 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping the Cross-Validation Estimate
Jul 01, 2023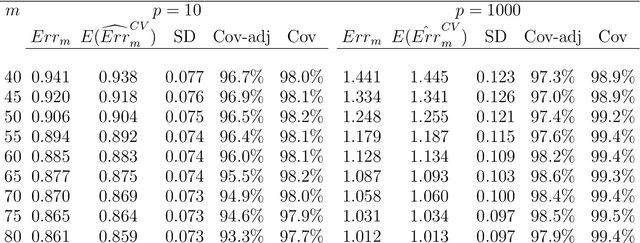
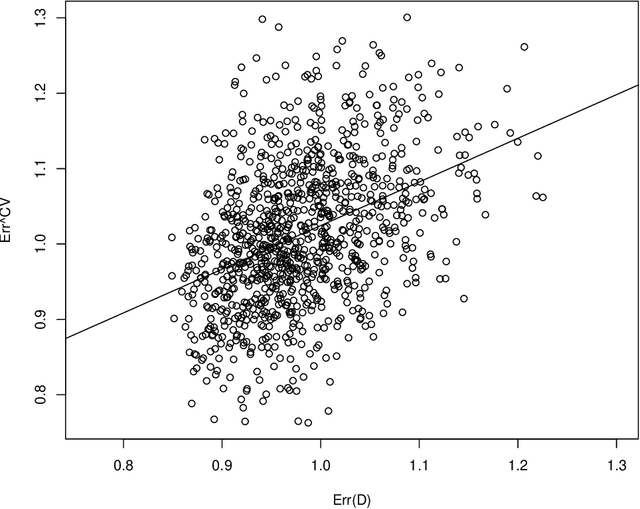
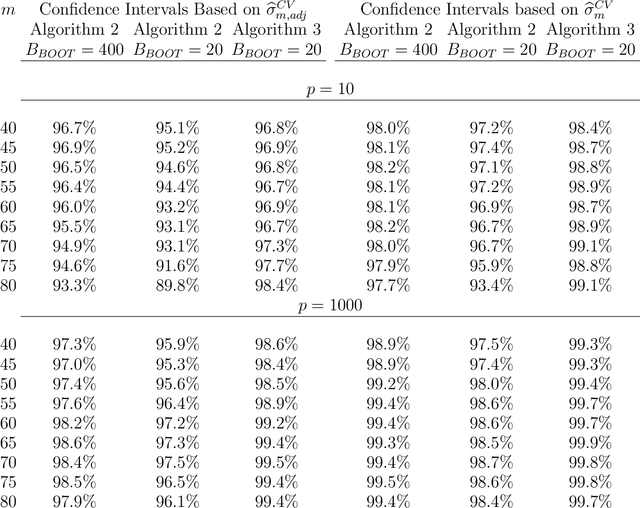
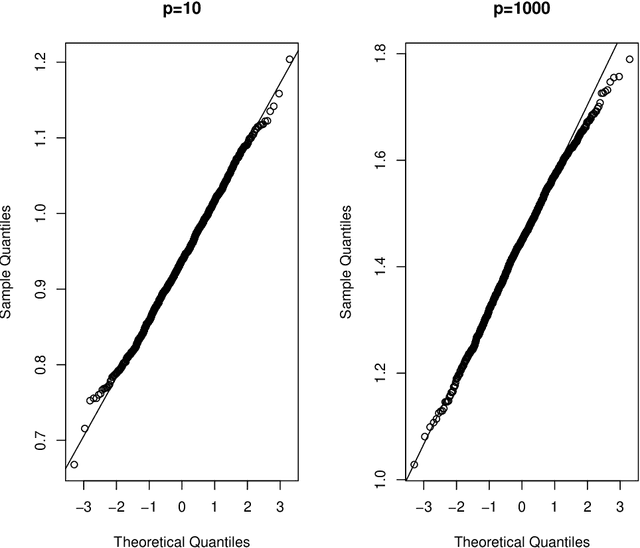
Cross-validation is a widely used technique for evaluating the performance of prediction models. It helps avoid the optimism bias in error estimates, which can be significant for models built using complex statistical learning algorithms. However, since the cross-validation estimate is a random value dependent on observed data, it is essential to accurately quantify the uncertainty associated with the estimate. This is especially important when comparing the performance of two models using cross-validation, as one must determine whether differences in error estimates are a result of chance fluctuations. Although various methods have been developed for making inferences on cross-validation estimates, they often have many limitations, such as stringent model assumptions This paper proposes a fast bootstrap method that quickly estimates the standard error of the cross-validation estimate and produces valid confidence intervals for a population parameter measuring average model performance. Our method overcomes the computational challenge inherent in bootstrapping the cross-validation estimate by estimating the variance component within a random effects model. It is just as flexible as the cross-validation procedure itself. To showcase the effectiveness of our approach, we employ comprehensive simulations and real data analysis across three diverse applications.
Estimation and Validation of a Class of Conditional Average Treatment Effects Using Observational Data
Dec 15, 2019
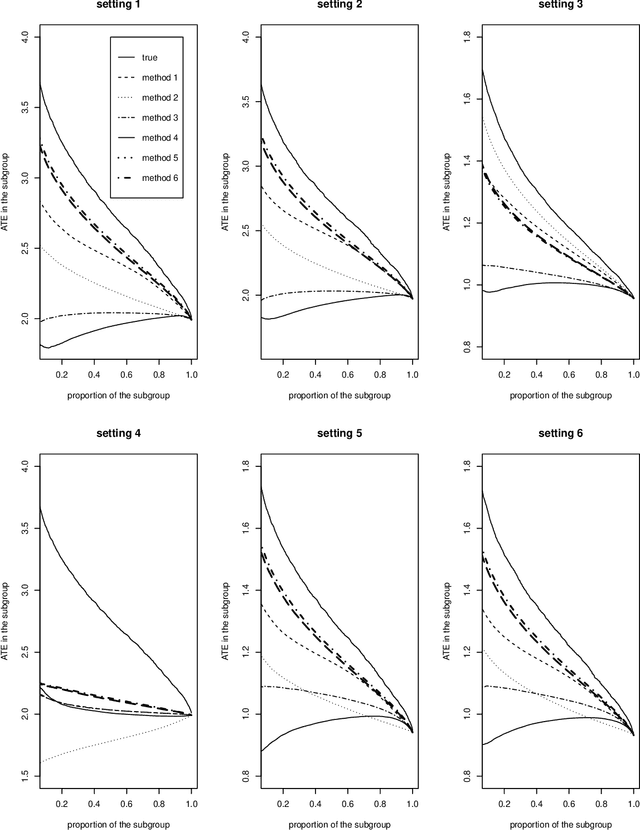

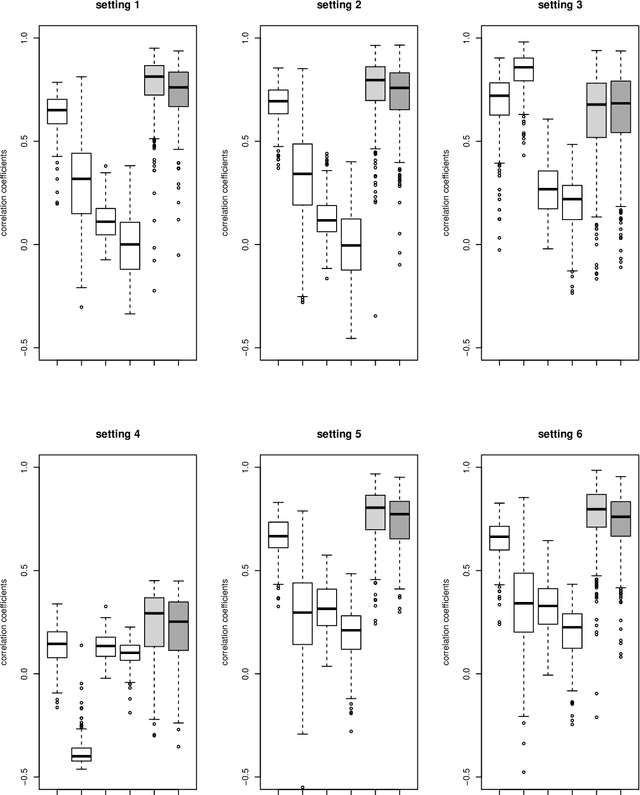
While sample sizes in randomized clinical trials are large enough to estimate the average treatment effect well, they are often insufficient for estimation of treatment-covariate interactions critical to studying data-driven precision medicine. Observational data from real world practice may play an important role in alleviating this problem. One common approach in trials is to predict the outcome of interest with separate regression models in each treatment arm, and recommend interventions based on the contrast of the predicted outcomes. Unfortunately, this simple approach may induce spurious treatment-covariate interaction in observational studies when the regression model is misspecified. Motivated by the need of modeling the number of relapses in multiple sclerosis patients, where the ratio of relapse rates is a natural choice of the treatment effect, we propose to estimate the conditional average treatment effect (CATE) as the relative ratio of the potential outcomes, and derive a doubly robust estimator of this CATE in a semiparametric model of treatment-covariate interactions. We also provide a validation procedure to check the quality of the estimator on an independent sample. We conduct simulations to demonstrate the finite sample performance of the proposed methods, and illustrate the advantage of this approach on real data examining the treatment effect of dimethyl fumarate compared to teriflunomide in multiple sclerosis patients.