 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn interpretable approach to automating the assessment of biofouling in video footage
Mar 17, 2025



Biofouling$\unicode{x2013}$communities of organisms that grow on hard surfaces immersed in water$\unicode{x2013}$provides a pathway for the spread of invasive marine species and diseases. To address this risk, international vessels are increasingly being obligated to provide evidence of their biofouling management practices. Verification that these activities are effective requires underwater inspections, using divers or underwater remotely operated vehicles (ROVs), and the collection and analysis of large amounts of imagery and footage. Automated assessment using computer vision techniques can significantly streamline this process, and this work shows how this challenge can be addressed efficiently and effectively using the interpretable Component Features (ComFe) approach with a DINOv2 Vision Transformer (ViT) foundation model. ComFe is able to obtain improved performance in comparison to previous non-interpretable Convolutional Neural Network (CNN) methods, with significantly fewer weights and greater transparency$\unicode{x2013}$through identifying which regions of the image contribute to the classification, and which images in the training data lead to that conclusion. All code, data and model weights are publicly released.
Faithful Label-free Knowledge Distillation
Nov 22, 2024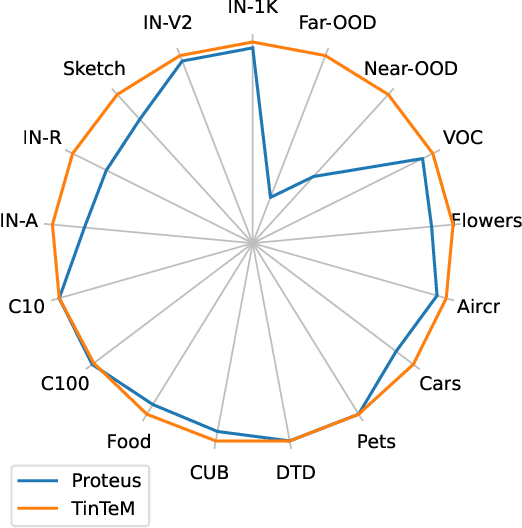
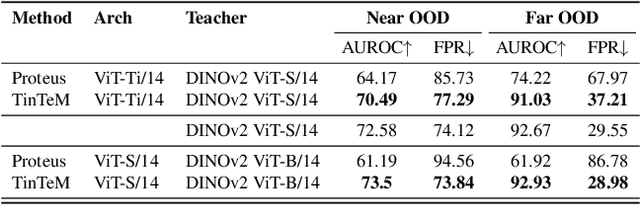

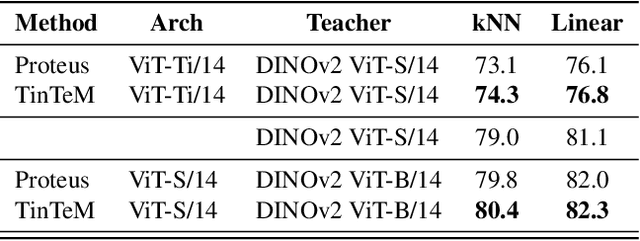
Knowledge distillation approaches are model compression techniques, with the goal of training a highly performant student model by using a teacher network that is larger or contains a different inductive bias. These approaches are particularly useful when applied to large computer vision foundation models, which can be compressed into smaller variants that retain desirable properties such as improved robustness. This paper presents a label-free knowledge distillation approach called Teacher in the Middle (TinTeM), which improves on previous methods by learning an approximately orthogonal mapping from the latent space of the teacher to the student network. This produces a more faithful student, which better replicates the behavior of the teacher network across a range of benchmarks testing model robustness, generalisability and out-of-distribution detection. It is further shown that knowledge distillation with TinTeM on task specific datasets leads to more accurate models with greater generalisability and OOD detection performance, and that this technique provides a competitive pathway for training highly performant lightweight models on small datasets.
Cold PAWS: Unsupervised class discovery and the cold-start problem
May 17, 2023In many machine learning applications, labeling datasets can be an arduous and time-consuming task. Although research has shown that semi-supervised learning techniques can achieve high accuracy with very few labels within the field of computer vision, little attention has been given to how images within a dataset should be selected for labeling. In this paper, we propose a novel approach based on well-established self-supervised learning, clustering, and manifold learning techniques that address this challenge of selecting an informative image subset to label in the first instance, which is known as the cold-start or unsupervised selective labelling problem. We test our approach using several publicly available datasets, namely CIFAR10, Imagenette, DeepWeeds, and EuroSAT, and observe improved performance with both supervised and semi-supervised learning strategies when our label selection strategy is used, in comparison to random sampling. We also obtain superior performance for the datasets considered with a much simpler approach compared to other methods in the literature.