 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Deep Learning Techniques for Accurate Lung Cancer Detection and Classification
Aug 08, 2025Lung cancer (LC) ranks among the most frequently diagnosed cancers and is one of the most common causes of death for men and women worldwide. Computed Tomography (CT) images are the most preferred diagnosis method because of their low cost and their faster processing times. Many researchers have proposed various ways of identifying lung cancer using CT images. However, such techniques suffer from significant false positives, leading to low accuracy. The fundamental reason results from employing a small and imbalanced dataset. This paper introduces an innovative approach for LC detection and classification from CT images based on the DenseNet201 model. Our approach comprises several advanced methods such as Focal Loss, data augmentation, and regularization to overcome the imbalanced data issue and overfitting challenge. The findings show the appropriateness of the proposal, attaining a promising performance of 98.95% accuracy.
Automatic detection of cognitive impairment in elderly people using an entertainment chatbot with Natural Language Processing capabilities
May 28, 2024Previous researchers have proposed intelligent systems for therapeutic monitoring of cognitive impairments. However, most existing practical approaches for this purpose are based on manual tests. This raises issues such as excessive caretaking effort and the white-coat effect. To avoid these issues, we present an intelligent conversational system for entertaining elderly people with news of their interest that monitors cognitive impairment transparently. Automatic chatbot dialogue stages allow assessing content description skills and detecting cognitive impairment with Machine Learning algorithms. We create these dialogue flows automatically from updated news items using Natural Language Generation techniques. The system also infers the gold standard of the answers to the questions, so it can assess cognitive capabilities automatically by comparing these answers with the user responses. It employs a similarity metric with values in [0, 1], in increasing level of similarity. To evaluate the performance and usability of our approach, we have conducted field tests with a test group of 30 elderly people in the earliest stages of dementia, under the supervision of gerontologists. In the experiments, we have analysed the effect of stress and concentration in these users. Those without cognitive impairment performed up to five times better. In particular, the similarity metric varied between 0.03, for stressed and unfocused participants, and 0.36, for relaxed and focused users. Finally, we developed a Machine Learning algorithm based on textual analysis features for automatic cognitive impairment detection, which attained accuracy, F-measure and recall levels above 80%. We have thus validated the automatic approach to detect cognitive impairment in elderly people based on entertainment content.
A Library for Automatic Natural Language Generation of Spanish Texts
May 27, 2024
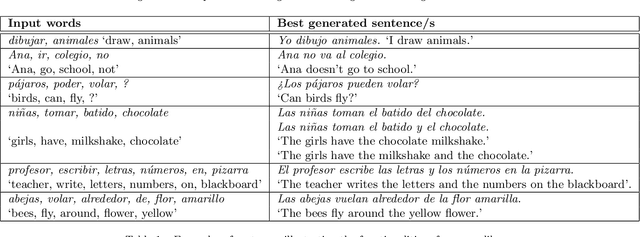

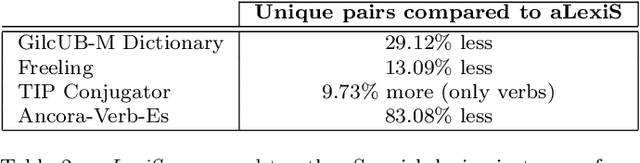
In this article we present a novel system for natural language generation (NLG) of Spanish sentences from a minimum set of meaningful words (such as nouns, verbs and adjectives) which, unlike other state-of-the-art solutions, performs the NLG task in a fully automatic way, exploiting both knowledge-based and statistical approaches. Relying on its linguistic knowledge of vocabulary and grammar, the system is able to generate complete, coherent and correctly spelled sentences from the main word sets presented by the user. The system, which was designed to be integrable, portable and efficient, can be easily adapted to other languages by design and can feasibly be integrated in a wide range of digital devices. During its development we also created a supplementary lexicon for Spanish, aLexiS, with wide coverage and high precision, as well as syntactic trees from a freely available definite-clause grammar. The resulting NLG library has been evaluated both automatically and manually (annotation). The system can potentially be used in different application domains such as augmentative communication and automatic generation of administrative reports or news.
Creating emoji lexica from unsupervised sentiment analysis of their descriptions
Apr 01, 2024
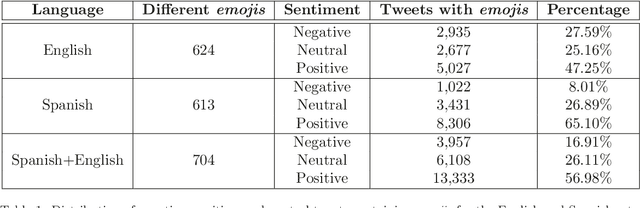
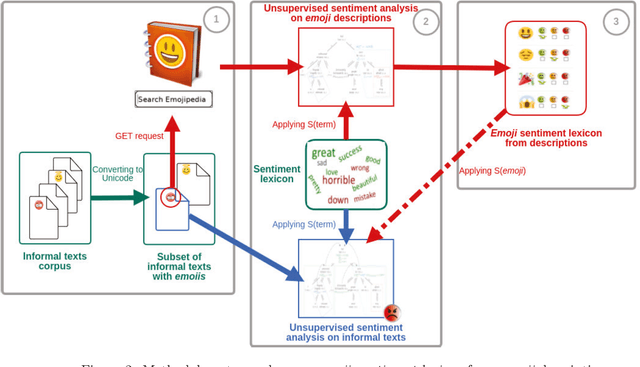
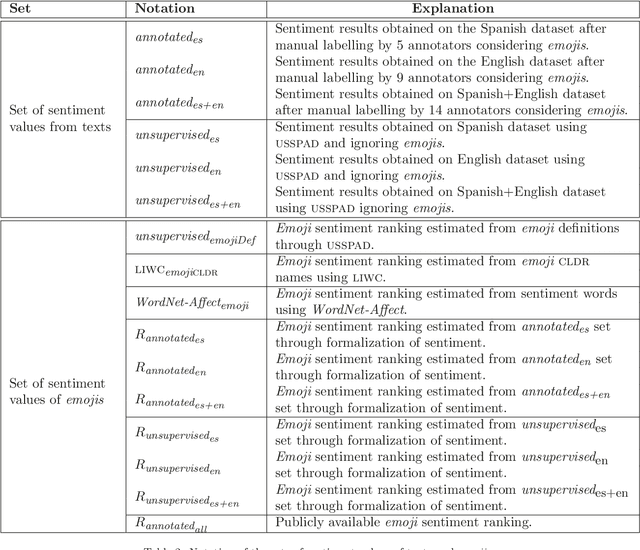
Online media, such as blogs and social networking sites, generate massive volumes of unstructured data of great interest to analyze the opinions and sentiments of individuals and organizations. Novel approaches beyond Natural Language Processing are necessary to quantify these opinions with polarity metrics. So far, the sentiment expressed by emojis has received little attention. The use of symbols, however, has boomed in the past four years. About twenty billion are typed in Twitter nowadays, and new emojis keep appearing in each new Unicode version, making them increasingly relevant to sentiment analysis tasks. This has motivated us to propose a novel approach to predict the sentiments expressed by emojis in online textual messages, such as tweets, that does not require human effort to manually annotate data and saves valuable time for other analysis tasks. For this purpose, we automatically constructed a novel emoji sentiment lexicon using an unsupervised sentiment analysis system based on the definitions given by emoji creators in Emojipedia. Additionally, we automatically created lexicon variants by also considering the sentiment distribution of the informal texts accompanying emojis. All these lexica are evaluated and compared regarding the improvement obtained by including them in sentiment analysis of the annotated datasets provided by Kralj Novak et al. (2015). The results confirm the competitiveness of our approach.
Automatic detection of relevant information, predictions and forecasts in financial news through topic modelling with Latent Dirichlet Allocation
Mar 30, 2024Financial news items are unstructured sources of information that can be mined to extract knowledge for market screening applications. Manual extraction of relevant information from the continuous stream of finance-related news is cumbersome and beyond the skills of many investors, who, at most, can follow a few sources and authors. Accordingly, we focus on the analysis of financial news to identify relevant text and, within that text, forecasts and predictions. We propose a novel Natural Language Processing (NLP) system to assist investors in the detection of relevant financial events in unstructured textual sources by considering both relevance and temporality at the discursive level. Firstly, we segment the text to group together closely related text. Secondly, we apply co-reference resolution to discover internal dependencies within segments. Finally, we perform relevant topic modelling with Latent Dirichlet Allocation (LDA) to separate relevant from less relevant text and then analyse the relevant text using a Machine Learning-oriented temporal approach to identify predictions and speculative statements. We created an experimental data set composed of 2,158 financial news items that were manually labelled by NLP researchers to evaluate our solution. The ROUGE-L values for the identification of relevant text and predictions/forecasts were 0.662 and 0.982, respectively. To our knowledge, this is the first work to jointly consider relevance and temporality at the discursive level. It contributes to the transfer of human associative discourse capabilities to expert systems through the combination of multi-paragraph topic segmentation and co-reference resolution to separate author expression patterns, topic modelling with LDA to detect relevant text, and discursive temporality analysis to identify forecasts and predictions within this text.