Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Machine Learning for Fraud Detection
Paper and Code
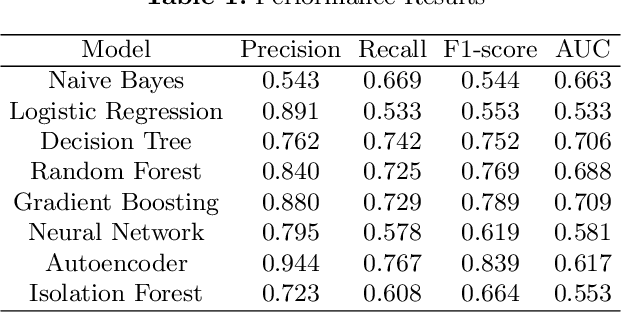
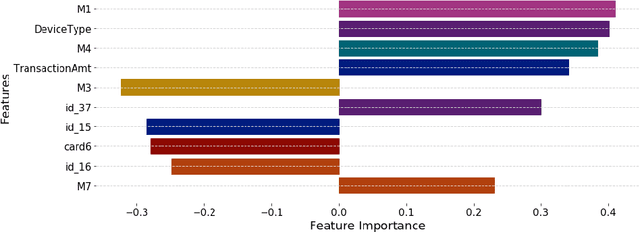
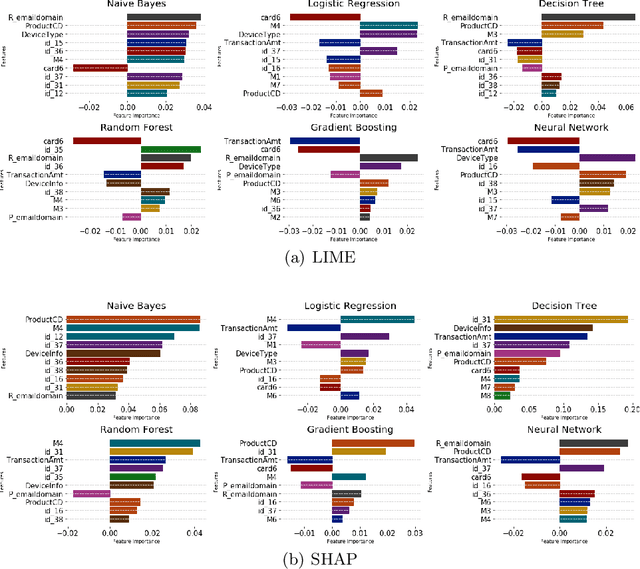
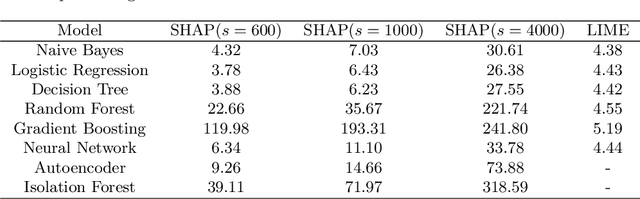
The application of machine learning to support the processing of large datasets holds promise in many industries, including financial services. However, practical issues for the full adoption of machine learning remain with the focus being on understanding and being able to explain the decisions and predictions made by complex models. In this paper, we explore explainability methods in the domain of real-time fraud detection by investigating the selection of appropriate background datasets and runtime trade-offs on both supervised and unsupervised models.
* To be published in IEEE Computer Special Issue on Explainable AI and
Machine Learning, 12 pages, 7 figures
View paper on