 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratisation of Usable Machine Learning in Computer Vision
Feb 18, 2019

Many industries are now investing heavily in data science and automation to replace manual tasks and/or to help with decision making, especially in the realm of leveraging computer vision to automate many monitoring, inspection, and surveillance tasks. This has resulted in the emergence of the 'data scientist' who is conversant in statistical thinking, machine learning (ML), computer vision, and computer programming. However, as ML becomes more accessible to the general public and more aspects of ML become automated, applications leveraging computer vision are increasingly being created by non-experts with less opportunity for regulatory oversight. This points to the overall need for more educated responsibility for these lay-users of usable ML tools in order to mitigate potentially unethical ramifications. In this paper, we undertake a SWOT analysis to study the strengths, weaknesses, opportunities, and threats of building usable ML tools for mass adoption for important areas leveraging ML such as computer vision. The paper proposes a set of data science literacy criteria for educating and supporting lay-users in the responsible development and deployment of ML applications.
Incremental Transductive Learning Approaches to Schistosomiasis Vector Classification
Apr 06, 2017
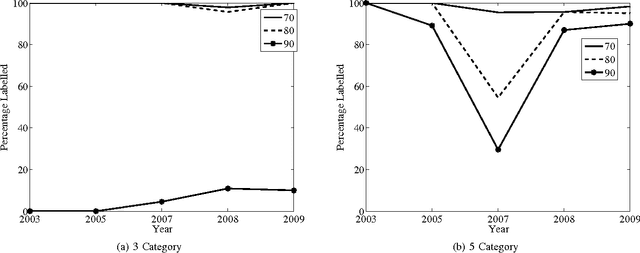

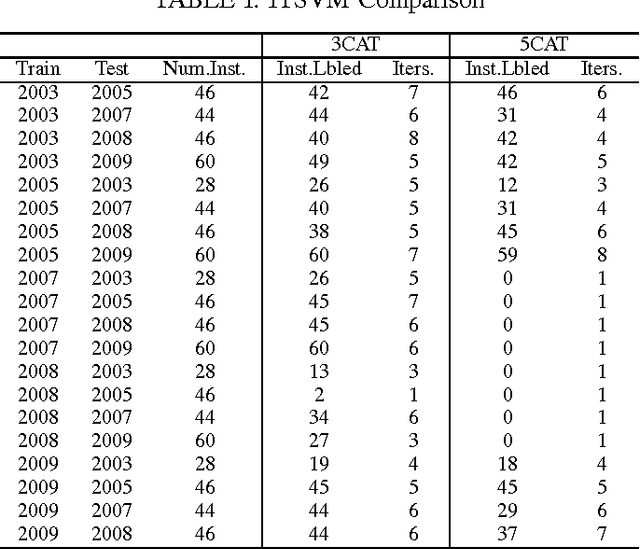
The key issues pertaining to collection of epidemic disease data for our analysis purposes are that it is a labour intensive, time consuming and expensive process resulting in availability of sparse sample data which we use to develop prediction models. To address this sparse data issue, we present novel Incremental Transductive methods to circumvent the data collection process by applying previously acquired data to provide consistent, confidence-based labelling alternatives to field survey research. We investigated various reasoning approaches for semisupervised machine learning including Bayesian models for labelling data. The results show that using the proposed methods, we can label instances of data with a class of vector density at a high level of confidence. By applying the Liberal and Strict Training Approaches, we provide a labelling and classification alternative to standalone algorithms. The methods in this paper are components in the process of reducing the proliferation of the Schistosomiasis disease and its effects.