 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Social Readers: Novel Tools for Addressing Reception from Online Book Reviews
Paper and Code
May 07, 2021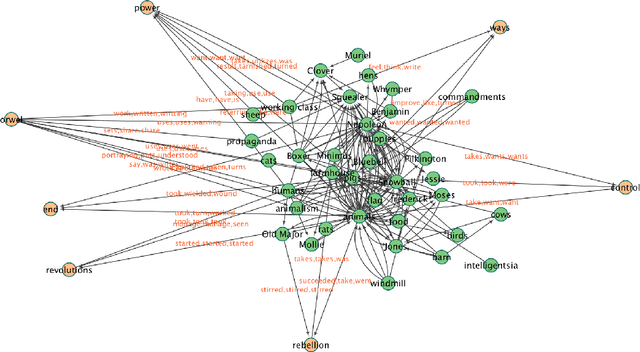
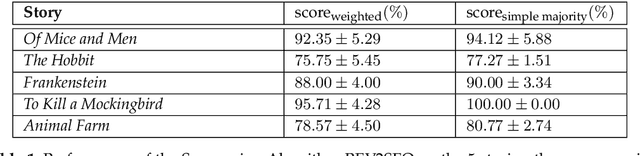
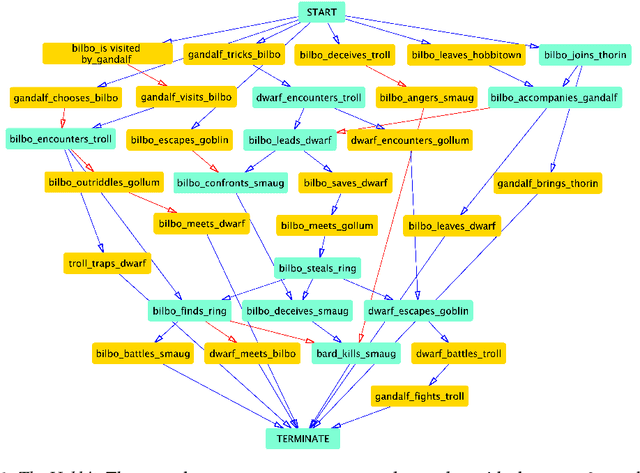
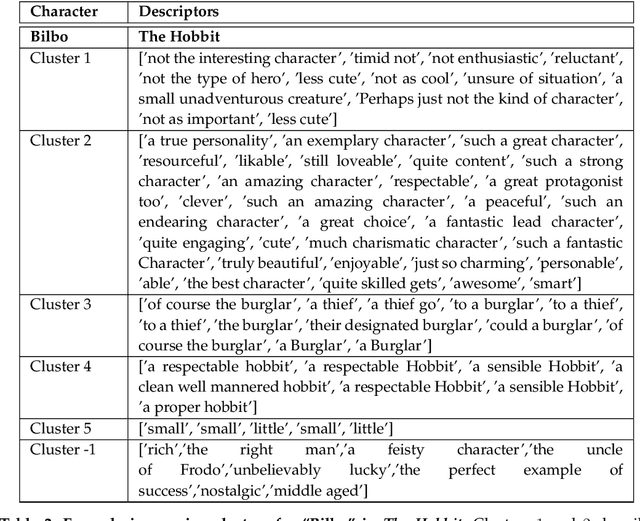
Readers' responses to literature have received scant attention in computational literary studies. The rise of social media offers an opportunity to capture a segment of these responses while data-driven analysis of these responses can provide new critical insight into how people "read". Posts discussing an individual book on Goodreads, a social media platform that hosts user discussions of popular literature, are referred to as "reviews", and consist of plot summaries, opinions, quotes, or some mixture of these. Since these reviews are written by readers, computationally modeling them allows one to discover the overall non-professional discussion space about a work, including an aggregated summary of the work's plot, an implicit ranking of the importance of events, and the readers' impressions of main characters. We develop a pipeline of interlocking computational tools to extract a representation of this reader generated shared narrative model. Using a corpus of reviews of five popular novels, we discover the readers' distillation of the main storylines in a novel, their understanding of the relative importance of characters, as well as the readers' varying impressions of these characters. In so doing, we make three important contributions to the study of infinite vocabulary networks: (i) an automatically derived narrative network that includes meta-actants; (ii) a new sequencing algorithm, REV2SEQ, that generates a consensus sequence of events based on partial trajectories aggregated from the reviews; and (iii) a new "impressions" algorithm, SENT2IMP, that provides finer, non-trivial and multi-modal insight into readers' opinions of characters.