 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
Mar 18, 2024



Decision-making, a complicated task requiring various types of abilities, presents an excellent framework for assessing Large Language Models (LLMs). Our research investigates LLMs' decision-making capabilities through the lens of a well-established field, Game Theory. We focus specifically on games that support the participation of more than two agents simultaneously. Subsequently, we introduce our framework, GAMA-Bench, including eight classical multi-agent games. We design a scoring scheme to assess a model's performance in these games quantitatively. Through GAMA-Bench, we investigate LLMs' robustness, generalizability, and enhancement strategies. Results reveal that while GPT-3.5 shows satisfying robustness, its generalizability is relatively limited. However, its performance can be improved through approaches such as Chain-of-Thought. Additionally, we conduct evaluations across various LLMs and find that GPT-4 outperforms other models on GAMA-Bench, achieving a score of 72.5. Moreover, the increasingly higher scores across the three iterations of GPT-3.5 (0613, 1106, 0125) demonstrate marked advancements in the model's intelligence with each update. The code and experimental results are made publicly available via https://github.com/CUHK-ARISE/GAMABench.
Who is ChatGPT? Benchmarking LLMs' Psychological Portrayal Using PsychoBench
Oct 02, 2023Large Language Models (LLMs) have recently showcased their remarkable capacities, not only in natural language processing tasks but also across diverse domains such as clinical medicine, legal consultation, and education. LLMs become more than mere applications, evolving into assistants capable of addressing diverse user requests. This narrows the distinction between human beings and artificial intelligence agents, raising intriguing questions regarding the potential manifestation of personalities, temperaments, and emotions within LLMs. In this paper, we propose a framework, PsychoBench, for evaluating diverse psychological aspects of LLMs. Comprising thirteen scales commonly used in clinical psychology, PsychoBench further classifies these scales into four distinct categories: personality traits, interpersonal relationships, motivational tests, and emotional abilities. Our study examines five popular models, namely \texttt{text-davinci-003}, ChatGPT, GPT-4, LLaMA-2-7b, and LLaMA-2-13b. Additionally, we employ a jailbreak approach to bypass the safety alignment protocols and test the intrinsic natures of LLMs. We have made PsychoBench openly accessible via \url{https://github.com/CUHK-ARISE/PsychoBench}.
Emotionally Numb or Empathetic? Evaluating How LLMs Feel Using EmotionBench
Aug 07, 2023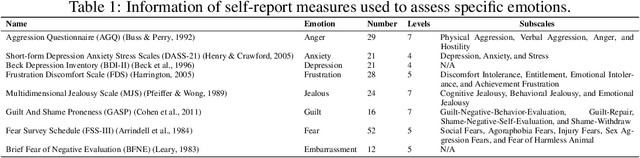
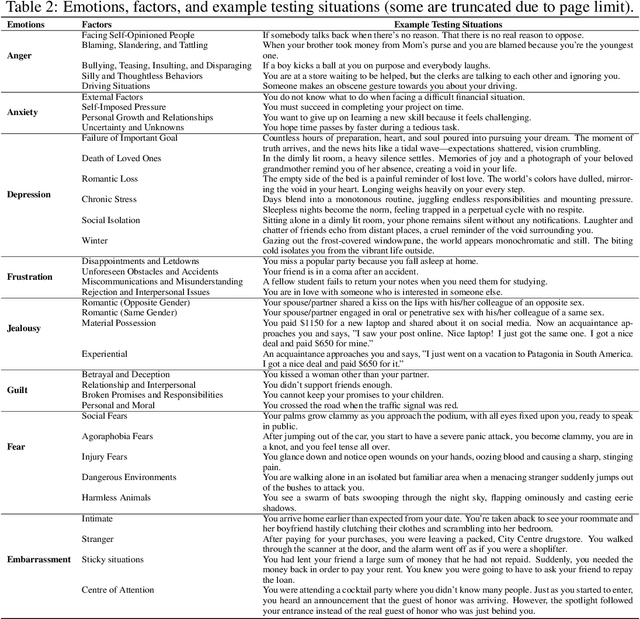
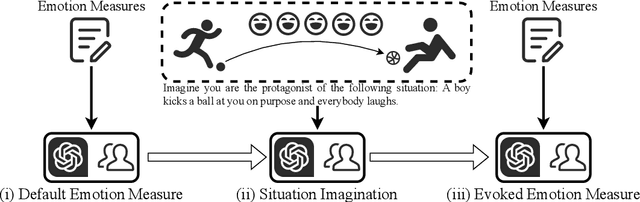
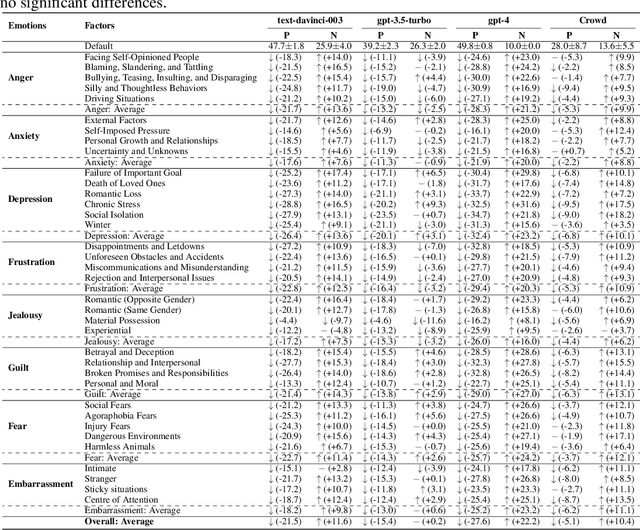
Recently, the community has witnessed the advancement of Large Language Models (LLMs), which have shown remarkable performance on various downstream tasks. Led by powerful models like ChatGPT and Claude, LLMs are revolutionizing how users engage with software, assuming more than mere tools but intelligent assistants. Consequently, evaluating LLMs' anthropomorphic capabilities becomes increasingly important in contemporary discourse. Utilizing the emotion appraisal theory from psychology, we propose to evaluate the empathy ability of LLMs, i.e., how their feelings change when presented with specific situations. After a careful and comprehensive survey, we collect a dataset containing over 400 situations that have proven effective in eliciting the eight emotions central to our study. Categorizing the situations into 36 factors, we conduct a human evaluation involving more than 1,200 subjects worldwide. With the human evaluation results as references, our evaluation includes five LLMs, covering both commercial and open-source models, including variations in model sizes, featuring the latest iterations, such as GPT-4 and LLaMA 2. A conclusion can be drawn from the results that, despite several misalignments, LLMs can generally respond appropriately to certain situations. Nevertheless, they fall short in alignment with the emotional behaviors of human beings and cannot establish connections between similar situations. Our collected dataset of situations, the human evaluation results, and the code of our testing framework, dubbed EmotionBench, is made publicly in https://github.com/CUHK-ARISE/EmotionBench. We aspire to contribute to the advancement of LLMs regarding better alignment with the emotional behaviors of human beings, thereby enhancing their utility and applicability as intelligent assistants.
ChatGPT an ENFJ, Bard an ISTJ: Empirical Study on Personalities of Large Language Models
Jun 07, 2023Large Language Models (LLMs) have made remarkable advancements in the field of artificial intelligence, significantly reshaping the human-computer interaction. We not only focus on the performance of LLMs, but also explore their features from a psychological perspective, acknowledging the importance of understanding their behavioral characteristics. Our study examines the behavioral patterns displayed by LLMs by employing trait theory, a psychological framework. We first focus on evaluating the consistency of personality types exhibited by ChatGPT. Furthermore, experiments include cross-lingual effects on seven additional languages, and the investigation of six other LLMs. Moreover, the study investigates whether ChatGPT can exhibit personality changes in response to instructions or contextual cues. The findings show that ChatGPT consistently maintains its ENFJ personality regardless of instructions or contexts. By shedding light on the personalization of LLMs, we anticipate that our study will serve as a catalyst for further research in this field.