 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Label-free Knowledge Distillation
Paper and Code
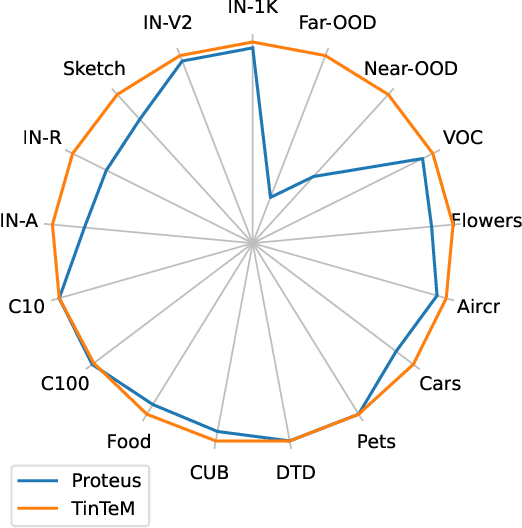
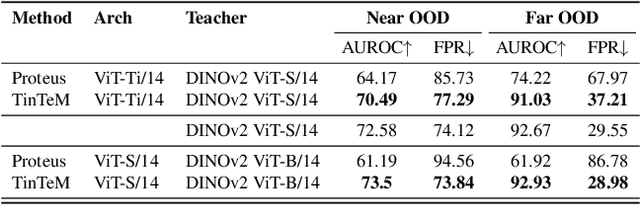

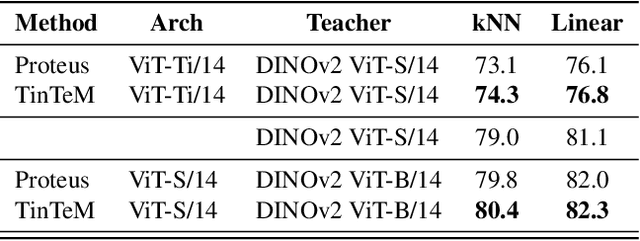
Knowledge distillation approaches are model compression techniques, with the goal of training a highly performant student model by using a teacher network that is larger or contains a different inductive bias. These approaches are particularly useful when applied to large computer vision foundation models, which can be compressed into smaller variants that retain desirable properties such as improved robustness. This paper presents a label-free knowledge distillation approach called Teacher in the Middle (TinTeM), which improves on previous methods by learning an approximately orthogonal mapping from the latent space of the teacher to the student network. This produces a more faithful student, which better replicates the behavior of the teacher network across a range of benchmarks testing model robustness, generalisability and out-of-distribution detection. It is further shown that knowledge distillation with TinTeM on task specific datasets leads to more accurate models with greater generalisability and OOD detection performance, and that this technique provides a competitive pathway for training highly performant lightweight models on small datasets.