 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphDART: Graph Distillation for Efficient Advanced Persistent Threat Detection
Jan 06, 2025



Cyber-physical-social systems (CPSSs) have emerged in many applications over recent decades, requiring increased attention to security concerns. The rise of sophisticated threats like Advanced Persistent Threats (APTs) makes ensuring security in CPSSs particularly challenging. Provenance graph analysis has proven effective for tracing and detecting anomalies within systems, but the sheer size and complexity of these graphs hinder the efficiency of existing methods, especially those relying on graph neural networks (GNNs). To address these challenges, we present GraphDART, a modular framework designed to distill provenance graphs into compact yet informative representations, enabling scalable and effective anomaly detection. GraphDART can take advantage of diverse graph distillation techniques, including classic and modern graph distillation methods, to condense large provenance graphs while preserving essential structural and contextual information. This approach significantly reduces computational overhead, allowing GNNs to learn from distilled graphs efficiently and enhance detection performance. Extensive evaluations on benchmark datasets demonstrate the robustness of GraphDART in detecting malicious activities across cyber-physical-social systems. By optimizing computational efficiency, GraphDART provides a scalable and practical solution to safeguard interconnected environments against APTs.
Fast, Accurate and Interpretable Time Series Classification Through Randomization
May 31, 2021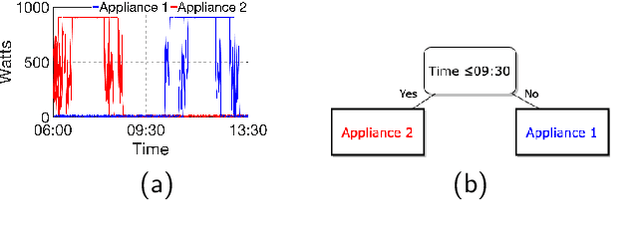
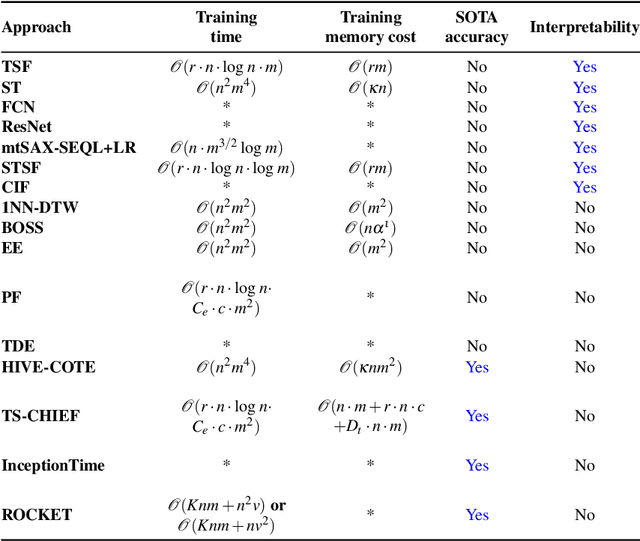
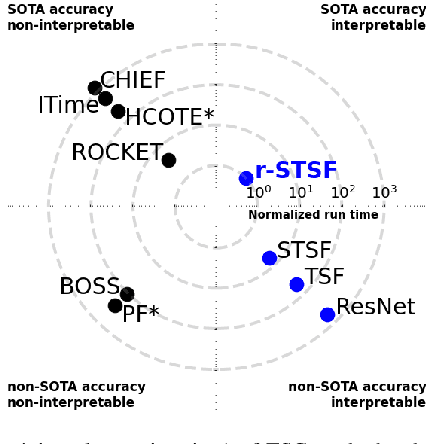

Time series classification (TSC) aims to predict the class label of a given time series, which is critical to a rich set of application areas such as economics and medicine. State-of-the-art TSC methods have mostly focused on classification accuracy and efficiency, without considering the interpretability of their classifications, which is an important property required by modern applications such as appliance modeling and legislation such as the European General Data Protection Regulation. To address this gap, we propose a novel TSC method - the Randomized-Supervised Time Series Forest (r-STSF). r-STSF is highly efficient, achieves state-of-the-art classification accuracy and enables interpretability. r-STSF takes an efficient interval-based approach to classify time series according to aggregate values of discriminatory sub-series (intervals). To achieve state-of-the-art accuracy, r-STSF builds an ensemble of randomized trees using the discriminatory sub-series. It uses four time series representations, nine aggregation functions and a supervised binary-inspired search combined with a feature ranking metric to identify highly discriminatory sub-series. The discriminatory sub-series enable interpretable classifications. Experiments on extensive datasets show that r-STSF achieves state-of-the-art accuracy while being orders of magnitude faster than most existing TSC methods. It is the only classifier from the state-of-the-art group that enables interpretability. Our findings also highlight that r-STSF is the best TSC method when classifying complex time series datasets.