 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Cost Outdoor Air Quality Monitoring and In-Field Sensor Calibration
Feb 05, 2020
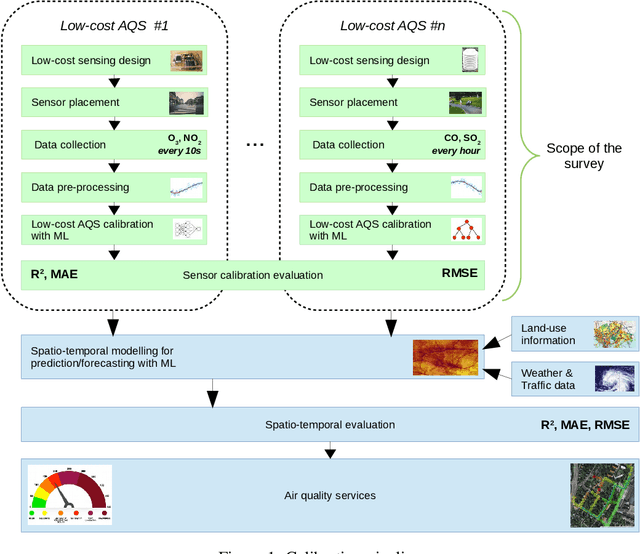
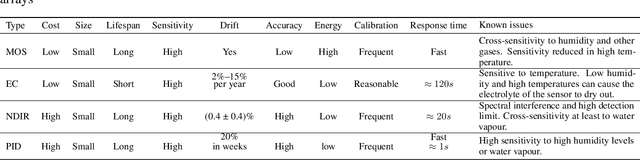
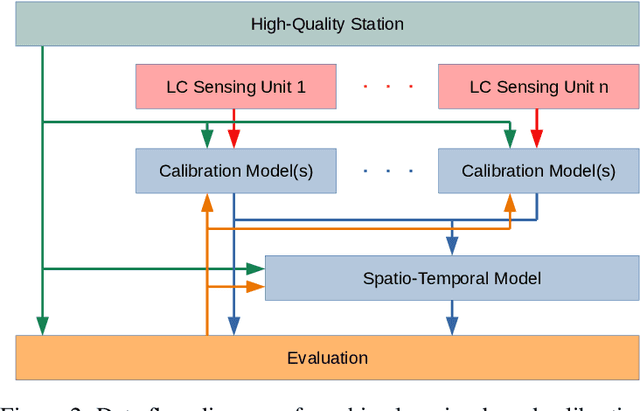
The significance of air pollution and problems associated with it is fueling deployments of air quality monitoring stations worldwide. The most common approach for air quality monitoring is to rely on environmental monitoring stations, which unfortunately are very expensive both to acquire and to maintain. Hence, environmental monitoring stations typically are deployed sparsely, resulting in limited spatial resolution for measurements. Recently, low-cost air quality sensors have emerged as an alternative that can improve granularity of monitoring. The use of low-cost air quality sensors, however, presents several challenges: they suffer from cross-sensitivities between different ambient pollutants; they can be affected by external factors such as traffic, weather changes, and human behavior; and their accuracy degrades over time. The accuracy of low-cost sensors can be improved through periodic re-calibration with particularly machine learning based calibration having shown great promise due to its capability to calibrate sensors in-field. In this article, we survey the rapidly growing research landscape of low-cost sensor technologies for air quality monitoring, and their calibration using machine learning techniques. We also identify open research challenges and present directions for future research.
Privacy-preserving data sharing via probabilistic modelling
Jan 29, 2020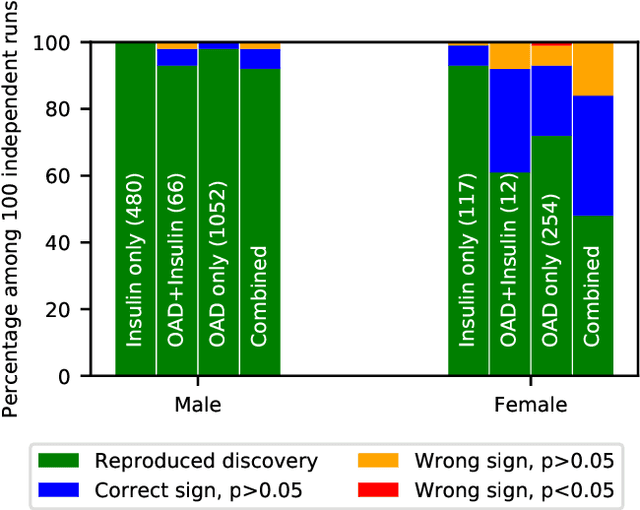
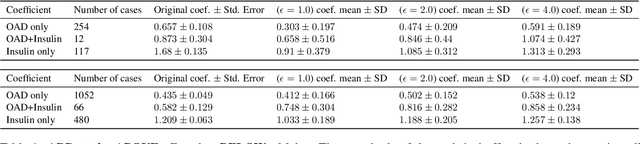
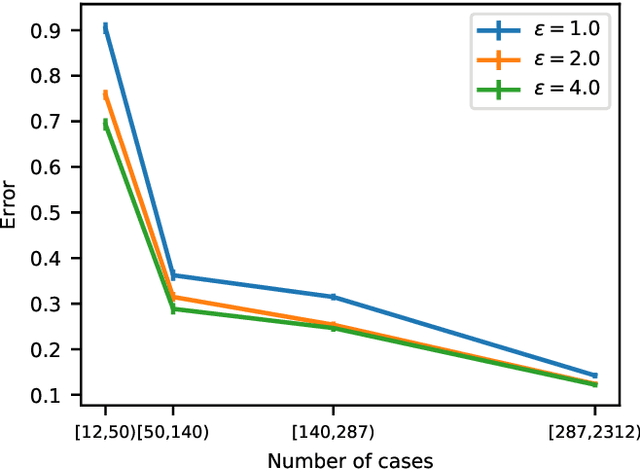

Differential privacy allows quantifying privacy loss from computations on sensitive personal data. This loss grows with the number of accesses to the data, making it hard to open the use of such data while respecting privacy. To avoid this limitation, we propose privacy-preserving release of a synthetic version of a data set, which can be used for an unlimited number of analyses with any methods, without affecting the privacy guarantees. The synthetic data generation is based on differentially private learning of a generative probabilistic model which can capture the probability distribution of the original data. We demonstrate empirically that we can reliably reproduce statistical discoveries from the synthetic data. We expect the method to have broad use in sharing anonymized versions of key data sets for research.
Differentially Private Bayesian Learning on Distributed Data
May 29, 2017

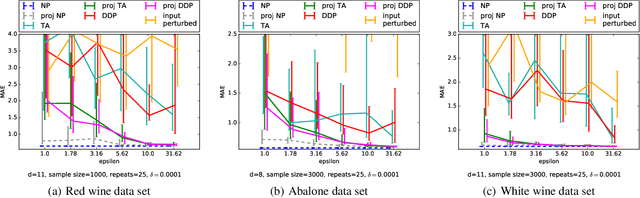

Many applications of machine learning, for example in health care, would benefit from methods that can guarantee privacy of data subjects. Differential privacy (DP) has become established as a standard for protecting learning results. The standard DP algorithms require a single trusted party to have access to the entire data, which is a clear weakness. We consider DP Bayesian learning in a distributed setting, where each party only holds a single sample or a few samples of the data. We propose a learning strategy based on a secure multi-party sum function for aggregating summaries from data holders and the Gaussian mechanism for DP. Our method builds on an asymptotically optimal and practically efficient DP Bayesian inference with rapidly diminishing extra cost.