 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExMo: Explainable AI Model using Inverse Frequency Decision Rules
May 20, 2022In this paper, we present a novel method to compute decision rules to build a more accurate interpretable machine learning model, denoted as ExMo. The ExMo interpretable machine learning model consists of a list of IF...THEN... statements with a decision rule in the condition. This way, ExMo naturally provides an explanation for a prediction using the decision rule that was triggered. ExMo uses a new approach to extract decision rules from the training data using term frequency-inverse document frequency (TF-IDF) features. With TF-IDF, decision rules with feature values that are more relevant to each class are extracted. Hence, the decision rules obtained by ExMo can distinguish the positive and negative classes better than the decision rules used in the existing Bayesian Rule List (BRL) algorithm, obtained using the frequent pattern mining approach. The paper also shows that ExMo learns a qualitatively better model than BRL. Furthermore, ExMo demonstrates that the textual explanation can be provided in a human-friendly way so that the explanation can be easily understood by non-expert users. We validate ExMo on several datasets with different sizes to evaluate its efficacy. Experimental validation on a real-world fraud detection application shows that ExMo is 20% more accurate than BRL and that it achieves accuracy similar to those of deep learning models.
Explainable Machine Learning for Fraud Detection
May 13, 2021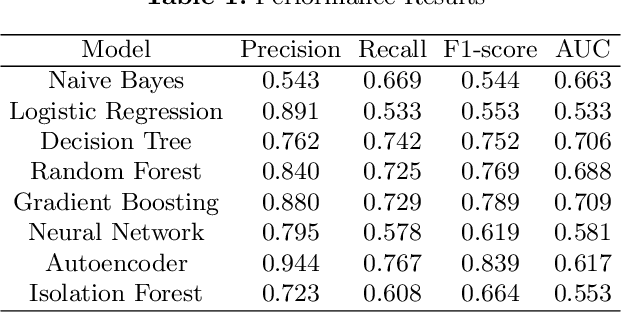
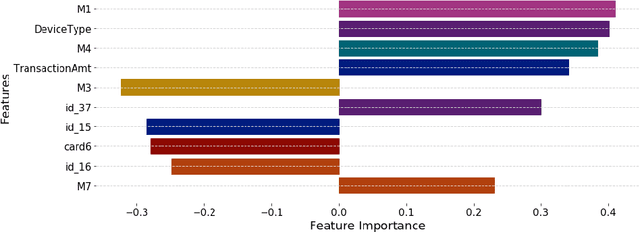
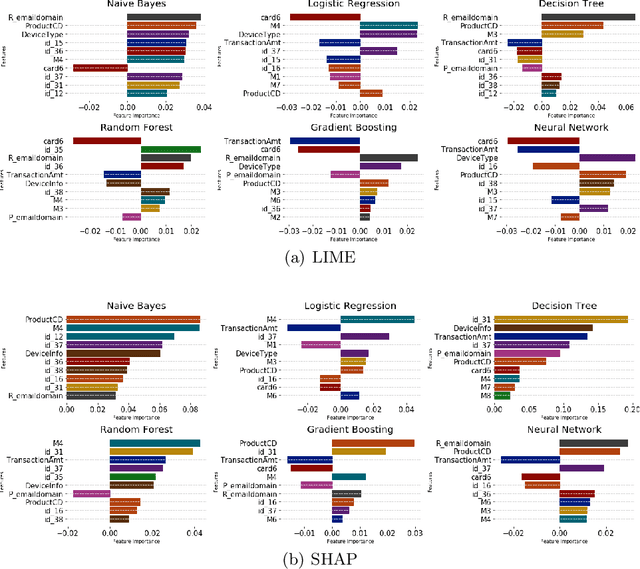
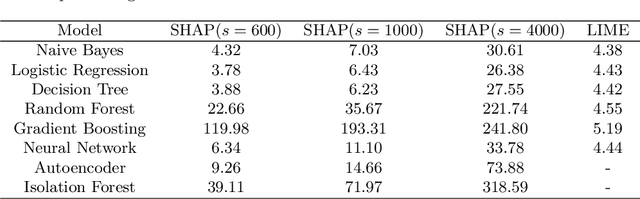
The application of machine learning to support the processing of large datasets holds promise in many industries, including financial services. However, practical issues for the full adoption of machine learning remain with the focus being on understanding and being able to explain the decisions and predictions made by complex models. In this paper, we explore explainability methods in the domain of real-time fraud detection by investigating the selection of appropriate background datasets and runtime trade-offs on both supervised and unsupervised models.
PINFER: Privacy-Preserving Inference for Machine Learning
Oct 04, 2019
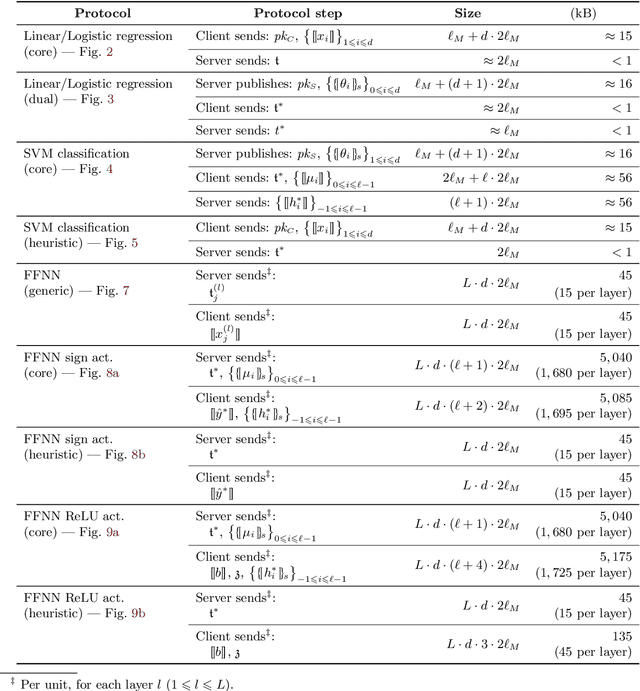


The foreseen growing role of outsourced machine learning services is raising concerns about the privacy of user data. Several technical solutions are being proposed to address the issue. Hardware security modules in cloud data centres appear limited to enterprise customers due to their complexity, while general multi-party computation techniques require a large number of message exchanges. This paper proposes a variety of protocols for privacy-preserving regression and classification that (i) only require additively homomorphic encryption algorithms, (ii) limit interactions to a mere request and response, and (iii) that can be used directly for important machine-learning algorithms such as logistic regression and SVM classification. The basic protocols are then extended and applied to feed-forward neural networks.