 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEGEN: Sample-Ensemble Genetic Evolutional Network Model
Jun 05, 2018

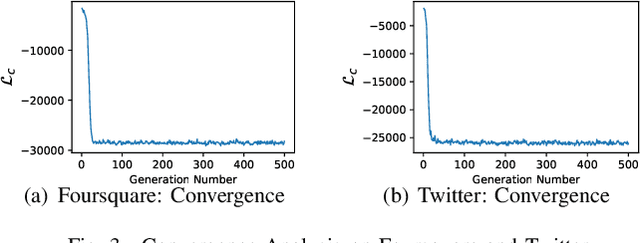

Deep learning, a rebranding of deep neural network research works, has achieved a remarkable success in recent years. With multiple hidden layers, deep learning models aim at computing the hierarchical feature representations of the observational data. Meanwhile, due to its severe disadvantages in data consumption, computational resources, parameter tuning costs and the lack of result explainability, deep learning has also suffered from lots of criticism. In this paper, we will introduce a new representation learning model, namely "Sample-Ensemble Genetic Evolutionary Network" (SEGEN), which can serve as an alternative approach to deep learning models. Instead of building one single deep model, based on a set of sampled sub-instances, SEGEN adopts a genetic-evolutionary learning strategy to build a group of unit models generations by generations. The unit models incorporated in SEGEN can be either traditional machine learning models or the recent deep learning models with a much "narrower" and "shallower" architecture. The learning results of each instance at the final generation will be effectively combined from each unit model via diffusive propagation and ensemble learning strategies. From the computational perspective, SEGEN requires far less data, fewer computational resources and parameter tuning efforts, but has sound theoretic interpretability of the learning process and results. Extensive experiments have been done on several different real-world benchmark datasets, and the experimental results obtained by SEGEN have demonstrated its advantages over the state-of-the-art representation learning models.
Fake News Detection with Deep Diffusive Network Model
May 22, 2018


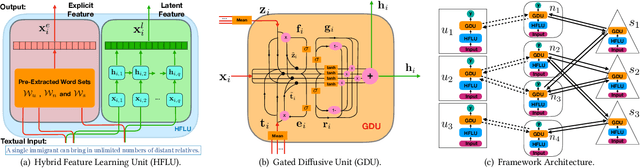
In recent years, due to the booming development of online social networks, fake news for various commercial and political purposes has been appearing in large numbers and widespread in the online world. With deceptive words, online social network users can get infected by these online fake news easily, which has brought about tremendous effects on the offline society already. An important goal in improving the trustworthiness of information in online social networks is to identify the fake news timely. This paper aims at investigating the principles, methodologies and algorithms for detecting fake news articles, creators and subjects from online social networks and evaluating the corresponding performance. This paper addresses the challenges introduced by the unknown characteristics of fake news and diverse connections among news articles, creators and subjects. Based on a detailed data analysis, this paper introduces a novel automatic fake news credibility inference model, namely FakeDetector. Based on a set of explicit and latent features extracted from the textual information, FakeDetector builds a deep diffusive network model to learn the representations of news articles, creators and subjects simultaneously. Extensive experiments have been done on a real-world fake news dataset to compare FakeDetector with several state-of-the-art models, and the experimental results have demonstrated the effectiveness of the proposed model.
EgoCoder: Intelligent Program Synthesis with Hierarchical Sequential Neural Network Model
May 22, 2018

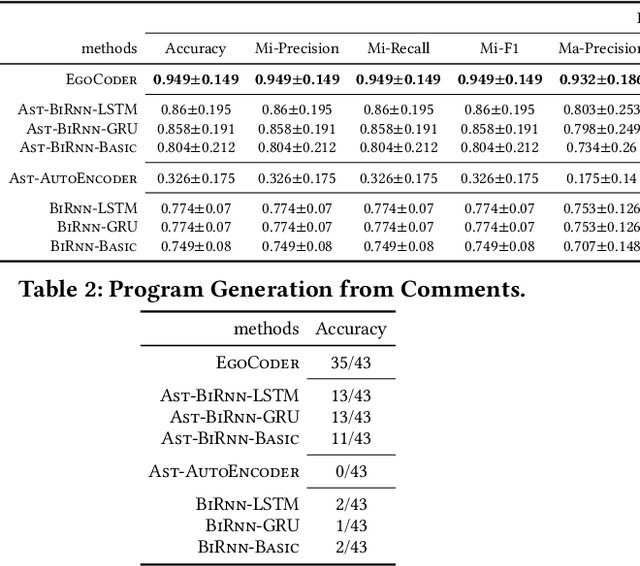

Programming has been an important skill for researchers and practitioners in computer science and other related areas. To learn basic programing skills, a long-time systematic training is usually required for beginners. According to a recent market report, the computer software market is expected to continue expanding at an accelerating speed, but the market supply of qualified software developers can hardly meet such a huge demand. In recent years, the surge of text generation research works provides the opportunities to address such a dilemma through automatic program synthesis. In this paper, we propose to make our try to solve the program synthesis problem from a data mining perspective. To address the problem, a novel generative model, namely EgoCoder, will be introduced in this paper. EgoCoder effectively parses program code into abstract syntax trees (ASTs), where the tree nodes will contain the program code/comment content and the tree structure can capture the program logic flows. Based on a new unit model called Hsu, EgoCoder can effectively capture both the hierarchical and sequential patterns in the program ASTs. Extensive experiments will be done to compare EgoCoder with the state-of-the-art text generation methods, and the experimental results have demonstrated the effectiveness of EgoCoder in addressing the program synthesis problem.
GEN Model: An Alternative Approach to Deep Neural Network Models
May 19, 2018



In this paper, we introduce an alternative approach, namely GEN (Genetic Evolution Network) Model, to the deep learning models. Instead of building one single deep model, GEN adopts a genetic-evolutionary learning strategy to build a group of unit models generations by generations. Significantly different from the wellknown representation learning models with extremely deep structures, the unit models covered in GEN are of a much shallower architecture. In the training process, from each generation, a subset of unit models will be selected based on their performance to evolve and generate the child models in the next generation. GEN has significant advantages compared with existing deep representation learning models in terms of both learning effectiveness, efficiency and interpretability of the learning process and learned results. Extensive experiments have been done on diverse benchmark datasets, and the experimental results have demonstrated the outstanding performance of GEN compared with the state-of-the-art baseline methods in both effectiveness of efficiency.
Reconciled Polynomial Machine: A Unified Representation of Shallow and Deep Learning Models
May 19, 2018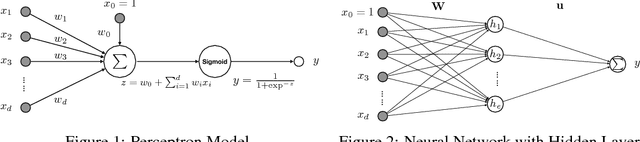
In this paper, we aim at introducing a new machine learning model, namely reconciled polynomial machine, which can provide a unified representation of existing shallow and deep machine learning models. Reconciled polynomial machine predicts the output by computing the inner product of the feature kernel function and variable reconciling function. Analysis of several concrete models, including Linear Models, FM, MVM, Perceptron, MLP and Deep Neural Networks, will be provided in this paper, which can all be reduced to the reconciled polynomial machine representations. Detailed analysis of the learning error by these models will also be illustrated in this paper based on their reduced representations from the function approximation perspective.
Deep Loopy Neural Network Model for Graph Structured Data Representation Learning
May 19, 2018



Existing deep learning models may encounter great challenges in handling graph structured data. In this paper, we introduce a new deep learning model for graph data specifically, namely the deep loopy neural network. Significantly different from the previous deep models, inside the deep loopy neural network, there exist a large number of loops created by the extensive connections among nodes in the input graph data, which makes model learning an infeasible task. To resolve such a problem, in this paper, we will introduce a new learning algorithm for the deep loopy neural network specifically. Instead of learning the model variables based on the original model, in the proposed learning algorithm, errors will be back-propagated through the edges in a group of extracted spanning trees. Extensive numerical experiments have been done on several real-world graph datasets, and the experimental results demonstrate the effectiveness of both the proposed model and the learning algorithm in handling graph data.
On Deep Ensemble Learning from a Function Approximation Perspective
May 19, 2018
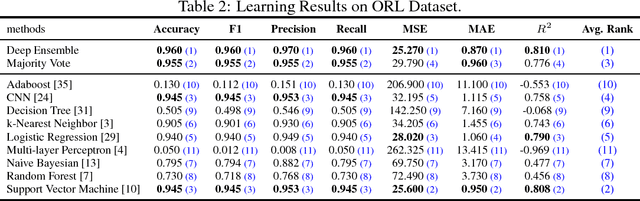

In this paper, we propose to provide a general ensemble learning framework based on deep learning models. Given a group of unit models, the proposed deep ensemble learning framework will effectively combine their learning results via a multilayered ensemble model. In the case when the unit model mathematical mappings are bounded, sigmoidal and discriminatory, we demonstrate that the deep ensemble learning framework can achieve a universal approximation of any functions from the input space to the output space. Meanwhile, to achieve such a performance, the deep ensemble learning framework also impose a strict constraint on the number of involved unit models. According to the theoretic proof provided in this paper, given the input feature space of dimension d, the required unit model number will be 2d, if the ensemble model involves one single layer. Furthermore, as the ensemble component goes deeper, the number of required unit model is proved to be lowered down exponentially.
GADAM: Genetic-Evolutionary ADAM for Deep Neural Network Optimization
May 19, 2018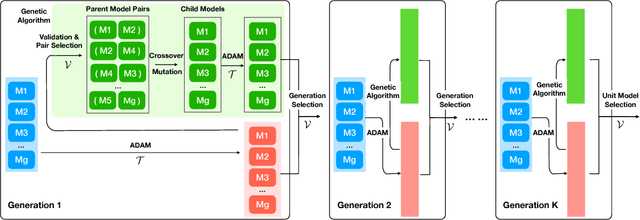
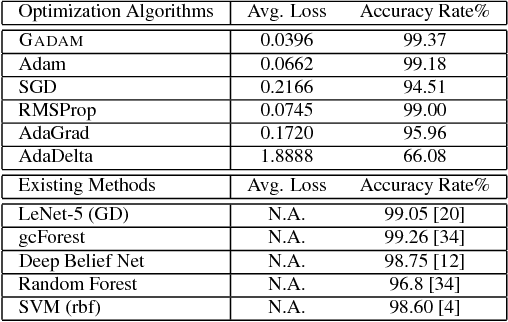

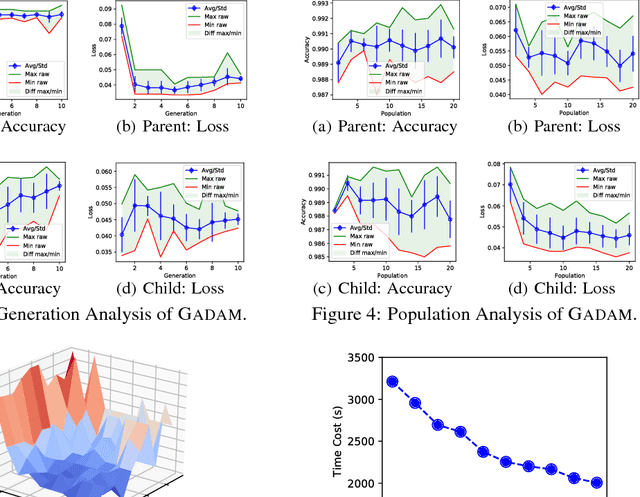
Deep neural network learning can be formulated as a non-convex optimization problem. Existing optimization algorithms, e.g., Adam, can learn the models fast, but may get stuck in local optima easily. In this paper, we introduce a novel optimization algorithm, namely GADAM (Genetic-Evolutionary Adam). GADAM learns deep neural network models based on a number of unit models generations by generations: it trains the unit models with Adam, and evolves them to the new generations with genetic algorithm. We will show that GADAM can effectively jump out of the local optima in the learning process to obtain better solutions, and prove that GADAM can also achieve a very fast convergence. Extensive experiments have been done on various benchmark datasets, and the learning results will demonstrate the effectiveness and efficiency of the GADAM algorithm.