 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Word Embeddings from the Portuguese Twitter Stream: A Study of some Practical Aspects
Sep 04, 2017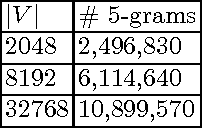
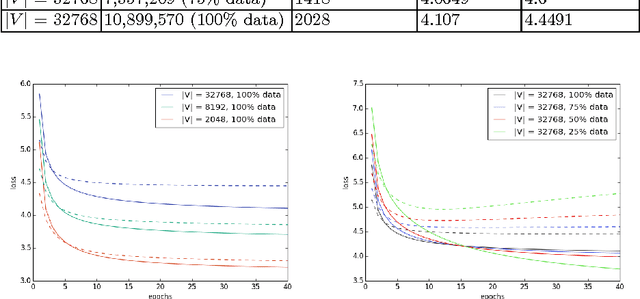
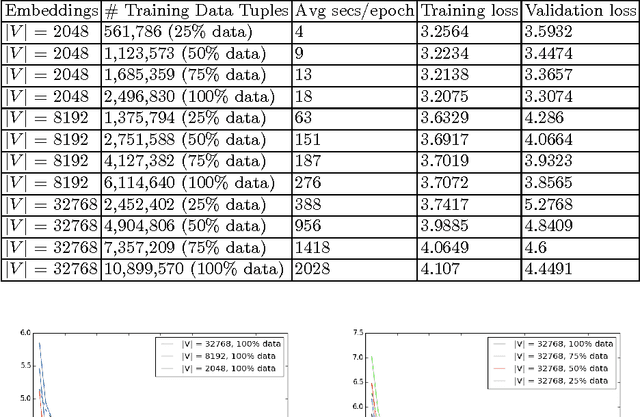
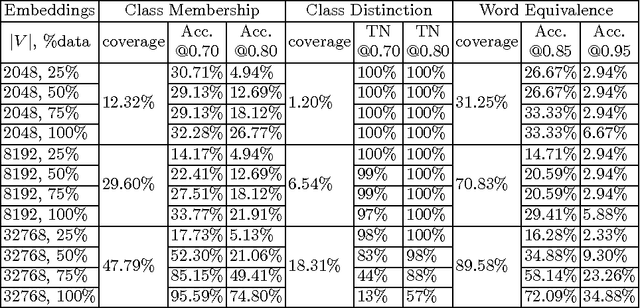
This paper describes a preliminary study for producing and distributing a large-scale database of embeddings from the Portuguese Twitter stream. We start by experimenting with a relatively small sample and focusing on three challenges: volume of training data, vocabulary size and intrinsic evaluation metrics. Using a single GPU, we were able to scale up vocabulary size from 2048 words embedded and 500K training examples to 32768 words over 10M training examples while keeping a stable validation loss and approximately linear trend on training time per epoch. We also observed that using less than 50\% of the available training examples for each vocabulary size might result in overfitting. Results on intrinsic evaluation show promising performance for a vocabulary size of 32768 words. Nevertheless, intrinsic evaluation metrics suffer from over-sensitivity to their corresponding cosine similarity thresholds, indicating that a wider range of metrics need to be developed to track progress.
FEUP at SemEval-2017 Task 5: Predicting Sentiment Polarity and Intensity with Financial Word Embeddings
Apr 17, 2017
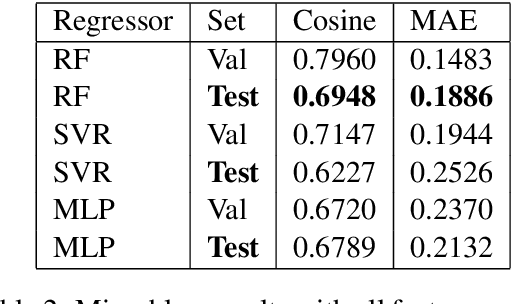
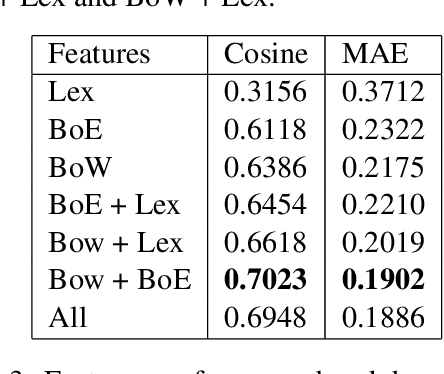
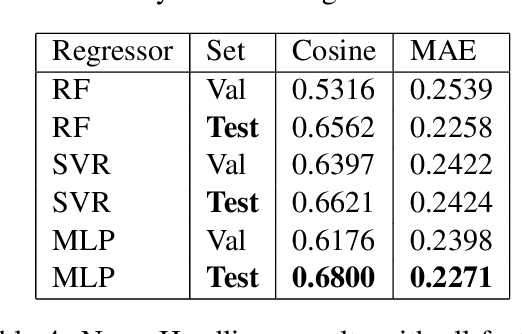
This paper presents the approach developed at the Faculty of Engineering of University of Porto, to participate in SemEval 2017, Task 5: Fine-grained Sentiment Analysis on Financial Microblogs and News. The task consisted in predicting a real continuous variable from -1.0 to +1.0 representing the polarity and intensity of sentiment concerning companies/stocks mentioned in short texts. We modeled the task as a regression analysis problem and combined traditional techniques such as pre-processing short texts, bag-of-words representations and lexical-based features with enhanced financial specific bag-of-embeddings. We used an external collection of tweets and news headlines mentioning companies/stocks from S\&P 500 to create financial word embeddings which are able to capture domain-specific syntactic and semantic similarities. The resulting approach obtained a cosine similarity score of 0.69 in sub-task 5.1 - Microblogs and 0.68 in sub-task 5.2 - News Headlines.