 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Analysis of Gradient Descent for Shallow Transformers
Jan 23, 2026Understanding why Transformers perform so well remains challenging due to their non-convex optimization landscape. In this work, we analyze a shallow Transformer with $m$ independent heads trained by projected gradient descent in the kernel regime. Our analysis reveals two main findings: (i) the width required for nonasymptotic guarantees scales only logarithmically with the sample size $n$, and (ii) the optimization error is independent of the sequence length $T$. This contrasts sharply with recurrent architectures, where the optimization error can grow exponentially with $T$. The trade-off is memory: to keep the full context, the Transformer's memory requirement grows with the sequence length. We validate our theoretical results numerically in a teacher-student setting and confirm the predicted scaling laws for Transformers.
Semantic Forwarding for Next Generation Relay Networks
Jan 30, 2024
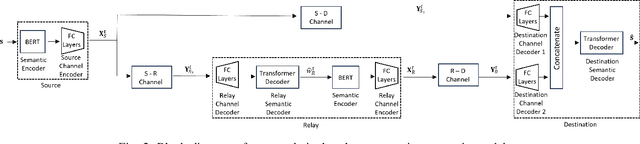
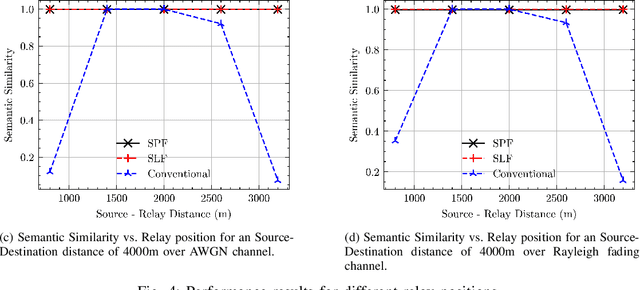
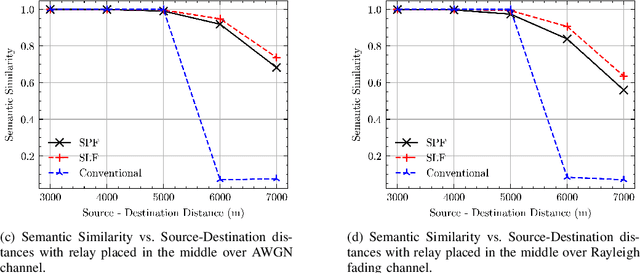
We consider cooperative semantic text communications facilitated by a relay node. We propose two types of semantic forwarding: semantic lossy forwarding (SLF) and semantic predict-and-forward (SPF). Both are machine learning aided approaches, and, in particular, utilize attention mechanisms at the relay to establish a dynamic semantic state, updated upon receiving a new source signal. In the SLF model, the semantic state is used to decode the received source signal; whereas in the SPF model, it is used to predict the next source signal, enabling proactive forwarding. Our proposed forwarding schemes do not need any channel state information and exhibit consistent performance regardless of the relay's position. Our results demonstrate that the proposed semantic forwarding techniques outperform conventional semantic-agnostic baselines.