 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Policy Learning via Marketplace Expected Value Estimation From Observational Data
Oct 06, 2024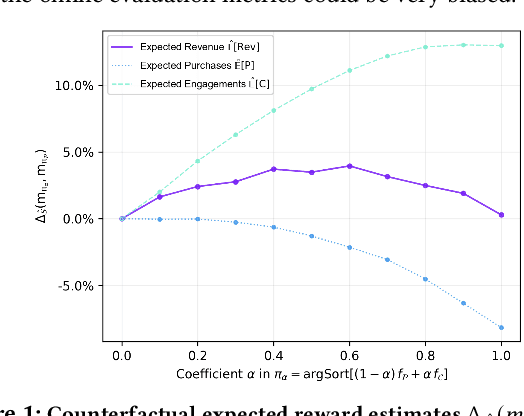

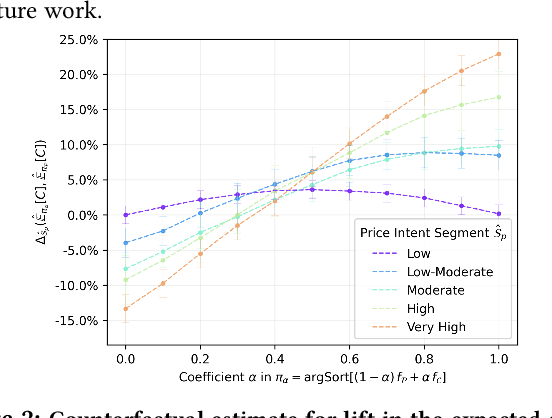
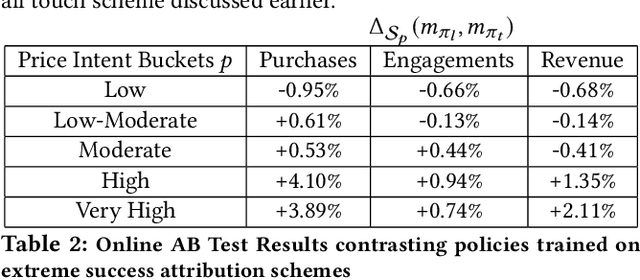
We develop a decision making framework to cast the problem of learning a ranking policy for search or recommendation engines in a two-sided e-commerce marketplace as an expected reward optimization problem using observational data. As a value allocation mechanism, the ranking policy allocates retrieved items to the designated slots so as to maximize the user utility from the slotted items, at any given stage of the shopping journey. The objective of this allocation can in turn be defined with respect to the underlying probabilistic user browsing model as the expected number of interaction events on presented items matching the user intent, given the ranking context. Through recognizing the effect of ranking as an intervention action to inform users' interactions with slotted items and the corresponding economic value of the interaction events for the marketplace, we formulate the expected reward of the marketplace as the collective value from all presented ranking actions. The key element in this formulation is a notion of context value distribution, which signifies not only the attribution of value to ranking interventions within a session but also the distribution of marketplace reward across user sessions. We build empirical estimates for the expected reward of the marketplace from observational data that account for the heterogeneity of economic value across session contexts as well as the distribution shifts in learning from observational user activity data. The ranking policy can then be trained by optimizing the empirical expected reward estimates via standard Bayesian inference techniques. We report empirical results for a product search ranking task in a major e-commerce platform demonstrating the fundamental trade-offs governed by ranking polices trained on empirical reward estimates with respect to extreme choices of the context value distribution.
Modeling Social Readers: Novel Tools for Addressing Reception from Online Book Reviews
May 07, 2021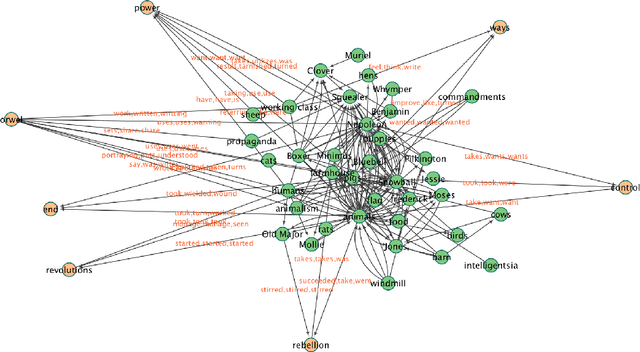
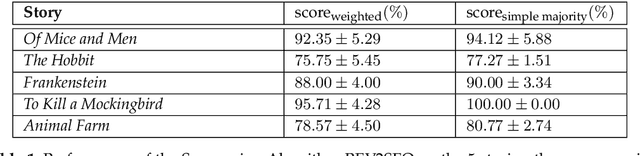
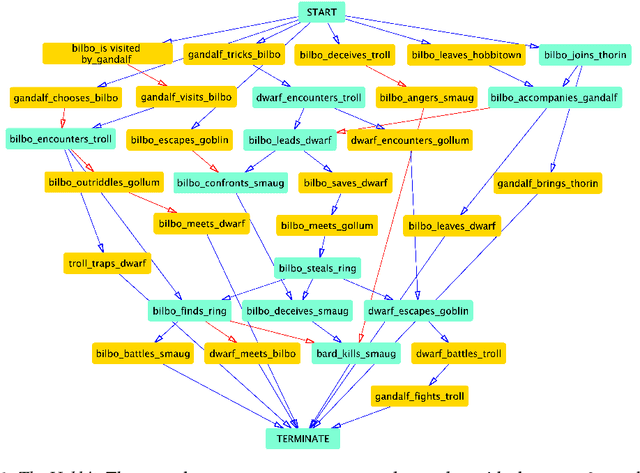
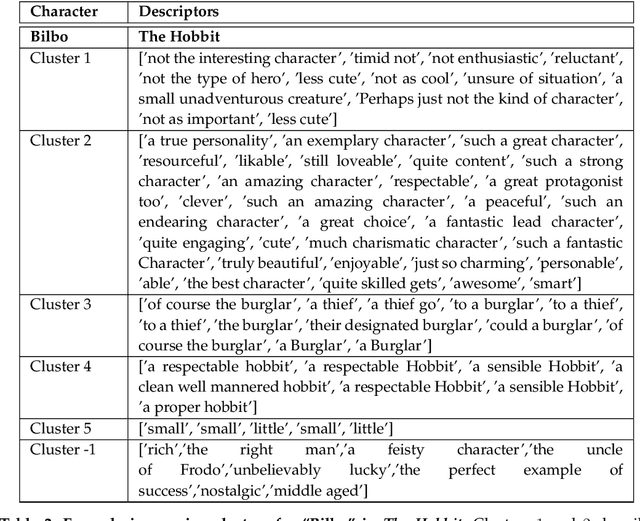
Readers' responses to literature have received scant attention in computational literary studies. The rise of social media offers an opportunity to capture a segment of these responses while data-driven analysis of these responses can provide new critical insight into how people "read". Posts discussing an individual book on Goodreads, a social media platform that hosts user discussions of popular literature, are referred to as "reviews", and consist of plot summaries, opinions, quotes, or some mixture of these. Since these reviews are written by readers, computationally modeling them allows one to discover the overall non-professional discussion space about a work, including an aggregated summary of the work's plot, an implicit ranking of the importance of events, and the readers' impressions of main characters. We develop a pipeline of interlocking computational tools to extract a representation of this reader generated shared narrative model. Using a corpus of reviews of five popular novels, we discover the readers' distillation of the main storylines in a novel, their understanding of the relative importance of characters, as well as the readers' varying impressions of these characters. In so doing, we make three important contributions to the study of infinite vocabulary networks: (i) an automatically derived narrative network that includes meta-actants; (ii) a new sequencing algorithm, REV2SEQ, that generates a consensus sequence of events based on partial trajectories aggregated from the reviews; and (iii) a new "impressions" algorithm, SENT2IMP, that provides finer, non-trivial and multi-modal insight into readers' opinions of characters.
An automated pipeline for the discovery of conspiracy and conspiracy theory narrative frameworks: Bridgegate, Pizzagate and storytelling on the web
Aug 23, 2020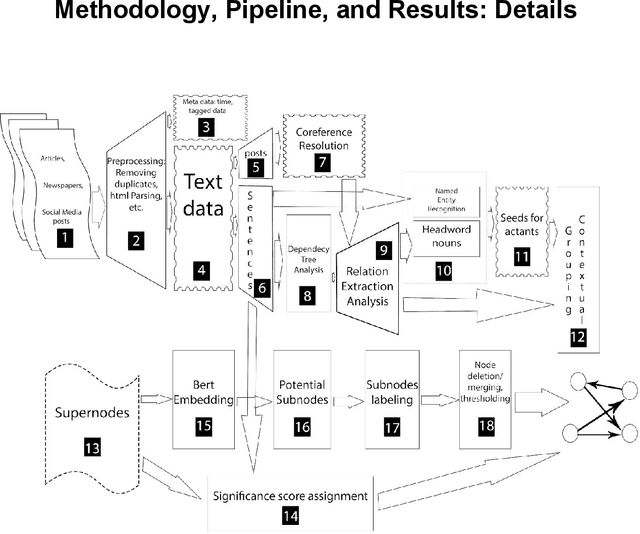
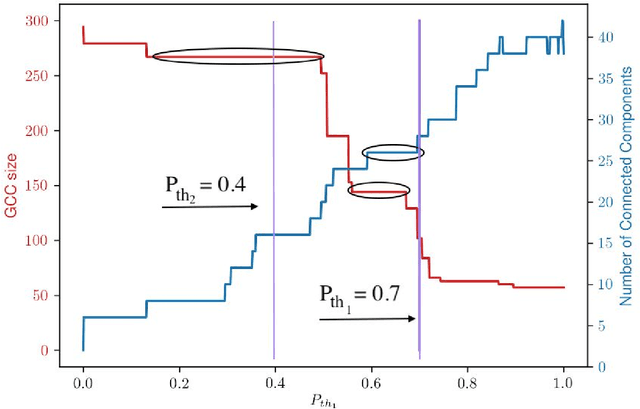
Although a great deal of attention has been paid to how conspiracy theories circulate on social media and their factual counterpart conspiracies, there has been little computational work done on describing their narrative structures. We present an automated pipeline for the discovery and description of the generative narrative frameworks of conspiracy theories on social media, and actual conspiracies reported in the news media. We base this work on two separate repositories of posts and news articles describing the well-known conspiracy theory Pizzagate from 2016, and the New Jersey conspiracy Bridgegate from 2013. We formulate a graphical generative machine learning model where nodes represent actors/actants, and multi-edges and self-loops among nodes capture context-specific relationships. Posts and news items are viewed as samples of subgraphs of the hidden narrative network. The problem of reconstructing the underlying structure is posed as a latent model estimation problem. We automatically extract and aggregate the actants and their relationships from the posts and articles. We capture context specific actants and interactant relationships by developing a system of supernodes and subnodes. We use these to construct a network, which constitutes the underlying narrative framework. We show how the Pizzagate framework relies on the conspiracy theorists' interpretation of "hidden knowledge" to link otherwise unlinked domains of human interaction, and hypothesize that this multi-domain focus is an important feature of conspiracy theories. While Pizzagate relies on the alignment of multiple domains, Bridgegate remains firmly rooted in the single domain of New Jersey politics. We hypothesize that the narrative framework of a conspiracy theory might stabilize quickly in contrast to the narrative framework of an actual one, which may develop more slowly as revelations come to light.
An Automated Pipeline for Character and Relationship Extraction from Readers' Literary Book Reviews on Goodreads.com
Apr 20, 2020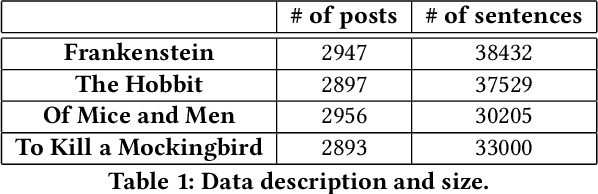
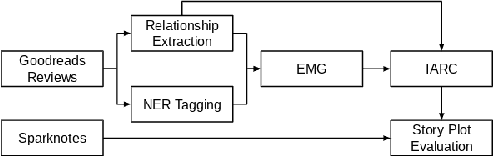
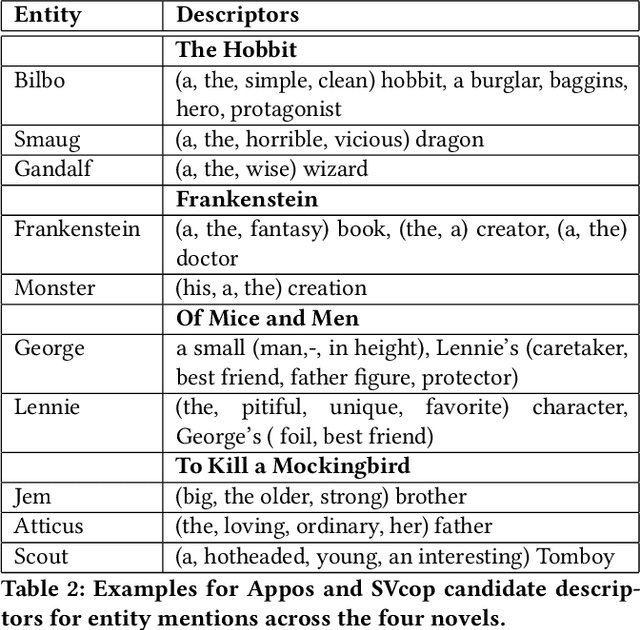
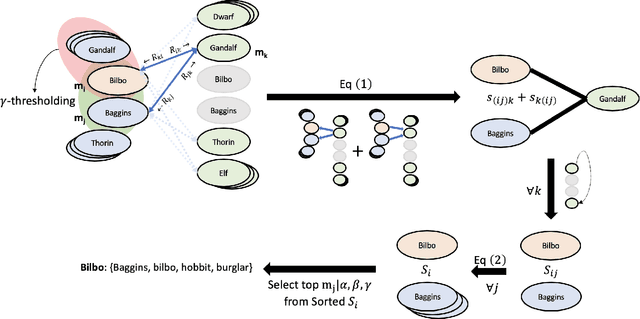
Reader reviews of literary fiction on social media, especially those in persistent, dedicated forums, create and are in turn driven by underlying narrative frameworks. In their comments about a novel, readers generally include only a subset of characters and their relationships, thus offering a limited perspective on that work. Yet in aggregate, these reviews capture an underlying narrative framework comprised of different actants (people, places, things), their roles, and interactions that we label the "consensus narrative framework". We represent this framework in the form of an actant-relationship story graph. Extracting this graph is a challenging computational problem, which we pose as a latent graphical model estimation problem. Posts and reviews are viewed as samples of sub graphs/networks of the hidden narrative framework. Inspired by the qualitative narrative theory of Greimas, we formulate a graphical generative Machine Learning (ML) model where nodes represent actants, and multi-edges and self-loops among nodes capture context-specific relationships. We develop a pipeline of interlocking automated methods to extract key actants and their relationships, and apply it to thousands of reviews and comments posted on Goodreads.com. We manually derive the ground truth narrative framework from SparkNotes, and then use word embedding tools to compare relationships in ground truth networks with our extracted networks. We find that our automated methodology generates highly accurate consensus narrative frameworks: for our four target novels, with approximately 2900 reviews per novel, we report average coverage/recall of important relationships of > 80% and an average edge detection rate of >89\%. These extracted narrative frameworks can generate insight into how people (or classes of people) read and how they recount what they have read to others.