 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Deterministic Initialization for $k$-Means-Like Methods via Local Density Peaks Searching
Paper and Code
Nov 21, 2016
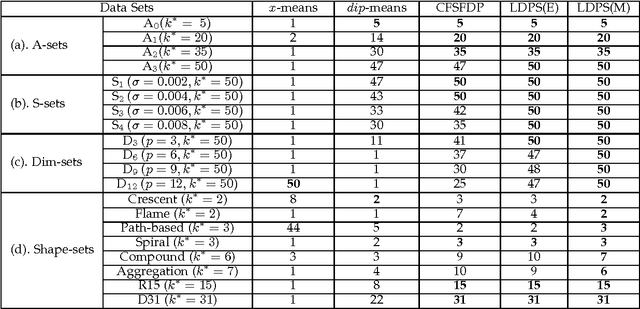
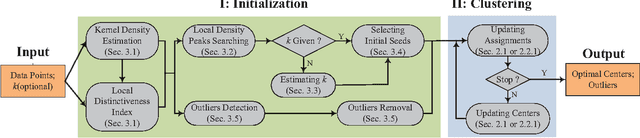

The $k$-means clustering algorithm is popular but has the following main drawbacks: 1) the number of clusters, $k$, needs to be provided by the user in advance, 2) it can easily reach local minima with randomly selected initial centers, 3) it is sensitive to outliers, and 4) it can only deal with well separated hyperspherical clusters. In this paper, we propose a Local Density Peaks Searching (LDPS) initialization framework to address these issues. The LDPS framework includes two basic components: one of them is the local density that characterizes the density distribution of a data set, and the other is the local distinctiveness index (LDI) which we introduce to characterize how distinctive a data point is compared with its neighbors. Based on these two components, we search for the local density peaks which are characterized with high local densities and high LDIs to deal with 1) and 2). Moreover, we detect outliers characterized with low local densities but high LDIs, and exclude them out before clustering begins. Finally, we apply the LDPS initialization framework to $k$-medoids, which is a variant of $k$-means and chooses data samples as centers, with diverse similarity measures other than the Euclidean distance to fix the last drawback of $k$-means. Combining the LDPS initialization framework with $k$-means and $k$-medoids, we obtain two novel clustering methods called LDPS-means and LDPS-medoids, respectively. Experiments on synthetic data sets verify the effectiveness of the proposed methods, especially when the ground truth of the cluster number $k$ is large. Further, experiments on several real world data sets, Handwritten Pendigits, Coil-20, Coil-100 and Olivetti Face Database, illustrate that our methods give a superior performance than the analogous approaches on both estimating $k$ and unsupervised object categorization.