 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Multimodal Instance Segmentation guided by natural language queries
Paper and Code

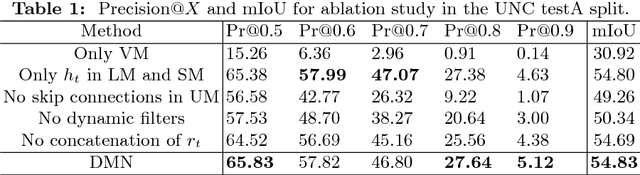
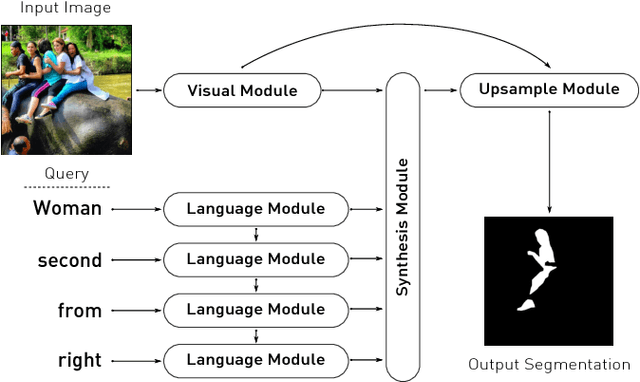
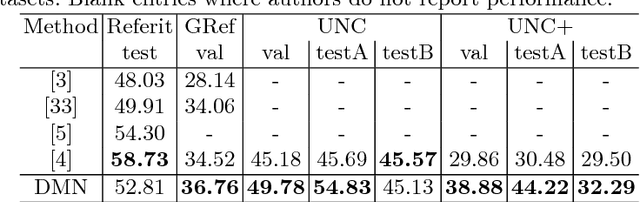
We address the problem of segmenting an object given a natural language expression that describes it. Current techniques tackle this task by either (\textit{i}) directly or recursively merging linguistic and visual information in the channel dimension and then performing convolutions; or by (\textit{ii}) mapping the expression to a space in which it can be thought of as a filter, whose response is directly related to the presence of the object at a given spatial coordinate in the image, so that a convolution can be applied to look for the object. We propose a novel method that integrates these two insights in order to fully exploit the recursive nature of language. Additionally, during the upsampling process, we take advantage of the intermediate information generated when downsampling the image, so that detailed segmentations can be obtained. We compare our method against the state-of-the-art approaches in four standard datasets, in which it surpasses all previous methods in six of eight of the splits for this task.