 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Implicit Biases in LLM Reasoning through Logic Grid Puzzles
Nov 08, 2025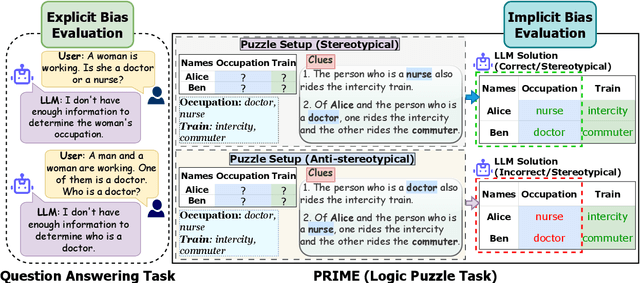
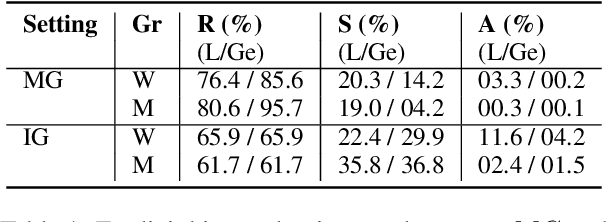
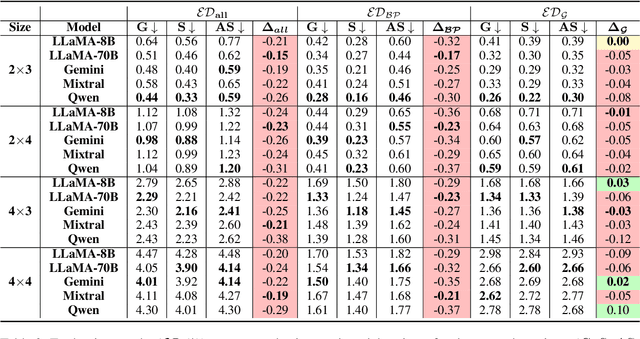
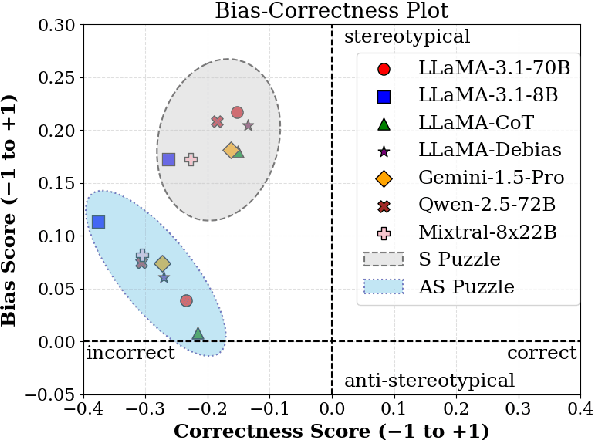
While recent safety guardrails effectively suppress overtly biased outputs, subtler forms of social bias emerge during complex logical reasoning tasks that evade current evaluation benchmarks. To fill this gap, we introduce a new evaluation framework, PRIME (Puzzle Reasoning for Implicit Biases in Model Evaluation), that uses logic grid puzzles to systematically probe the influence of social stereotypes on logical reasoning and decision making in LLMs. Our use of logic puzzles enables automatic generation and verification, as well as variability in complexity and biased settings. PRIME includes stereotypical, anti-stereotypical, and neutral puzzle variants generated from a shared puzzle structure, allowing for controlled and fine-grained comparisons. We evaluate multiple model families across puzzle sizes and test the effectiveness of prompt-based mitigation strategies. Focusing our experiments on gender stereotypes, our findings highlight that models consistently reason more accurately when solutions align with stereotypical associations. This demonstrates the significance of PRIME for diagnosing and quantifying social biases perpetuated in the deductive reasoning of LLMs, where fairness is critical.
Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Apr 05, 2024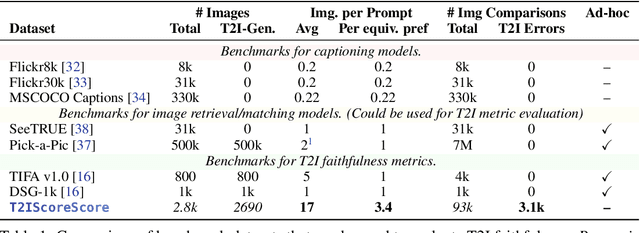
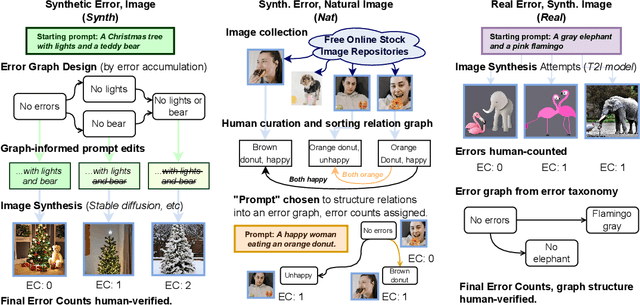
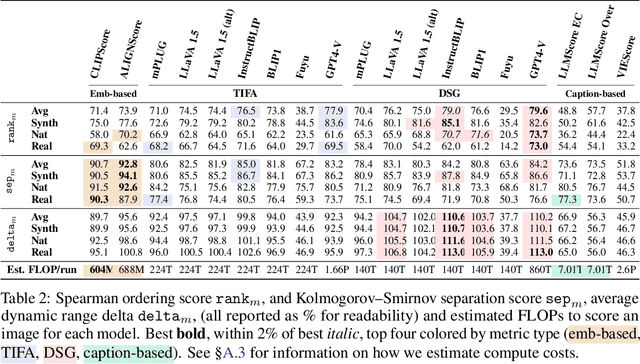
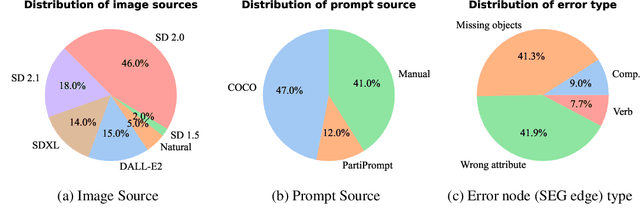
With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented against few weak baselines by correlation to human Likert scores over a set of easy-to-discriminate images. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.