 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Dialogue Workflow Action Prediction
Nov 16, 2023



In task-oriented dialogue, a system often needs to follow a sequence of actions, called a workflow, that complies with a set of guidelines in order to complete a task. In this paper, we propose the novel problem of multi-step workflow action prediction, in which the system predicts multiple future workflow actions. Accurate prediction of multiple steps allows for multi-turn automation, which can free up time to focus on more complex tasks. We propose three modeling approaches that are simple to implement yet lead to more action automation: 1) fine-tuning on a training dataset, 2) few-shot in-context learning leveraging retrieval and large language model prompting, and 3) zero-shot graph traversal, which aggregates historical action sequences into a graph for prediction. We show that multi-step action prediction produces features that improve accuracy on downstream dialogue tasks like predicting task success, and can increase automation of steps by 20% without requiring as much feedback from a human overseeing the system.
Scalable Greedy Feature Selection via Weak Submodularity
Mar 08, 2017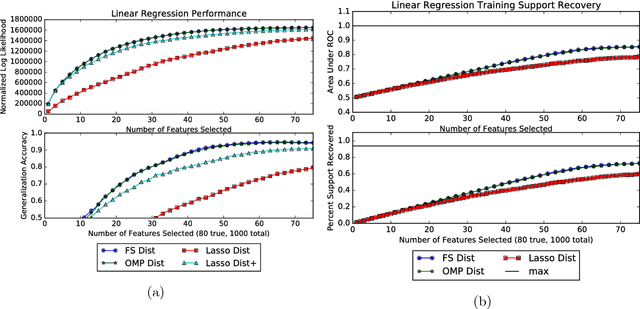

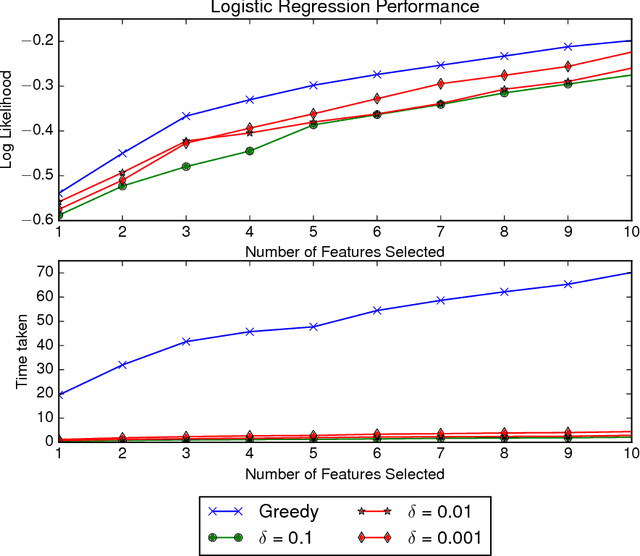
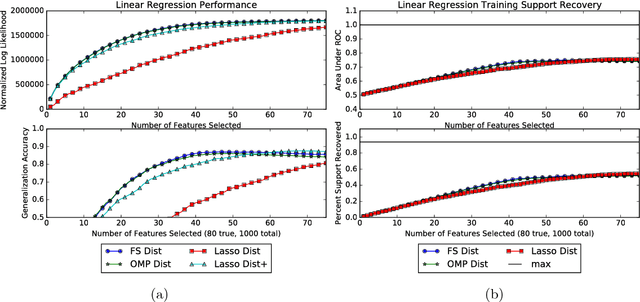
Greedy algorithms are widely used for problems in machine learning such as feature selection and set function optimization. Unfortunately, for large datasets, the running time of even greedy algorithms can be quite high. This is because for each greedy step we need to refit a model or calculate a function using the previously selected choices and the new candidate. Two algorithms that are faster approximations to the greedy forward selection were introduced recently ([Mirzasoleiman et al. 2013, 2015]). They achieve better performance by exploiting distributed computation and stochastic evaluation respectively. Both algorithms have provable performance guarantees for submodular functions. In this paper we show that divergent from previously held opinion, submodularity is not required to obtain approximation guarantees for these two algorithms. Specifically, we show that a generalized concept of weak submodularity suffices to give multiplicative approximation guarantees. Our result extends the applicability of these algorithms to a larger class of functions. Furthermore, we show that a bounded submodularity ratio can be used to provide data dependent bounds that can sometimes be tighter also for submodular functions. We empirically validate our work by showing superior performance of fast greedy approximations versus several established baselines on artificial and real datasets.
On Approximation Guarantees for Greedy Low Rank Optimization
Mar 08, 2017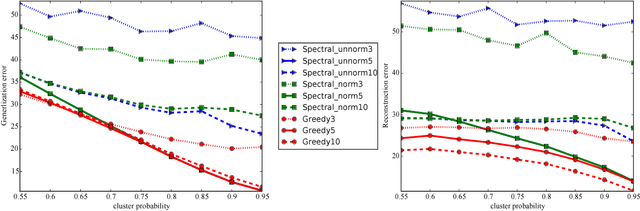
We provide new approximation guarantees for greedy low rank matrix estimation under standard assumptions of restricted strong convexity and smoothness. Our novel analysis also uncovers previously unknown connections between the low rank estimation and combinatorial optimization, so much so that our bounds are reminiscent of corresponding approximation bounds in submodular maximization. Additionally, we also provide statistical recovery guarantees. Finally, we present empirical comparison of greedy estimation with established baselines on two important real-world problems.