 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminatively Boosted Image Clustering with Fully Convolutional Auto-Encoders
Mar 23, 2017


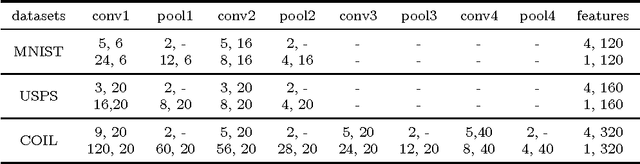
Traditional image clustering methods take a two-step approach, feature learning and clustering, sequentially. However, recent research results demonstrated that combining the separated phases in a unified framework and training them jointly can achieve a better performance. In this paper, we first introduce fully convolutional auto-encoders for image feature learning and then propose a unified clustering framework to learn image representations and cluster centers jointly based on a fully convolutional auto-encoder and soft $k$-means scores. At initial stages of the learning procedure, the representations extracted from the auto-encoder may not be very discriminative for latter clustering. We address this issue by adopting a boosted discriminative distribution, where high score assignments are highlighted and low score ones are de-emphasized. With the gradually boosted discrimination, clustering assignment scores are discriminated and cluster purities are enlarged. Experiments on several vision benchmark datasets show that our methods can achieve a state-of-the-art performance.
A Fast and Compact Saliency Score Regression Network Based on Fully Convolutional Network
Feb 24, 2017
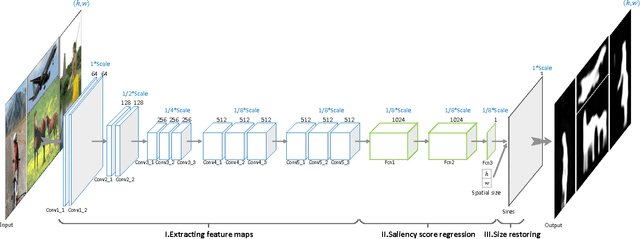

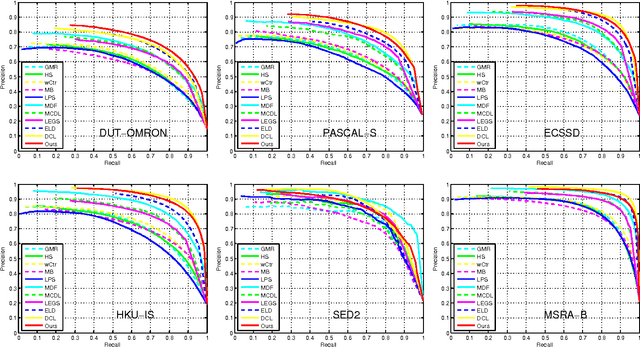
Visual saliency detection aims at identifying the most visually distinctive parts in an image, and serves as a pre-processing step for a variety of computer vision and image processing tasks. To this end, the saliency detection procedure must be as fast and compact as possible and optimally processes input images in a real time manner. It is an essential application requirement for the saliency detection task. However, contemporary detection methods often utilize some complicated procedures to pursue feeble improvements on the detection precession, which always take hundreds of milliseconds and make them not easy to be applied practically. In this paper, we tackle this problem by proposing a fast and compact saliency score regression network which employs fully convolutional network, a special deep convolutional neural network, to estimate the saliency of objects in images. It is an extremely simplified end-to-end deep neural network without any pre-processings and post-processings. When given an image, the network can directly predict a dense full-resolution saliency map (image-to-image prediction). It works like a compact pipeline which effectively simplifies the detection procedure. Our method is evaluated on six public datasets, and experimental results show that it can achieve comparable or better precision performance than the state-of-the-art methods while get a significant improvement in detection speed (35 FPS, processing in real time).
Effective Deterministic Initialization for $k$-Means-Like Methods via Local Density Peaks Searching
Nov 21, 2016
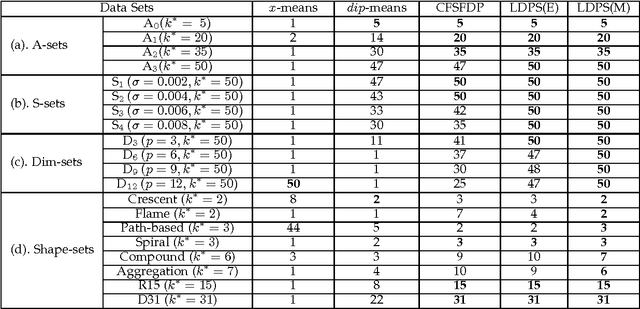
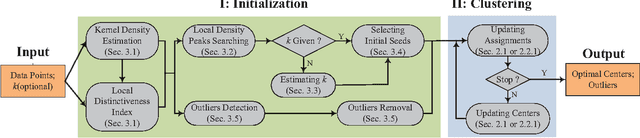

The $k$-means clustering algorithm is popular but has the following main drawbacks: 1) the number of clusters, $k$, needs to be provided by the user in advance, 2) it can easily reach local minima with randomly selected initial centers, 3) it is sensitive to outliers, and 4) it can only deal with well separated hyperspherical clusters. In this paper, we propose a Local Density Peaks Searching (LDPS) initialization framework to address these issues. The LDPS framework includes two basic components: one of them is the local density that characterizes the density distribution of a data set, and the other is the local distinctiveness index (LDI) which we introduce to characterize how distinctive a data point is compared with its neighbors. Based on these two components, we search for the local density peaks which are characterized with high local densities and high LDIs to deal with 1) and 2). Moreover, we detect outliers characterized with low local densities but high LDIs, and exclude them out before clustering begins. Finally, we apply the LDPS initialization framework to $k$-medoids, which is a variant of $k$-means and chooses data samples as centers, with diverse similarity measures other than the Euclidean distance to fix the last drawback of $k$-means. Combining the LDPS initialization framework with $k$-means and $k$-medoids, we obtain two novel clustering methods called LDPS-means and LDPS-medoids, respectively. Experiments on synthetic data sets verify the effectiveness of the proposed methods, especially when the ground truth of the cluster number $k$ is large. Further, experiments on several real world data sets, Handwritten Pendigits, Coil-20, Coil-100 and Olivetti Face Database, illustrate that our methods give a superior performance than the analogous approaches on both estimating $k$ and unsupervised object categorization.
Ternary Weight Networks
Nov 19, 2016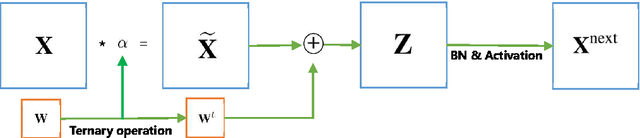
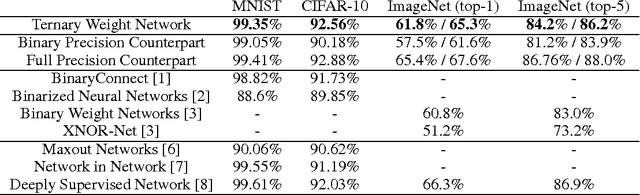
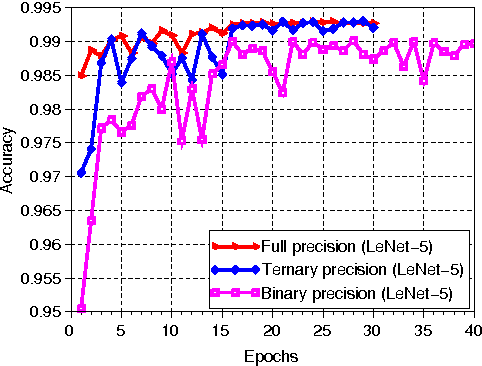
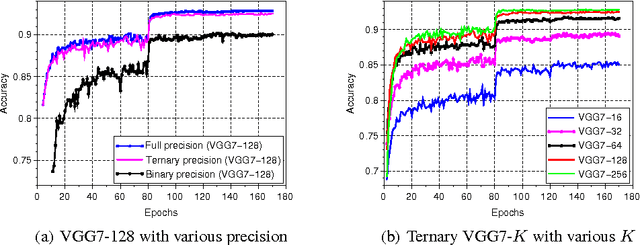
We introduce ternary weight networks (TWNs) - neural networks with weights constrained to +1, 0 and -1. The Euclidian distance between full (float or double) precision weights and the ternary weights along with a scaling factor is minimized. Besides, a threshold-based ternary function is optimized to get an approximated solution which can be fast and easily computed. TWNs have stronger expressive abilities than the recently proposed binary precision counterparts and are thus more effective than the latter. Meanwhile, TWNs achieve up to 16$\times$ or 32$\times$ model compression rate and need fewer multiplications compared with the full precision counterparts. Benchmarks on MNIST, CIFAR-10, and large scale ImageNet datasets show that the performance of TWNs is only slightly worse than the full precision counterparts but outperforms the analogous binary precision counterparts a lot.
A New Manifold Distance Measure for Visual Object Categorization
May 12, 2016



Manifold distances are very effective tools for visual object recognition. However, most of the traditional manifold distances between images are based on the pixel-level comparison and thus easily affected by image rotations and translations. In this paper, we propose a new manifold distance to model the dissimilarities between visual objects based on the Complex Wavelet Structural Similarity (CW-SSIM) index. The proposed distance is more robust to rotations and translations of images than the traditional manifold distance and the CW-SSIM index based distance. In addition, the proposed distance is combined with the $k$-medoids clustering method to derive a new clustering method for visual object categorization. Experiments on Coil-20, Coil-100 and Olivetti Face Databases show that the proposed distance measure is better for visual object categorization than both the traditional manifold distances and the CW-SSIM index based distances.