 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold PAWS: Unsupervised class discovery and the cold-start problem
May 17, 2023In many machine learning applications, labeling datasets can be an arduous and time-consuming task. Although research has shown that semi-supervised learning techniques can achieve high accuracy with very few labels within the field of computer vision, little attention has been given to how images within a dataset should be selected for labeling. In this paper, we propose a novel approach based on well-established self-supervised learning, clustering, and manifold learning techniques that address this challenge of selecting an informative image subset to label in the first instance, which is known as the cold-start or unsupervised selective labelling problem. We test our approach using several publicly available datasets, namely CIFAR10, Imagenette, DeepWeeds, and EuroSAT, and observe improved performance with both supervised and semi-supervised learning strategies when our label selection strategy is used, in comparison to random sampling. We also obtain superior performance for the datasets considered with a much simpler approach compared to other methods in the literature.
Conditional Density Estimation via Weighted Logistic Regressions
Oct 21, 2020

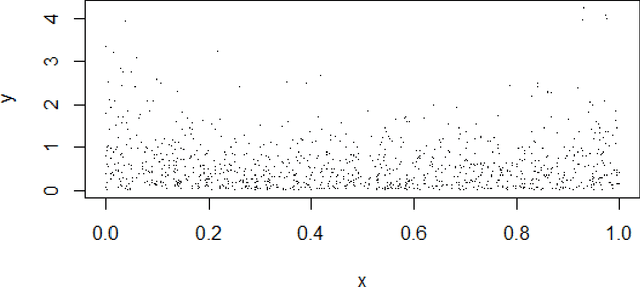

Compared to the conditional mean as a simple point estimator, the conditional density function is more informative to describe the distributions with multi-modality, asymmetry or heteroskedasticity. In this paper, we propose a novel parametric conditional density estimation method by showing the connection between the general density and the likelihood function of inhomogeneous Poisson process models. The maximum likelihood estimates can be obtained via weighted logistic regressions, and the computation can be significantly relaxed by combining a block-wise alternating maximization scheme and local case-control sampling. We also provide simulation studies for illustration.
On Robust Probabilistic Principal Component Analysis using Multivariate $t$-Distributions
Oct 21, 2020

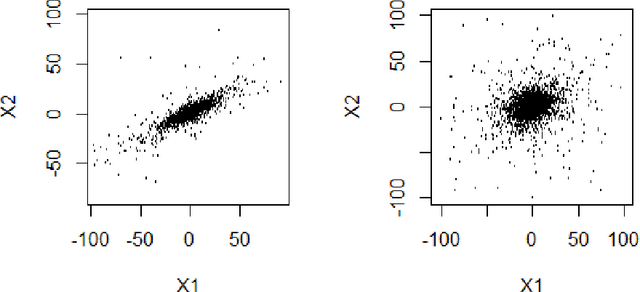

Principal Component Analysis (PCA) is a common multivariate statistical analysis method, and Probabilistic Principal Component Analysis (PPCA) is its probabilistic reformulation under the framework of Gaussian latent variable model. To improve the robustness of PPCA, it has been proposed to change the underlying Gaussian distributions to multivariate $t$-distributions. Based on the representation of $t$-distribution as a scale mixture of Gaussians, a hierarchical model is used for implementation. However, although the robust PPCA methods work reasonably well for some simulation studies and real data, the hierarchical model implemented does not yield the equivalent interpretation. In this paper, we present a set of equivalent relationships between those models, and discuss the performance of robust PPCA methods using different multivariate $t$-distributed structures through several simulation studies. In doing so, we clarify a current misrepresentation in the literature, and make connections between a set of hierarchical models for robust PPCA.
Nonparametric Conditional Density Estimation In A Deep Learning Framework For Short-Term Forecasting
Aug 17, 2020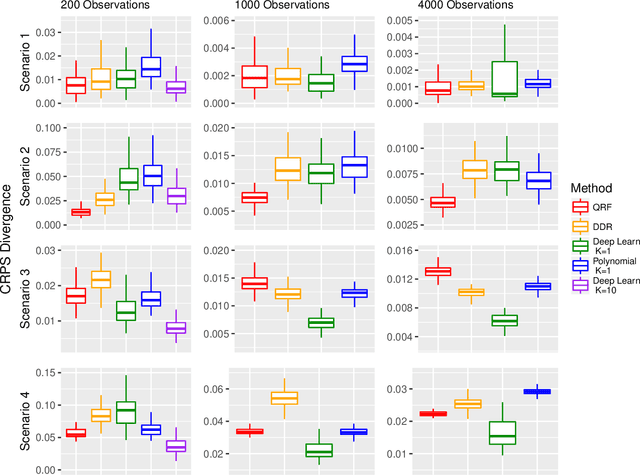

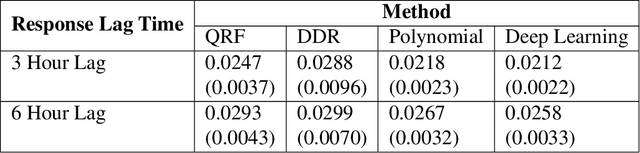
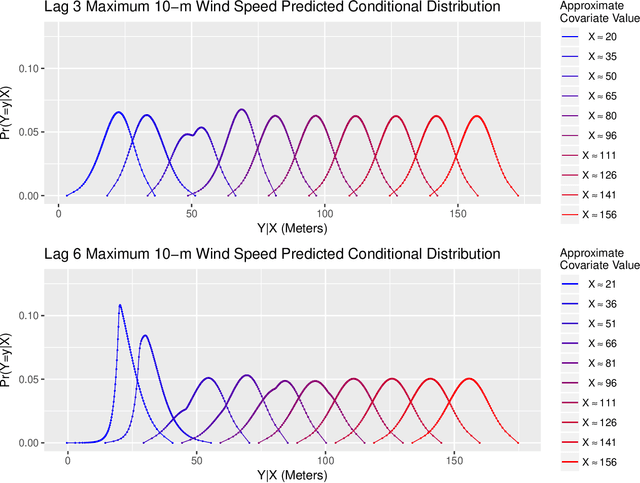
Short-term forecasting is an important tool in understanding environmental processes. In this paper, we incorporate machine learning algorithms into a conditional distribution estimator for the purposes of forecasting tropical cyclone intensity. Many machine learning techniques give a single-point prediction of the conditional distribution of the target variable, which does not give a full accounting of the prediction variability. Conditional distribution estimation can provide extra insight on predicted response behavior, which could influence decision-making and policy. We propose a technique that simultaneously estimates the entire conditional distribution and flexibly allows for machine learning techniques to be incorporated. A smooth model is fit over both the target variable and covariates, and a logistic transformation is applied on the model output layer to produce an expression of the conditional density function. We provide two examples of machine learning models that can be used, polynomial regression and deep learning models. To achieve computational efficiency we propose a case-control sampling approximation to the conditional distribution. A simulation study for four different data distributions highlights the effectiveness of our method compared to other machine learning-based conditional distribution estimation techniques. We then demonstrate the utility of our approach for forecasting purposes using tropical cyclone data from the Atlantic Seaboard. This paper gives a proof of concept for the promise of our method, further computational developments can fully unlock its insights in more complex forecasting and other applications.
Deep Distribution Regression
Mar 14, 2019
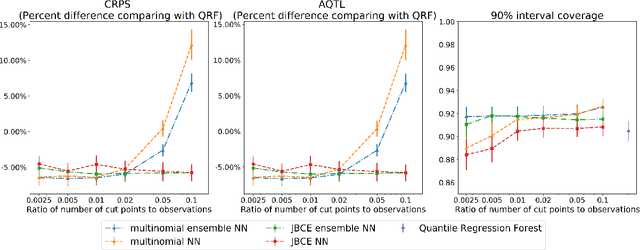


Due to their flexibility and predictive performance, machine-learning based regression methods have become an important tool for predictive modeling and forecasting. However, most methods focus on estimating the conditional mean or specific quantiles of the target quantity and do not provide the full conditional distribution, which contains uncertainty information that might be crucial for decision making. In this article, we provide a general solution by transforming a conditional distribution estimation problem into a constrained multi-class classification problem, in which tools such as deep neural networks. We propose a novel joint binary cross-entropy loss function to accomplish this goal. We demonstrate its performance in various simulation studies comparing to state-of-the-art competing methods. Additionally, our method shows improved accuracy in a probabilistic solar energy forecasting problem.