 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Library for Automatic Natural Language Generation of Spanish Texts
May 27, 2024
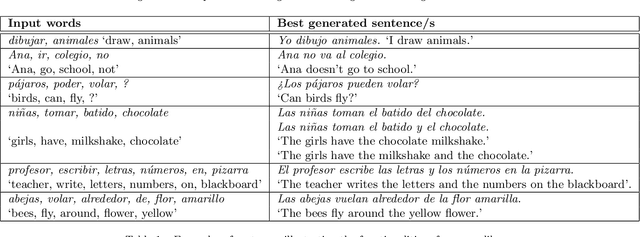

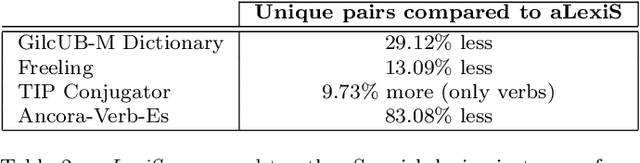
In this article we present a novel system for natural language generation (NLG) of Spanish sentences from a minimum set of meaningful words (such as nouns, verbs and adjectives) which, unlike other state-of-the-art solutions, performs the NLG task in a fully automatic way, exploiting both knowledge-based and statistical approaches. Relying on its linguistic knowledge of vocabulary and grammar, the system is able to generate complete, coherent and correctly spelled sentences from the main word sets presented by the user. The system, which was designed to be integrable, portable and efficient, can be easily adapted to other languages by design and can feasibly be integrated in a wide range of digital devices. During its development we also created a supplementary lexicon for Spanish, aLexiS, with wide coverage and high precision, as well as syntactic trees from a freely available definite-clause grammar. The resulting NLG library has been evaluated both automatically and manually (annotation). The system can potentially be used in different application domains such as augmentative communication and automatic generation of administrative reports or news.
Creating emoji lexica from unsupervised sentiment analysis of their descriptions
Apr 01, 2024
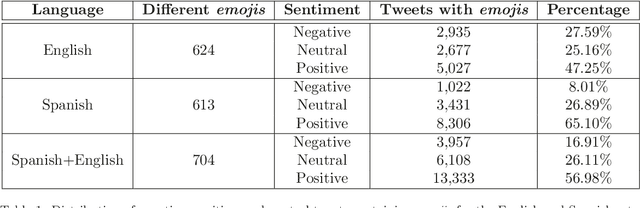
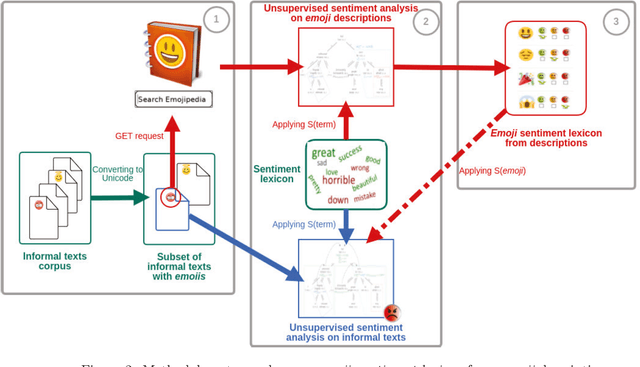
Online media, such as blogs and social networking sites, generate massive volumes of unstructured data of great interest to analyze the opinions and sentiments of individuals and organizations. Novel approaches beyond Natural Language Processing are necessary to quantify these opinions with polarity metrics. So far, the sentiment expressed by emojis has received little attention. The use of symbols, however, has boomed in the past four years. About twenty billion are typed in Twitter nowadays, and new emojis keep appearing in each new Unicode version, making them increasingly relevant to sentiment analysis tasks. This has motivated us to propose a novel approach to predict the sentiments expressed by emojis in online textual messages, such as tweets, that does not require human effort to manually annotate data and saves valuable time for other analysis tasks. For this purpose, we automatically constructed a novel emoji sentiment lexicon using an unsupervised sentiment analysis system based on the definitions given by emoji creators in Emojipedia. Additionally, we automatically created lexicon variants by also considering the sentiment distribution of the informal texts accompanying emojis. All these lexica are evaluated and compared regarding the improvement obtained by including them in sentiment analysis of the annotated datasets provided by Kralj Novak et al. (2015). The results confirm the competitiveness of our approach.