 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding a Robot's Guiding Ethical Principles via Automatically Generated Explanations
Jun 20, 2022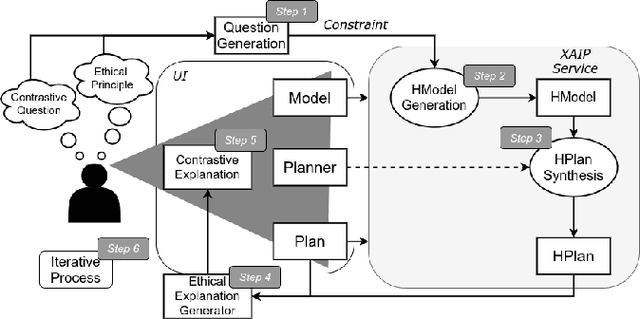
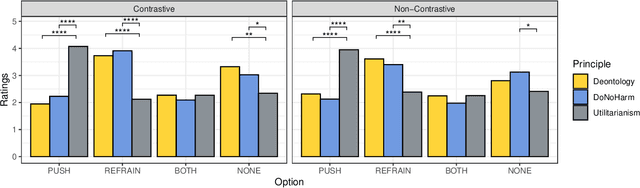
The continued development of robots has enabled their wider usage in human surroundings. Robots are more trusted to make increasingly important decisions with potentially critical outcomes. Therefore, it is essential to consider the ethical principles under which robots operate. In this paper we examine how contrastive and non-contrastive explanations can be used in understanding the ethics of robot action plans. We build upon an existing ethical framework to allow users to make suggestions about plans and receive automatically generated contrastive explanations. Results of a user study indicate that the generated explanations help humans to understand the ethical principles that underlie a robot's plan.
Accelerating the Convergence of Human-in-the-Loop Reinforcement Learning with Counterfactual Explanations
Aug 03, 2021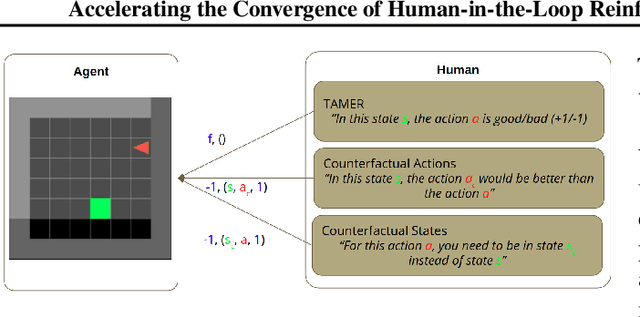
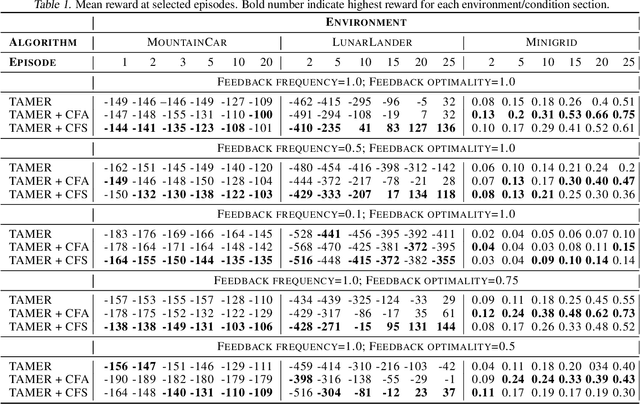
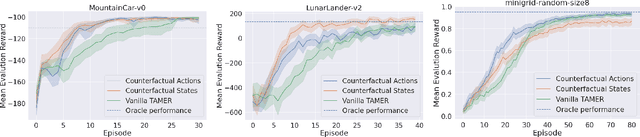
The capability to interactively learn from human feedback would enable robots in new social settings. For example, novice users could train service robots in new tasks naturally and interactively. Human-in-the-loop Reinforcement Learning (HRL) addresses this issue by combining human feedback and reinforcement learning (RL) techniques. State-of-the-art interactive learning techniques suffer from slow convergence, thus leading to a frustrating experience for the human. This work approaches this problem by extending the existing TAMER Framework with the possibility to enhance human feedback with two different types of counterfactual explanations. We demonstrate our extensions' success in improving the convergence, especially in the crucial early phases of the training.
Towards Contrastive Explanations for Comparing the Ethics of Plans
Jun 22, 2020
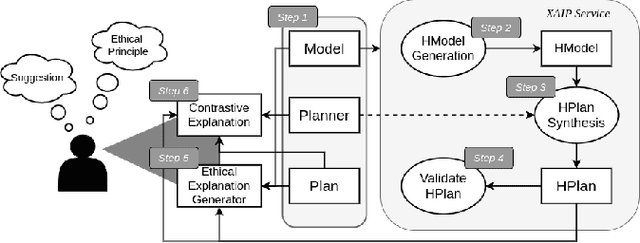
The development of robotics and AI agents has enabled their wider usage in human surroundings. AI agents are more trusted to make increasingly important decisions with potentially critical outcomes. It is essential to consider the ethical consequences of the decisions made by these systems. In this paper, we present how contrastive explanations can be used for comparing the ethics of plans. We build upon an existing ethical framework to allow users to make suggestions to plans and receive contrastive explanations.
A Formalization of Kant's Second Formulation of the Categorical Imperative
Mar 21, 2018



We present a formalization and computational implementation of the second formulation of Kant's categorical imperative. This ethical principle requires an agent to never treat someone merely as a means but always also as an end. Here we interpret this principle in terms of how persons are causally affected by actions. We introduce Kantian causal agency models in which moral patients, actions, goals, and causal influence are represented, and we show how to formalize several readings of Kant's categorical imperative that correspond to Kant's concept of strict and wide duties towards oneself and others. Stricter versions handle cases where an action directly causally affects oneself or others, whereas the wide version maximizes the number of persons being treated as an end. We discuss limitations of our formalization by pointing to one of Kant's cases that the machinery cannot handle in a satisfying way.