 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyapunov Function-guided Reinforcement Learning for Flight Control
Oct 26, 2025A cascaded online learning flight control system has been developed and enhanced with respect to action smoothness. In this paper, we investigate the convergence performance of the control system, characterized by the increment of a Lyapunov function candidate. The derivation of this metric accounts for discretization errors and state prediction errors introduced by the incremental model. Comparative results are presented through flight control simulations.
Adaptive Risk Tendency: Nano Drone Navigation in Cluttered Environments with Distributional Reinforcement Learning
Mar 28, 2022

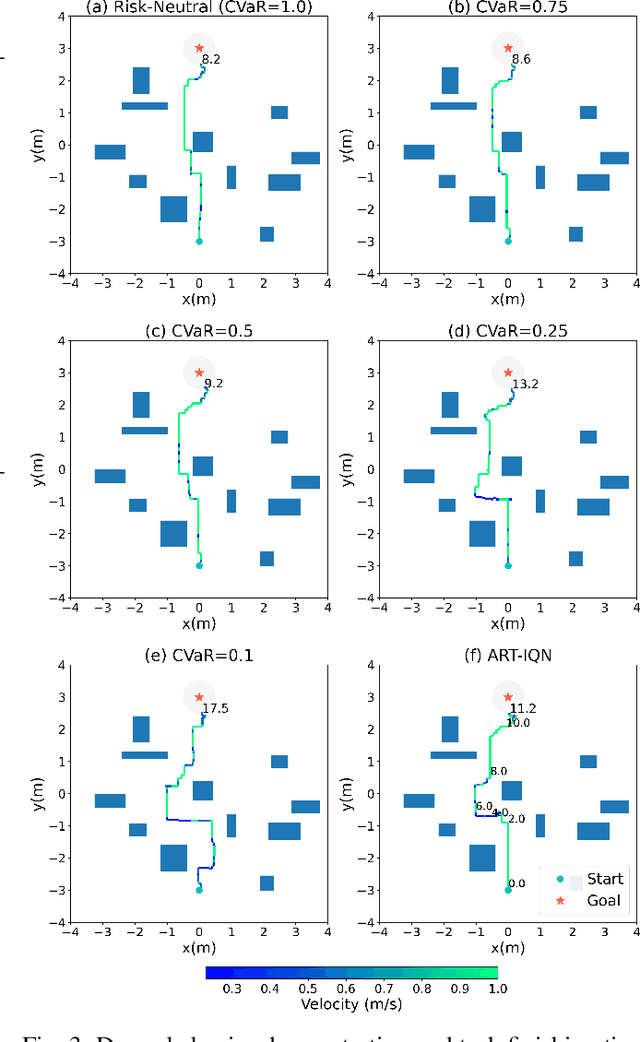
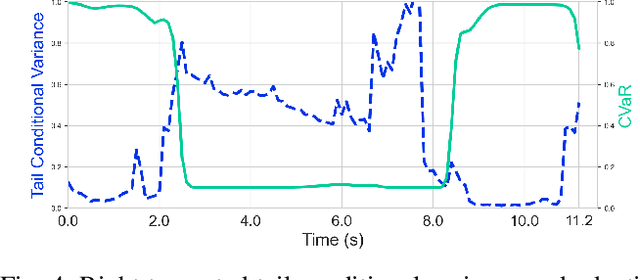
Enabling robots with the capability of assessing risk and making risk-aware decisions is widely considered a key step toward ensuring robustness for robots operating under uncertainty. In this paper, we consider the specific case of a nano drone robot learning to navigate an apriori unknown environment while avoiding obstacles under partial observability. We present a distributional reinforcement learning framework in order to learn adaptive risk tendency policies. Specifically, we propose to use tail conditional variance of the learnt action-value distribution as an uncertainty measurement, and use a exponentially weighted average forecasting algorithm to automatically adapt the risk-tendency at run-time based on the observed uncertainty in the environment. We show our algorithm can adjust its risk-sensitivity on the fly both in simulation and real-world experiments and achieving better performance than risk-neutral policy or risk-averse policies. Code and real-world experiment video can be found in this repository: \url{https://github.com/tudelft/risk-sensitive-rl.git}
Soft Actor-Critic Deep Reinforcement Learning for Fault Tolerant Flight Control
Feb 16, 2022Fault-tolerant flight control faces challenges, as developing a model-based controller for each unexpected failure is unrealistic, and online learning methods can handle limited system complexity due to their low sample efficiency. In this research, a model-free coupled-dynamics flight controller for a jet aircraft able to withstand multiple failure types is proposed. An offline trained cascaded Soft Actor-Critic Deep Reinforcement Learning controller is successful on highly coupled maneuvers, including a coordinated 40 degree bank climbing turn with a normalized Mean Absolute Error of 2.64%. The controller is robust to six failure cases, including the rudder jammed at -15 deg, the aileron effectiveness reduced by 70%, a structural failure, icing and a backward c.g. shift as the response is stable and the climbing turn is completed successfully. Robustness to biased sensor noise, atmospheric disturbances, and to varying initial flight conditions and reference signal shapes is also demonstrated.
On Approximate Dynamic Programming with Multivariate Splines for Adaptive Control
Jun 30, 2016
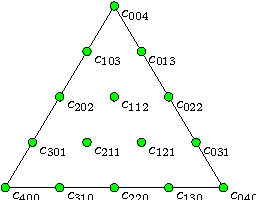

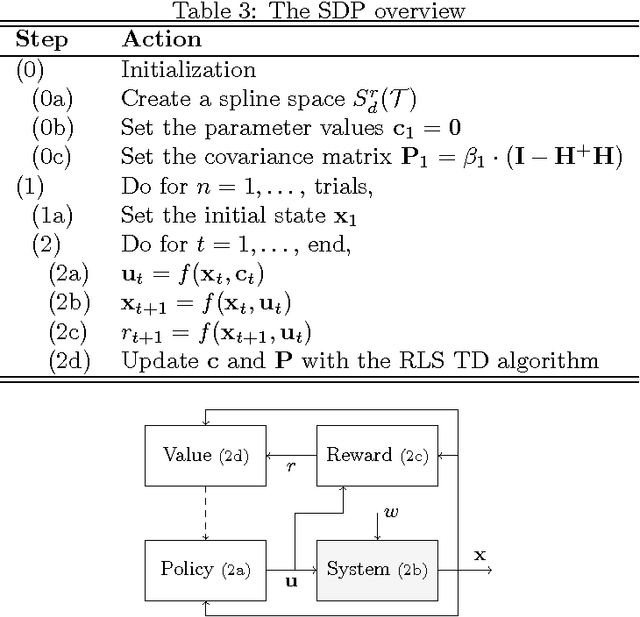
We define a SDP framework based on the RLSTD algorithm and multivariate simplex B-splines. We introduce a local forget factor capable of preserving the continuity of the simplex splines. This local forget factor is integrated with the RLSTD algorithm, resulting in a modified RLSTD algorithm that is capable of tracking time-varying systems. We present the results of two numerical experiments, one validating SDP and comparing it with NDP and another to show the advantages of the modified RLSTD algorithm over the original. While SDP requires more computations per time-step, the experiment shows that for the same amount of function approximator parameters, there is an increase in performance in terms of stability and learning rate compared to NDP. The second experiment shows that SDP in combination with the modified RLSTD algorithm allows for faster recovery compared to the original RLSTD algorithm when system parameters are altered, paving the way for an adaptive high-performance non-linear control method.