 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition
Oct 19, 2021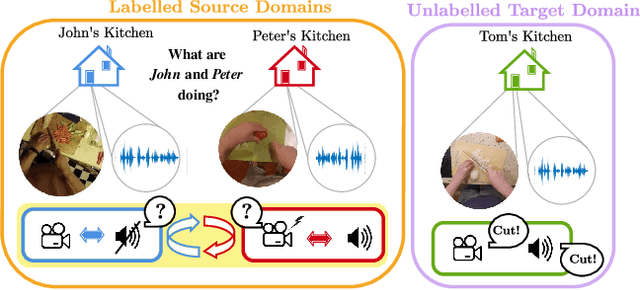
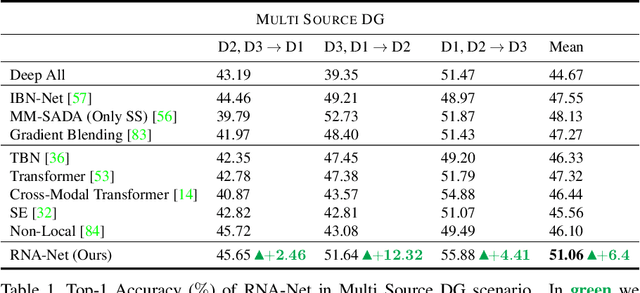
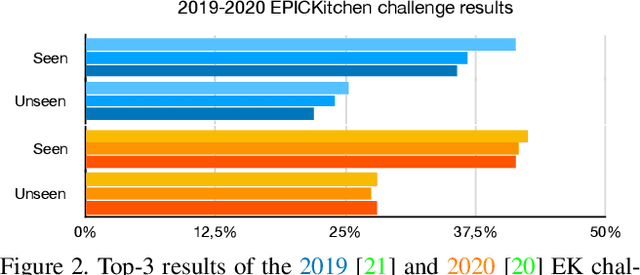
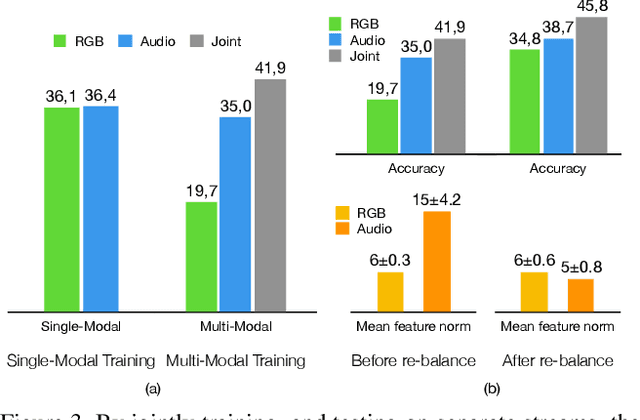
First person action recognition is becoming an increasingly researched area thanks to the rising popularity of wearable cameras. This is bringing to light cross-domain issues that are yet to be addressed in this context. Indeed, the information extracted from learned representations suffers from an intrinsic "environmental bias". This strongly affects the ability to generalize to unseen scenarios, limiting the application of current methods to real settings where labeled data are not available during training. In this work, we introduce the first domain generalization approach for egocentric activity recognition, by proposing a new audio-visual loss, called Relative Norm Alignment loss. It re-balances the contributions from the two modalities during training, over different domains, by aligning their feature norm representations. Our approach leads to strong results in domain generalization on both EPIC-Kitchens-55 and EPIC-Kitchens-100, as demonstrated by extensive experiments, and can be extended to work also on domain adaptation settings with competitive results.
PoliTO-IIT Submission to the EPIC-KITCHENS-100 Unsupervised Domain Adaptation Challenge for Action Recognition
Jul 01, 2021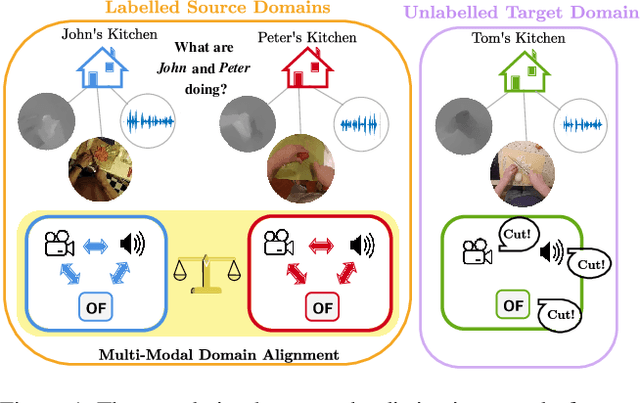


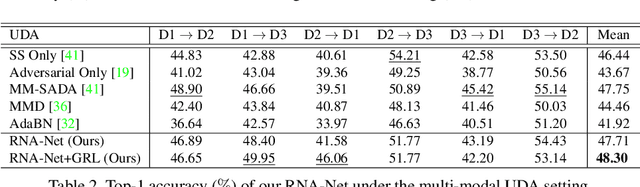
In this report, we describe the technical details of our submission to the EPIC-Kitchens-100 Unsupervised Domain Adaptation (UDA) Challenge in Action Recognition. To tackle the domain-shift which exists under the UDA setting, we first exploited a recent Domain Generalization (DG) technique, called Relative Norm Alignment (RNA). It consists in designing a model able to generalize well to any unseen domain, regardless of the possibility to access target data at training time. Then, in a second phase, we extended the approach to work on unlabelled target data, allowing the model to adapt to the target distribution in an unsupervised fashion. For this purpose, we included in our framework existing UDA algorithms, such as Temporal Attentive Adversarial Adaptation Network (TA3N), jointly with new multi-stream consistency losses, namely Temporal Hard Norm Alignment (T-HNA) and Min-Entropy Consistency (MEC). Our submission (entry 'plnet') is visible on the leaderboard and it achieved the 1st position for 'verb', and the 3rd position for both 'noun' and 'action'.
Cross-Domain First Person Audio-Visual Action Recognition through Relative Norm Alignment
Jun 03, 2021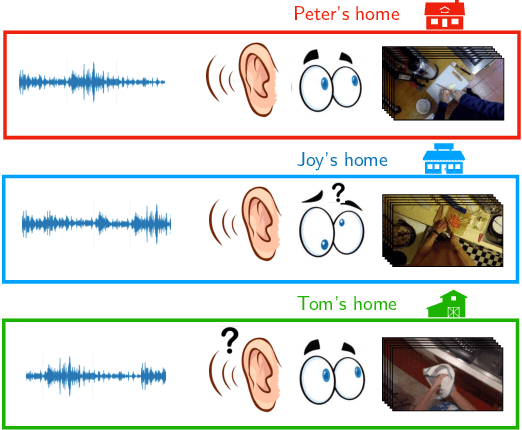

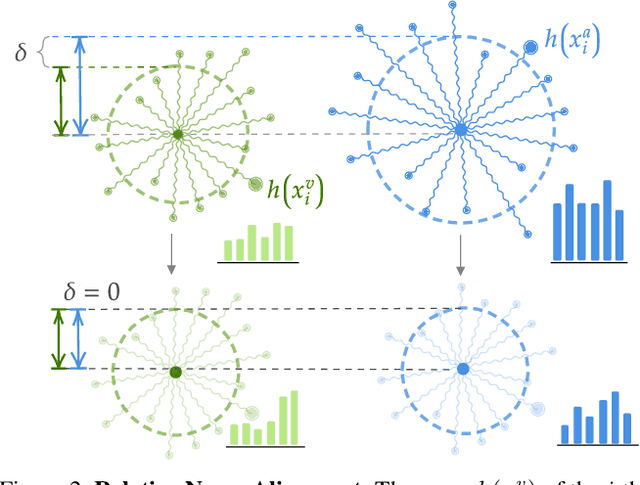
First person action recognition is an increasingly researched topic because of the growing popularity of wearable cameras. This is bringing to light cross-domain issues that are yet to be addressed in this context. Indeed, the information extracted from learned representations suffers from an intrinsic environmental bias. This strongly affects the ability to generalize to unseen scenarios, limiting the application of current methods in real settings where trimmed labeled data are not available during training. In this work, we propose to leverage over the intrinsic complementary nature of audio-visual signals to learn a representation that works well on data seen during training, while being able to generalize across different domains. To this end, we introduce an audio-visual loss that aligns the contributions from the two modalities by acting on the magnitude of their feature norm representations. This new loss, plugged into a minimal multi-modal action recognition architecture, leads to strong results in cross-domain first person action recognition, as demonstrated by extensive experiments on the popular EPIC-Kitchens dataset.
IDDA: a large-scale multi-domain dataset for autonomous driving
Apr 17, 2020

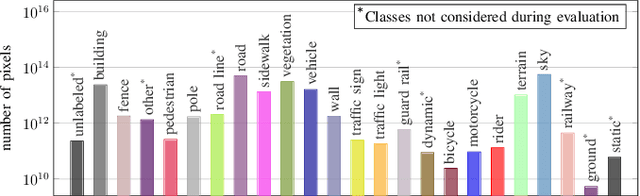
Semantic segmentation is key in autonomous driving. Using deep visual learning architectures is not trivial in this context, because of the challenges in creating suitable large scale annotated datasets. This issue has been traditionally circumvented through the use of synthetic datasets, that have become a popular resource in this field. They have been released with the need to develop semantic segmentation algorithms able to close the visual domain shift between the training and test data. Although exacerbated by the use of artificial data, the problem is extremely relevant in this field even when training on real data. Indeed, weather conditions, viewpoint changes and variations in the city appearances can vary considerably from car to car, and even at test time for a single, specific vehicle. How to deal with domain adaptation in semantic segmentation, and how to leverage effectively several different data distributions (source domains) are important research questions in this field. To support work in this direction, this paper contributes a new large scale, synthetic dataset for semantic segmentation with more than 100 different source visual domains. The dataset has been created to explicitly address the challenges of domain shift between training and test data in various weather and view point conditions, in seven different city types. Extensive benchmark experiments assess the dataset, showcasing open challenges for the current state of the art. The dataset will be available at: https://idda-dataset.github.io/home/ .