 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRebounding Bandits for Modeling Satiation Effects
Nov 13, 2020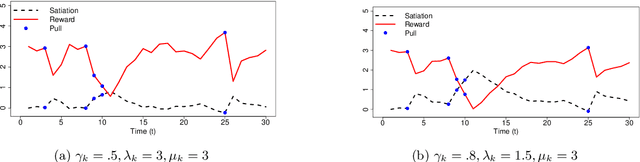

Psychological research shows that enjoyment of many goods is subject to satiation, with enjoyment declining after repeated exposures to the same item. Nevertheless, proposed algorithms for powering recommender systems seldom model these dynamics, instead proceeding as though user preferences were fixed in time. In this work, we adopt a multi-armed bandit setup, modeling satiation dynamics as a time-invariant linear dynamical system. In our model, the expected rewards for each arm decline monotonically with consecutive exposures and rebound towards the initial reward whenever that arm is not pulled. We analyze this model, showing that, when the arms exhibit deterministic identical dynamics, our problem is equivalent to a specific instance of Max K-Cut. In this case, a greedy policy, which plays the arms in a cyclic order, is optimal. In the general setting, where each arm's satiation dynamics are stochastic and governed by different (unknown) parameters, we propose an algorithm that first uses offline data to estimate each arm's reward model and then plans using a generalization of the greedy policy.
Theoretical and Practical Advances on Smoothing for Extensive-Form Games
May 09, 2017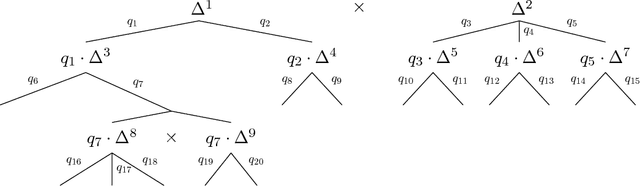
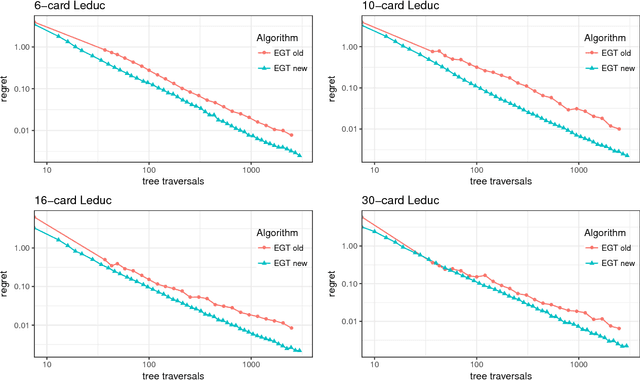
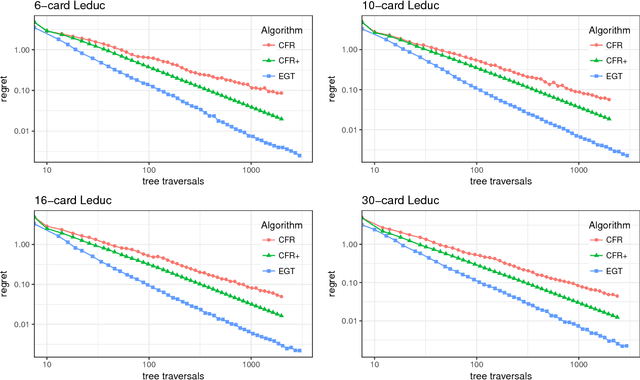
Sparse iterative methods, in particular first-order methods, are known to be among the most effective in solving large-scale two-player zero-sum extensive-form games. The convergence rates of these methods depend heavily on the properties of the distance-generating function that they are based on. We investigate the acceleration of first-order methods for solving extensive-form games through better design of the dilated entropy function---a class of distance-generating functions related to the domains associated with the extensive-form games. By introducing a new weighting scheme for the dilated entropy function, we develop the first distance-generating function for the strategy spaces of sequential games that has no dependence on the branching factor of the player. This result improves the convergence rate of several first-order methods by a factor of $\Omega(b^dd)$, where $b$ is the branching factor of the player, and $d$ is the depth of the game tree. Thus far, counterfactual regret minimization methods have been faster in practice, and more popular, than first-order methods despite their theoretically inferior convergence rates. Using our new weighting scheme and practical tuning we show that, for the first time, the excessive gap technique can be made faster than the fastest counterfactual regret minimization algorithm, CFR+, in practice.