 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Paper and Code
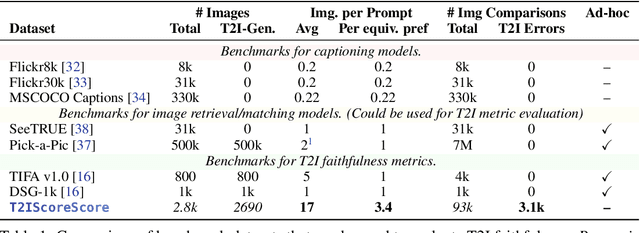
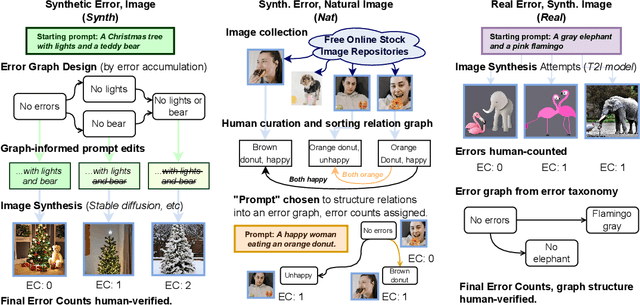
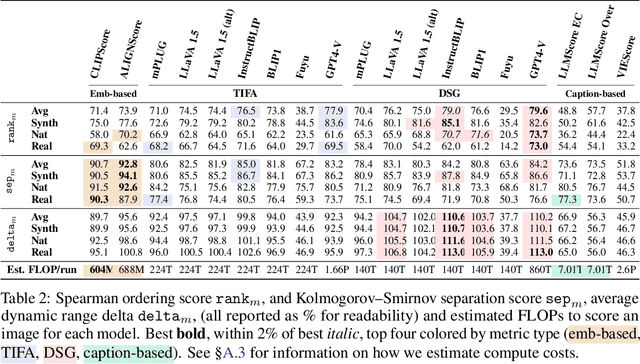
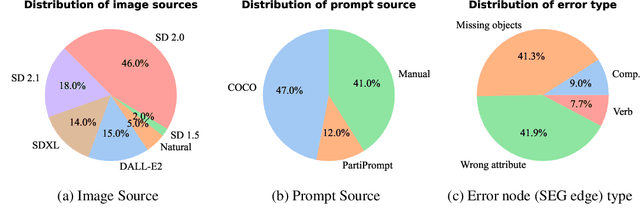
With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented against few weak baselines by correlation to human Likert scores over a set of easy-to-discriminate images. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.