 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeries of Hessian-Vector Products for Tractable Saddle-Free Newton Optimisation of Neural Networks
Oct 23, 2023Despite their popularity in the field of continuous optimisation, second-order quasi-Newton methods are challenging to apply in machine learning, as the Hessian matrix is intractably large. This computational burden is exacerbated by the need to address non-convexity, for instance by modifying the Hessian's eigenvalues as in Saddle-Free Newton methods. We propose an optimisation algorithm which addresses both of these concerns - to our knowledge, the first efficiently-scalable optimisation algorithm to asymptotically use the exact (eigenvalue-modified) inverse Hessian. Our method frames the problem as a series which principally square-roots and inverts the squared Hessian, then uses it to precondition a gradient vector, all without explicitly computing or eigendecomposing the Hessian. A truncation of this infinite series provides a new optimisation algorithm which is scalable and comparable to other first- and second-order optimisation methods in both runtime and optimisation performance. We demonstrate this in a variety of settings, including a ResNet-18 trained on CIFAR-10.
Adversarial Attacks are a Surprisingly Strong Baseline for Poisoning Few-Shot Meta-Learners
Nov 23, 2022



This paper examines the robustness of deployed few-shot meta-learning systems when they are fed an imperceptibly perturbed few-shot dataset. We attack amortized meta-learners, which allows us to craft colluding sets of inputs that are tailored to fool the system's learning algorithm when used as training data. Jointly crafted adversarial inputs might be expected to synergistically manipulate a classifier, allowing for very strong data-poisoning attacks that would be hard to detect. We show that in a white box setting, these attacks are very successful and can cause the target model's predictions to become worse than chance. However, in opposition to the well-known transferability of adversarial examples in general, the colluding sets do not transfer well to different classifiers. We explore two hypotheses to explain this: 'overfitting' by the attack, and mismatch between the model on which the attack is generated and that to which the attack is transferred. Regardless of the mitigation strategies suggested by these hypotheses, the colluding inputs transfer no better than adversarial inputs that are generated independently in the usual way.
Scalable One-Pass Optimisation of High-Dimensional Weight-Update Hyperparameters by Implicit Differentiation
Oct 20, 2021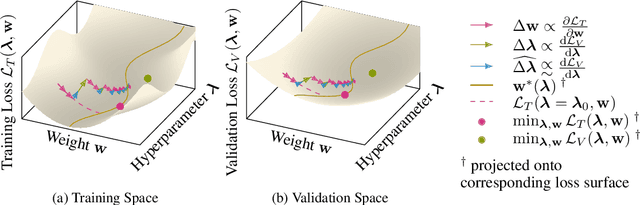
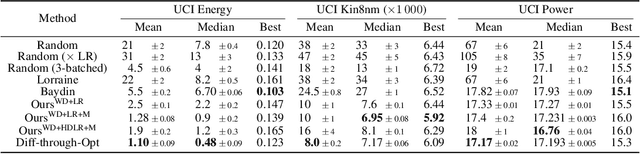
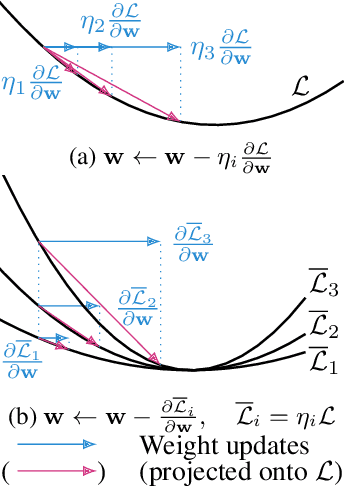
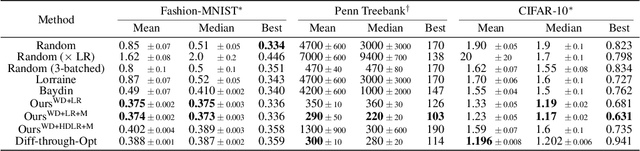
Machine learning training methods depend plentifully and intricately on hyperparameters, motivating automated strategies for their optimisation. Many existing algorithms restart training for each new hyperparameter choice, at considerable computational cost. Some hypergradient-based one-pass methods exist, but these either cannot be applied to arbitrary optimiser hyperparameters (such as learning rates and momenta) or take several times longer to train than their base models. We extend these existing methods to develop an approximate hypergradient-based hyperparameter optimiser which is applicable to any continuous hyperparameter appearing in a differentiable model weight update, yet requires only one training episode, with no restarts. We also provide a motivating argument for convergence to the true hypergradient, and perform tractable gradient-based optimisation of independent learning rates for each model parameter. Our method performs competitively from varied random hyperparameter initialisations on several UCI datasets and Fashion-MNIST (using a one-layer MLP), Penn Treebank (using an LSTM) and CIFAR-10 (using a ResNet-18), in time only 2-3x greater than vanilla training.