 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptACT: Episode-Level Concepts for Sample-Efficient Robotic Imitation Learning
Jan 23, 2026Imitation learning enables robots to acquire complex manipulation skills from human demonstrations, but current methods rely solely on low-level sensorimotor data while ignoring the rich semantic knowledge humans naturally possess about tasks. We present ConceptACT, an extension of Action Chunking with Transformers that leverages episode-level semantic concept annotations during training to improve learning efficiency. Unlike language-conditioned approaches that require semantic input at deployment, ConceptACT uses human-provided concepts (object properties, spatial relationships, task constraints) exclusively during demonstration collection, adding minimal annotation burden. We integrate concepts using a modified transformer architecture in which the final encoder layer implements concept-aware cross-attention, supervised to align with human annotations. Through experiments on two robotic manipulation tasks with logical constraints, we demonstrate that ConceptACT converges faster and achieves superior sample efficiency compared to standard ACT. Crucially, we show that architectural integration through attention mechanisms significantly outperforms naive auxiliary prediction losses or language-conditioned models. These results demonstrate that properly integrated semantic supervision provides powerful inductive biases for more efficient robot learning.
Tell my why: Training preferences-based RL with human preferences and step-level explanations
May 23, 2024



Human-in-the-loop reinforcement learning (HRL) allows the training of agents through various interfaces, even for non-expert humans. Recently, preference-based methods (PBRL), where the human has to give his preference over two trajectories, increased in popularity since they allow training in domains where more direct feedback is hard to formulate. However, the current PBRL methods have limitations and do not provide humans with an expressive interface for giving feedback. With this work, we propose a new preference-based learning method that provides humans with a more expressive interface to provide their preference over trajectories and a factual explanation (or annotation of why they have this preference). These explanations allow the human to explain what parts of the trajectory are most relevant for the preference. We allow the expression of the explanations over individual trajectory steps. We evaluate our method in various simulations using a simulated human oracle (with realistic restrictions), and our results show that our extended feedback can improve the speed of learning. Code & data: github.com/under-rewiev
Accelerating the Convergence of Human-in-the-Loop Reinforcement Learning with Counterfactual Explanations
Aug 03, 2021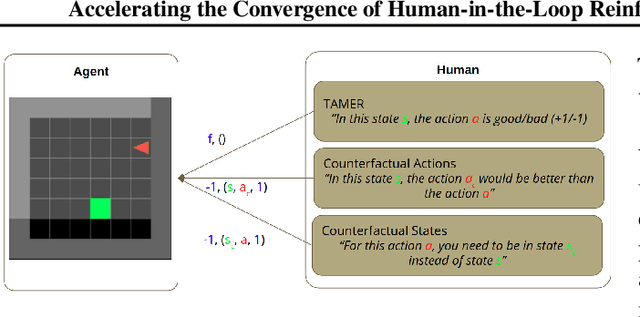
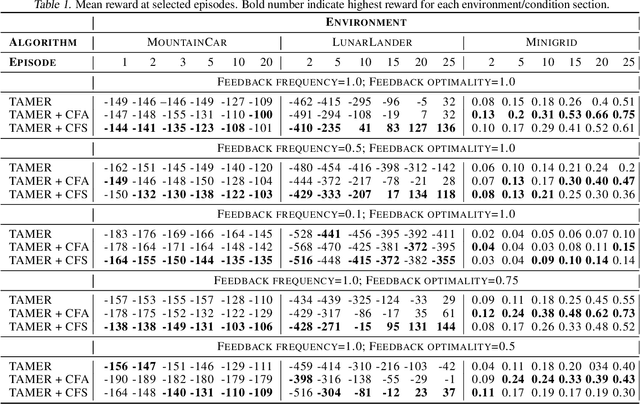
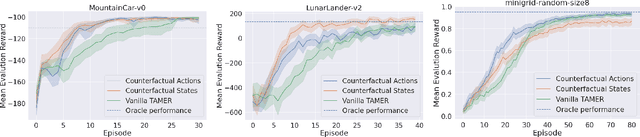
The capability to interactively learn from human feedback would enable robots in new social settings. For example, novice users could train service robots in new tasks naturally and interactively. Human-in-the-loop Reinforcement Learning (HRL) addresses this issue by combining human feedback and reinforcement learning (RL) techniques. State-of-the-art interactive learning techniques suffer from slow convergence, thus leading to a frustrating experience for the human. This work approaches this problem by extending the existing TAMER Framework with the possibility to enhance human feedback with two different types of counterfactual explanations. We demonstrate our extensions' success in improving the convergence, especially in the crucial early phases of the training.