 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 22, 2024



$\textbf{Background}$: Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. $\textbf{Methods}$: We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. $\textbf{Results}$: MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10^-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). $\textbf{Conclusion}$: Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
The unreasonable effectiveness of AI CADe polyp detectors to generalize to new countries
Dec 17, 2023$\textbf{Background and aims}$: Artificial Intelligence (AI) Computer-Aided Detection (CADe) is commonly used for polyp detection, but data seen in clinical settings can differ from model training. Few studies evaluate how well CADe detectors perform on colonoscopies from countries not seen during training, and none are able to evaluate performance without collecting expensive and time-intensive labels. $\textbf{Methods}$: We trained a CADe polyp detector on Israeli colonoscopy videos (5004 videos, 1106 hours) and evaluated on Japanese videos (354 videos, 128 hours) by measuring the True Positive Rate (TPR) versus false alarms per minute (FAPM). We introduce a colonoscopy dissimilarity measure called "MAsked mediCal Embedding Distance" (MACE) to quantify differences between colonoscopies, without labels. We evaluated CADe on all Japan videos and on those with the highest MACE. $\textbf{Results}$: MACE correctly quantifies that narrow-band imaging (NBI) and chromoendoscopy (CE) frames are less similar to Israel data than Japan whitelight (bootstrapped z-test, |z| > 690, p < $10^{-8}$ for both). Despite differences in the data, CADe performance on Japan colonoscopies was non-inferior to Israel ones without additional training (TPR at 0.5 FAPM: 0.957 and 0.972 for Israel and Japan; TPR at 1.0 FAPM: 0.972 and 0.989 for Israel and Japan; superiority test t > 45.2, p < $10^{-8}$). Despite not being trained on NBI or CE, TPR on those subsets were non-inferior to Japan overall (non-inferiority test t > 47.3, p < $10^{-8}$, $\delta$ = 1.5% for both). $\textbf{Conclusion}$: Differences that prevent CADe detectors from performing well in non-medical settings do not degrade the performance of our AI CADe polyp detector when applied to data from a new country. MACE can help medical AI models internationalize by identifying the most "dissimilar" data on which to evaluate models.
Feature-based model selection for object detection from point cloud data
Sep 26, 2022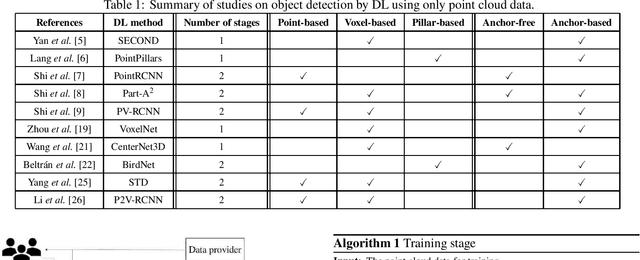
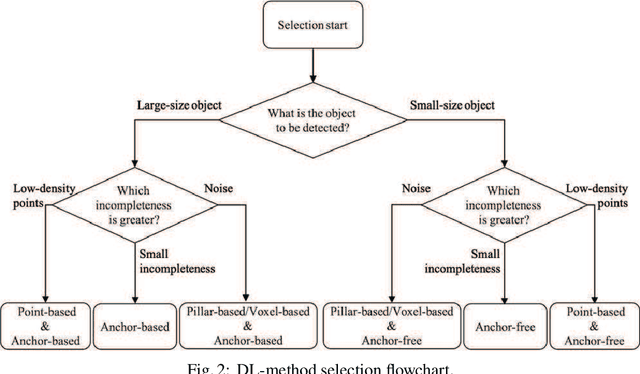
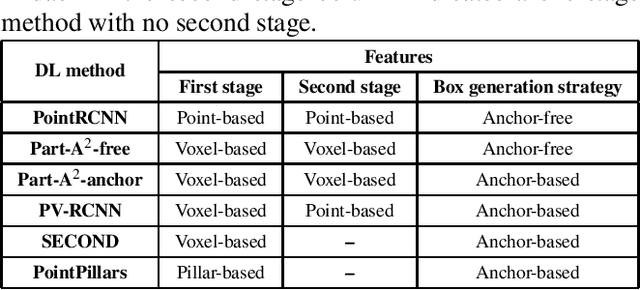
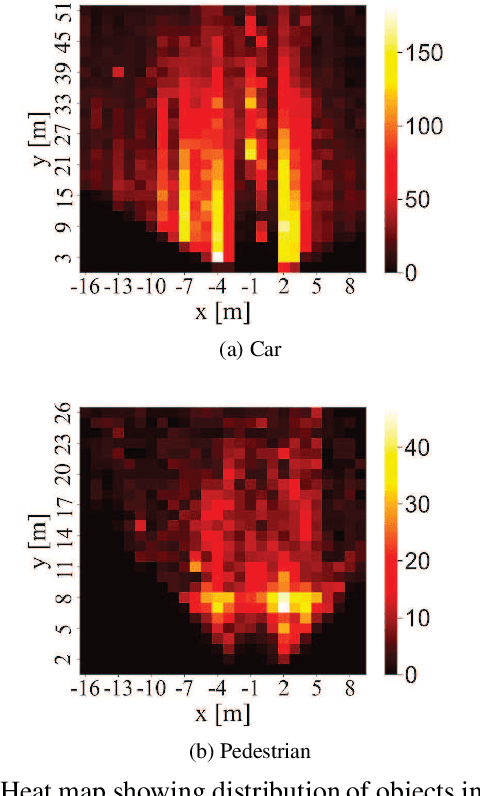
Smart monitoring using three-dimensional (3D) image sensors has been attracting attention in the context of smart cities. In smart monitoring, object detection from point cloud data acquired by 3D image sensors is implemented for detecting moving objects such as vehicles and pedestrians to ensure safety on the road. However, the features of point cloud data are diversified due to the characteristics of light detection and ranging (LIDAR) units used as 3D image sensors or the install position of the 3D image sensors. Although a variety of deep learning (DL) models for object detection from point cloud data have been studied to date, no research has considered how to use multiple DL models in accordance with the features of the point cloud data. In this work, we propose a feature-based model selection framework that creates various DL models by using multiple DL methods and by utilizing training data with pseudo incompleteness generated by two artificial techniques: sampling and noise adding. It selects the most suitable DL model for the object detection task in accordance with the features of the point cloud data acquired in the real environment. To demonstrate the effectiveness of the proposed framework, we compare the performance of multiple DL models using benchmark datasets created from the KITTI dataset and present example results of object detection obtained through a real outdoor experiment. Depending on the situation, the detection accuracy varies up to 32% between DL models, which confirms the importance of selecting an appropriate DL model according to the situation.