 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Moments: Extensions and Sparse-Smooth Attacks
Jun 21, 2020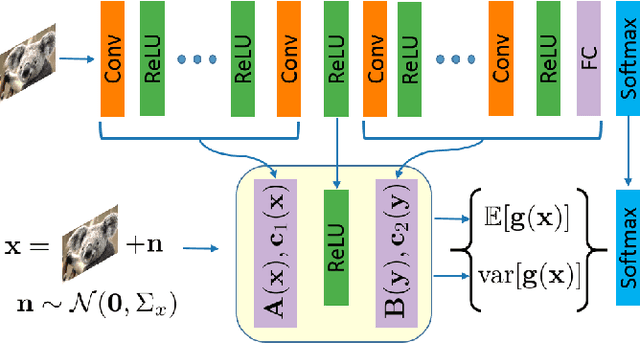
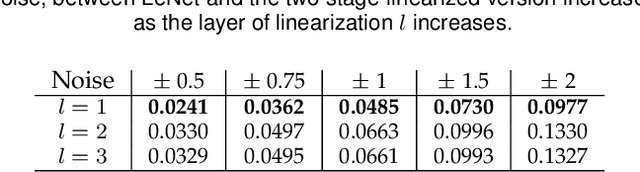
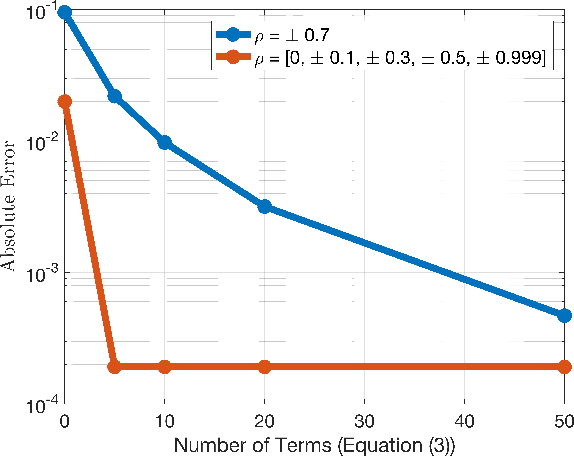
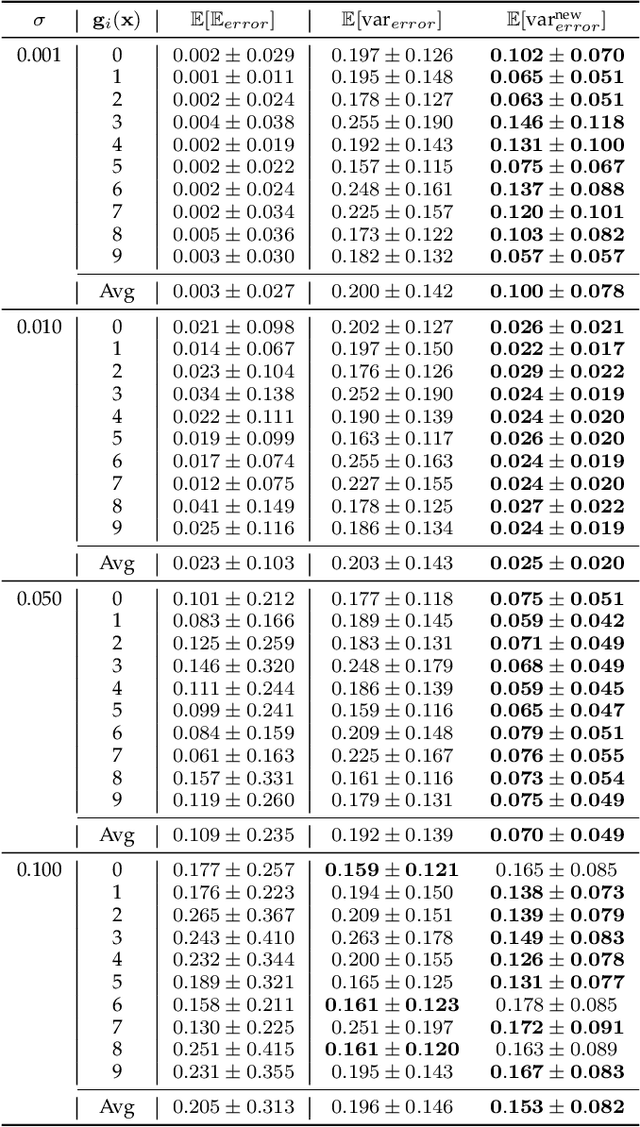
The impressive performance of deep neural networks (DNNs) has immensely strengthened the line of research that aims at theoretically analyzing their effectiveness. This has incited research on the reaction of DNNs to noisy input, namely developing adversarial input attacks and strategies that lead to robust DNNs to these attacks. To that end, in this paper, we derive exact analytic expressions for the first and second moments (mean and variance) of a small piecewise linear (PL) network (Affine, ReLU, Affine) subject to Gaussian input. In particular, we generalize the second-moment expression of Bibi et al. to arbitrary input Gaussian distributions, dropping the zero-mean assumption. We show that the new variance expression can be efficiently approximated leading to much tighter variance estimates as compared to the preliminary results of Bibi et al. Moreover, we experimentally show that these expressions are tight under simple linearizations of deeper PL-DNNs, where we investigate the effect of the linearization sensitivity on the accuracy of the moment estimates. Lastly, we show that the derived expressions can be used to construct sparse and smooth Gaussian adversarial attacks (targeted and non-targeted) that tend to lead to perceptually feasible input attacks.
Dynamic Multimodal Instance Segmentation guided by natural language queries
Jul 22, 2018
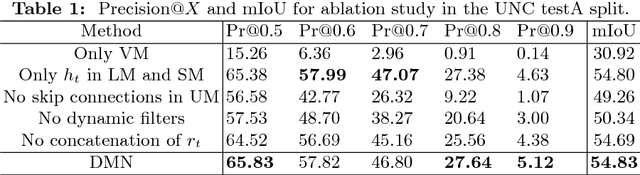
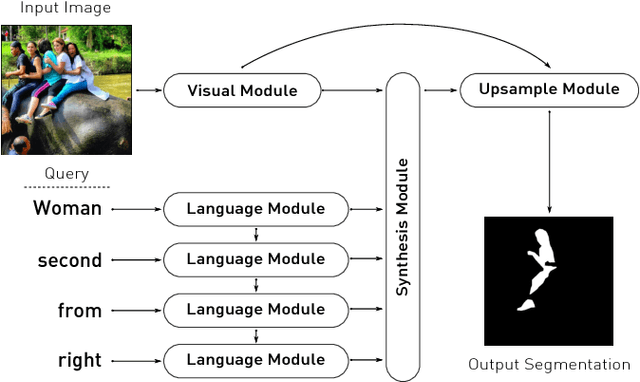
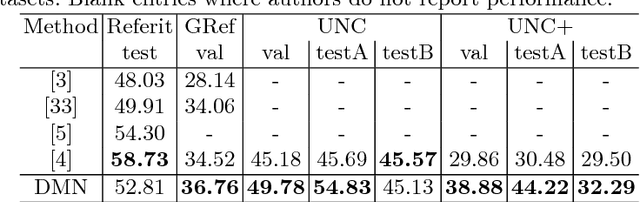
We address the problem of segmenting an object given a natural language expression that describes it. Current techniques tackle this task by either (\textit{i}) directly or recursively merging linguistic and visual information in the channel dimension and then performing convolutions; or by (\textit{ii}) mapping the expression to a space in which it can be thought of as a filter, whose response is directly related to the presence of the object at a given spatial coordinate in the image, so that a convolution can be applied to look for the object. We propose a novel method that integrates these two insights in order to fully exploit the recursive nature of language. Additionally, during the upsampling process, we take advantage of the intermediate information generated when downsampling the image, so that detailed segmentations can be obtained. We compare our method against the state-of-the-art approaches in four standard datasets, in which it surpasses all previous methods in six of eight of the splits for this task.