 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Frequency Constraints in Preventive Unit Commitment Using Deep Learning with Region-of-Interest Active Sampling
Feb 18, 2021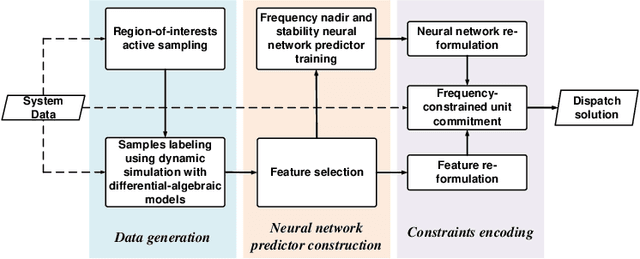
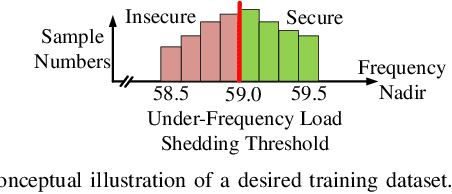
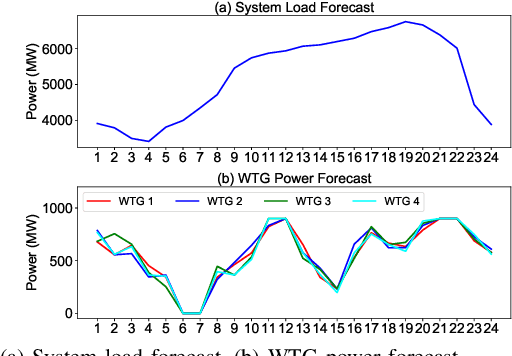
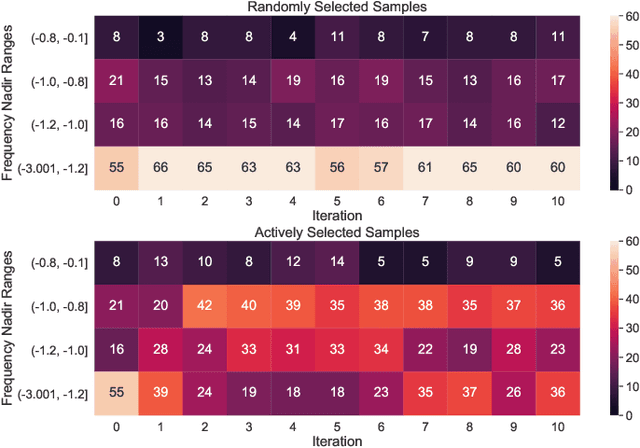
With the increasing penetration of renewable energy, frequency response and its security are of significant concerns for reliable power system operations. Frequency-constrained unit commitment (FCUC) is proposed to address this challenge. Despite existing efforts in modeling frequency characteristics in unit commitment (UC), current strategies can only handle oversimplified low-order frequency response models and do not consider wide-range operating conditions. This paper presents a generic data-driven framework for FCUC under high renewable penetration. Deep neural networks (DNNs) are trained to predict the frequency response using real data or high-fidelity simulation data. Next, the DNN is reformulated as a set of mixed-integer linear constraints to be incorporated into the ordinary UC formulation. In the data generation phase, all possible power injections are considered, and a region-of-interests active sampling is proposed to include power injection samples with frequency nadirs closer to the UFLC threshold, which significantly enhances the accuracy of frequency constraints in FCUC. The proposed FCUC is verified on the the IEEE 39-bus system. Then, a full-order dynamic model simulation using PSS/E verifies the effectiveness of FCUC in frequency-secure generator commitments.
Hybrid Imitation Learning for Real-Time Service Restoration in Resilient Distribution Systems
Dec 04, 2020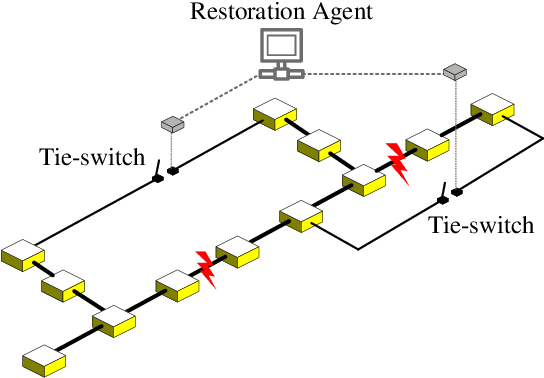
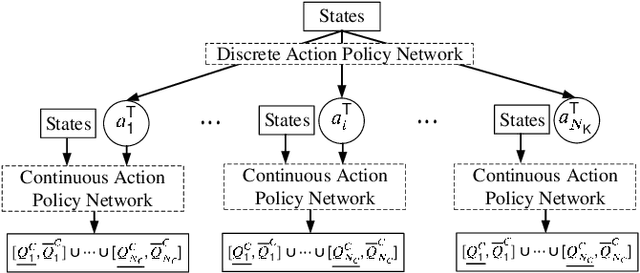
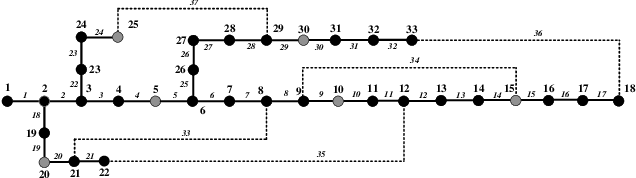

Self-healing capability is one of the most critical factors for a resilient distribution system, which requires intelligent agents to automatically perform restorative actions online, including network reconfiguration and reactive power dispatch. These agents should be equipped with a predesigned decision policy to meet real-time requirements and handle highly complex $N-k$ scenarios. The disturbance randomness hampers the application of exploration-dominant algorithms like traditional reinforcement learning (RL), and the agent training problem under $N-k$ scenarios has not been thoroughly solved. In this paper, we propose the imitation learning (IL) framework to train such policies, where the agent will interact with an expert to learn its optimal policy, and therefore significantly improve the training efficiency compared with the RL methods. To handle tie-line operations and reactive power dispatch simultaneously, we design a hybrid policy network for such a discrete-continuous hybrid action space. We employ the 33-node system under $N-k$ disturbances to verify the proposed framework.