evaluating visual common sense
Jun 15, 2017
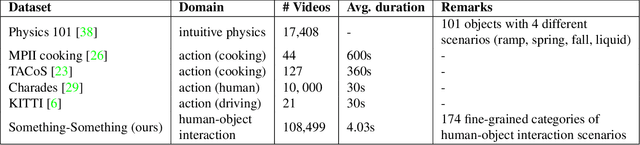

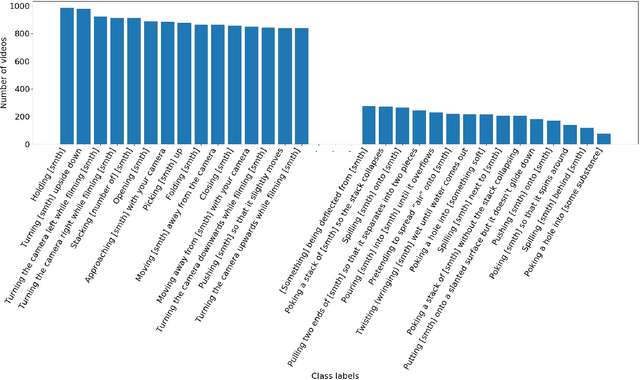
Neural networks trained on datasets such as ImageNet have led to major advances in visual object classification. One obstacle that prevents networks from reasoning more deeply about complex scenes and situations, and from integrating visual knowledge with natural language, like humans do, is their lack of common sense knowledge about the physical world. Videos, unlike still images, contain a wealth of detailed information about the physical world. However, most labelled video datasets represent high-level concepts rather than detailed physical aspects about actions and scenes. In this work, we describe our ongoing collection of the "something-something" database of video prediction tasks whose solutions require a common sense understanding of the depicted situation. The database currently contains more than 100,000 videos across 174 classes, which are defined as caption-templates. We also describe the challenges in crowd-sourcing this data at scale.